



Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Dernière mise à jour :
June 26, 2026
5 minutes
In 2026, document fraud has a new face: the document deepfake, a fake generated entirely by AI. According to Shufti's Identity Fraud Index 2026, it's the fastest-growing fraud category, with an annualized increase estimated at nearly 3,900%. What sets these fakes apart: they're clean on the surface. Here's how to detect the ones still slipping past your checks.
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
.webp)
In 2026, document deepfakes (AI-generated fakes) are surging and slipping past classic checks: a re-scanned or fully regenerated fake carries clean metadata. The key to catching them is no longer the file but the internal coherence of the content: amounts, dates and identities that don't add up. This layer recovers 20 to 30% more fraud. Reliable detection combines three layers (visual analysis, metadata, semantic coherence), which Koncile brings together in a single platform, with 99.8% extraction reliability and hosting in France.
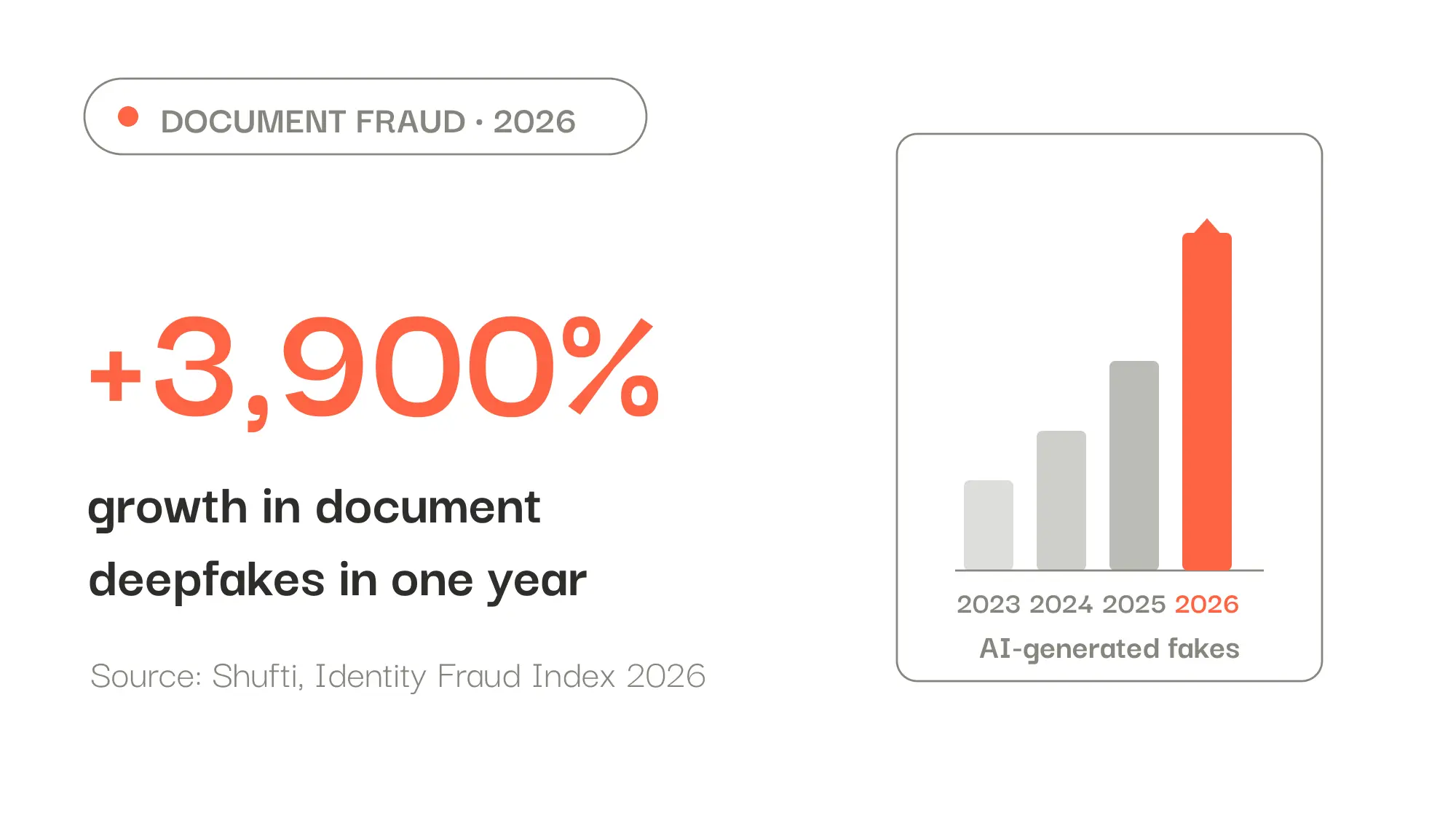
For years, catching a fake document was a forensics problem: spotting cloned pixels, splicing artifacts, altered metadata. In 2026, that model is breaking down with the rise of document deepfakes, fakes generated entirely by AI. According to Shufti's Identity Fraud Index 2026, this is the fastest-growing fraud category, with an annualized increase estimated at nearly 3,900%. ISACA reports the case of an auditor who discovers a document produced by AI, complete with a synthetic signature and perfectly consistent metadata. The takeaway: you can no longer assume the quality of evidence from the file itself.
The problem for your teams is concrete. The controls that long sufficed examine how the file was made: its metadata, its pixel-level edits. But a document deepfake, or a fake printed then re-scanned, leaves nothing to analyze on that side. Here's what actually works to detect them, and how to choose a document fraud detection solution that catches them.
Classic detection looks at how the file was built: the PDF editor, the modification history, font consistency, the traces left by Photoshop, Canva, iLovePDF or a word processor. These detection methods still help when a fraudster tampers with an existing document. The problem is that it has become easy to leave no trace at all.
In all three cases, the envelope is clean. What's left is to read what's inside. For the file-level clues, see our article on the hidden signals in metadata.
A falsified document almost always leaves logical inconsistencies its author couldn't fully fix. Faking a payslip convincingly means recomputing every figure to the cent, redoing the totals and adjusting the contributions. That's rarely carried all the way through. Semantic coherence analysis starts there: it checks that the document's information holds together, and that it holds with the other documents in the file.
In our field experience, this coherence layer recovers 20 to 30% of the fraud that visual analysis, metadata and pixels, lets through. The stakes aren't marginal: a mutual insurer told us that fraud accounts for 1 to 2% of its revenue, several million euros a year.
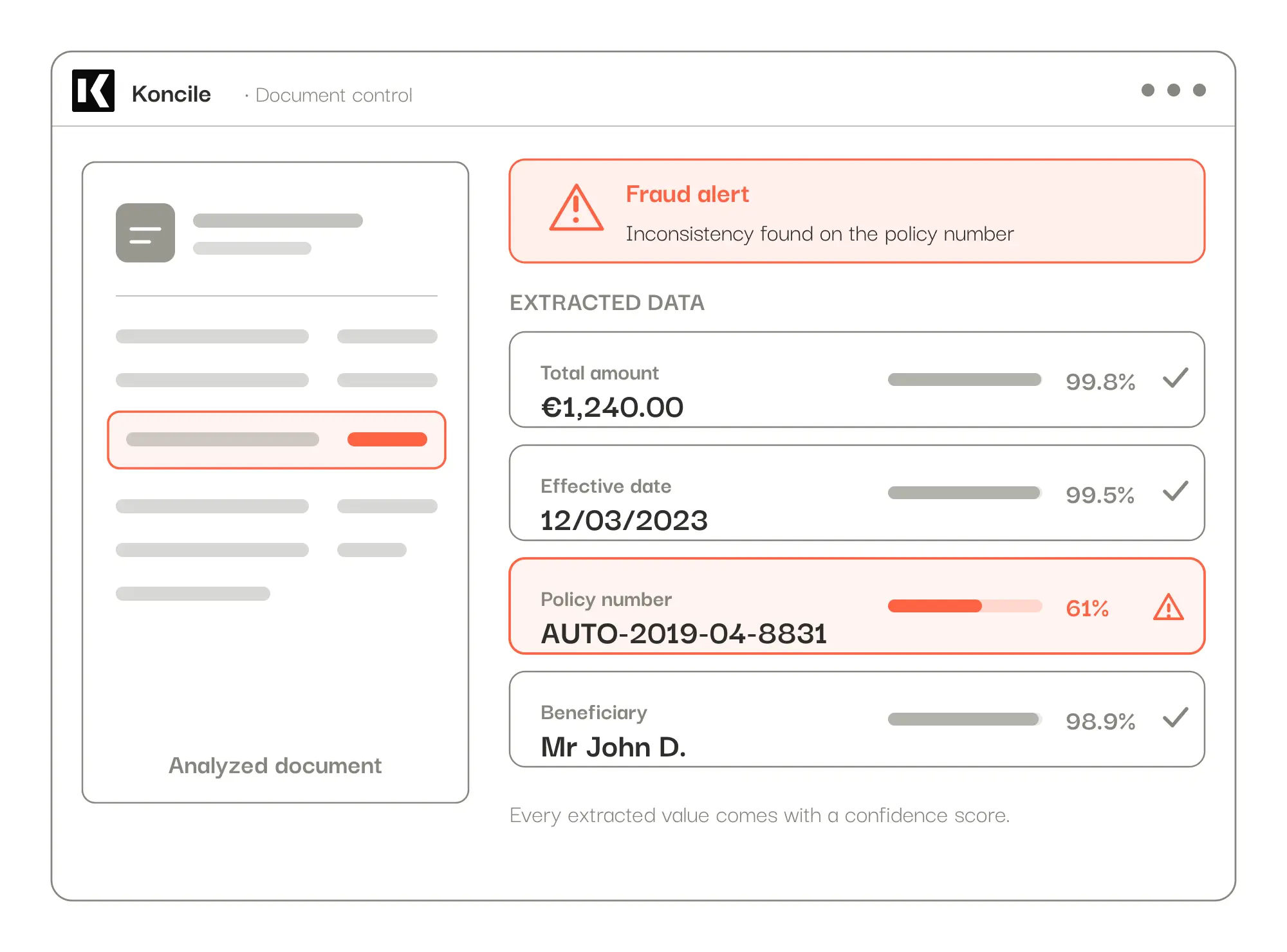
Insurance no-claims certificate. At an insurance player we work with, fake certificates give themselves away through precise inconsistencies: a no-claims bonus that doesn't match the history, a policy number encoding a date different from the stated effective date, an email that doesn't match the policyholder's name and postcode, or a driver different from the policyholder. Some fakes are even regenerated from scratch by the fraudster: no edit to spot, only cross-checks that don't add up.

Payslip. You recompute the totals. When the document has been tampered with, the figures never quite add up.
Bank statement. You compare the statement to a known template from the same bank and check the internal consistency of the transactions; bank statement extraction feeds these checks.
Invoice. You reconcile the line items, totals and vendor: that's often where invoice fraud shows up before payment.
Across several documents. Fraud isn't always in a single document. A health insurer described services billed wrongly: a policyholder hospitalized who, over the same period, submits physiotherapy sessions. The inconsistency reads across documents, not within one.
Coherence doesn't replace metadata: it complements it. Relying on a single layer produces costly false positives. A real example: a perfectly authentic document had been produced with a software library also used to make fakes. Banning it on that criterion alone meant blocking legitimate files. It's the content analysis that settles these ambiguous cases.
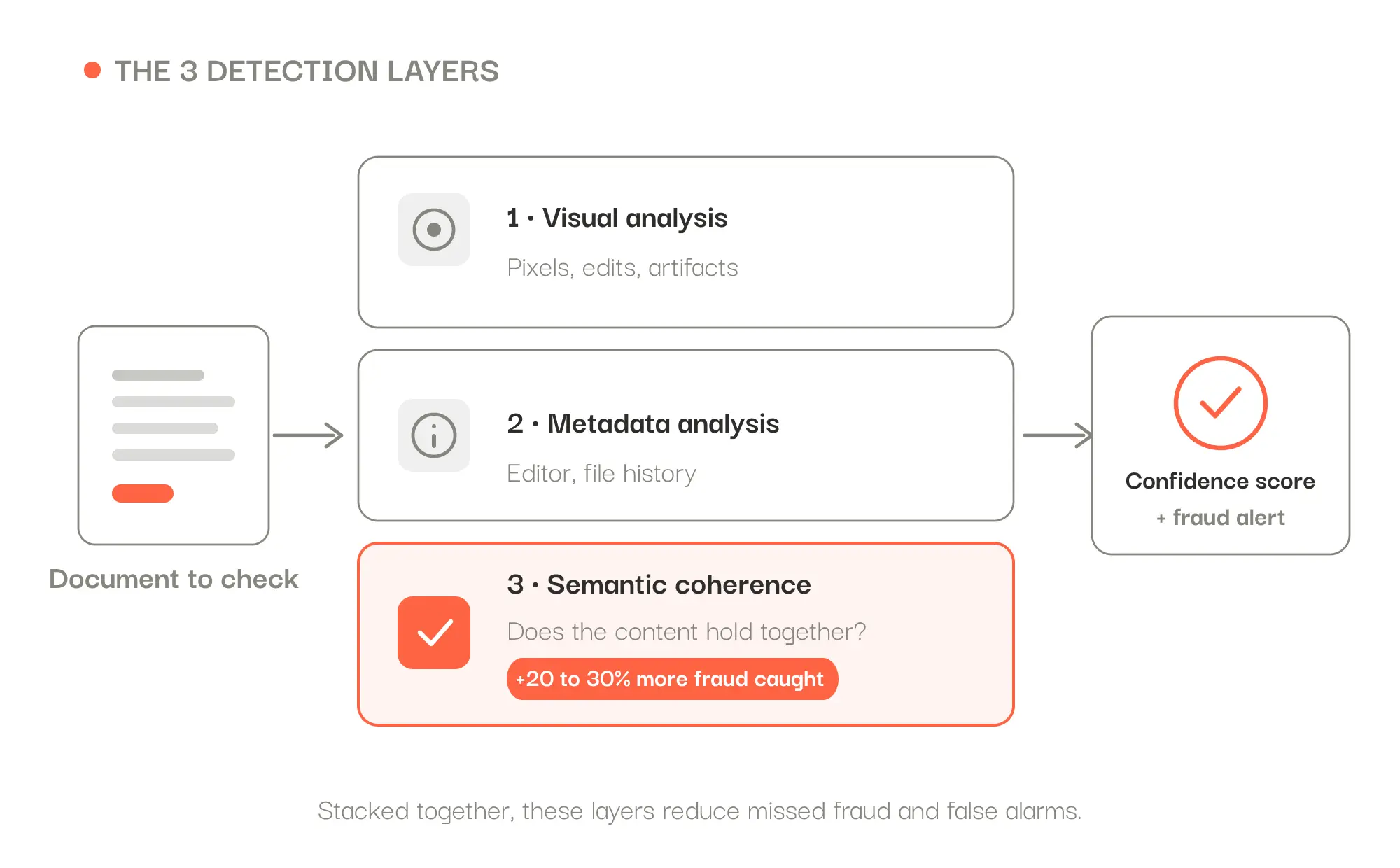
The right approach therefore stacks three layers: visual analysis (pixels, edits), metadata analysis (editor, history) and semantic coherence analysis of the content. Together, they reduce both missed fraud and false alarms.
For a compliance, anti-fraud or KYC onboarding team, two things matter.
First, freeing up time. By attaching a confidence score to every extracted value, you only review what needs reviewing. At our clients, that means roughly 90% less review time, with people focused on the risky cases.
Second, choosing the right tool. In 2026, a simple metadata score is no longer enough. Three questions to ask before signing:
Regulation points the same way. Article 50 of the EU AI Act, in force from August 2026, requires marking AI-generated content. Traceability of the decision becomes a compliance matter, not just an efficiency one.
Koncile brings the three layers together in a single platform: computer vision for visual analysis, metadata analysis and semantic coherence analysis of the content. Where many approaches stop at metadata, we also read what the document says and check that everything holds together. It's the core of our document fraud detection approach.
In practice, our AI OCR structures the data and you set up your checks in natural language, no code, so they fit your documents and your business rules. Every extracted value comes with a confidence score. On extracted data, our internal benchmark, re-run at each update, measures 99.8% reliability. That figure covers data extraction, separate from fraud detection, which we keep enriching. Processing runs from a few seconds to about thirty seconds per document, fully parallelized.
Upstream, Koncile separates multi-page bundles with document splitting, so the pieces of a single file don't get mixed up.
On security, Koncile is SOC 2 Type II and ISO 27001 certified, GDPR compliant, with hosting in France. Results plug into your systems through our OCR API.
Want to see how Koncile analyzes the coherence of your documents and catches the fakes still slipping past your checks? Book a demo.
Yes. Beyond metadata and pixel analysis, Koncile checks the internal coherence of the content: amounts, dates, identities and cross-checks between the documents in a file. That's what catches fakes regenerated by AI or printed then re-scanned, whose metadata is clean.
By combining several analysis layers rather than a single signal, and attaching a confidence score to every result. Checks are tuned per use case to fit your documents, so legitimate files aren't blocked.
The most falsified ones: payslips, tax notices, bank statements, invoices and insurance no-claims certificates. The rules adapt to other documents depending on your business.
Yes. Koncile is hosted in France, GDPR compliant and certified SOC 2 Type II and ISO 27001. Your documents are not used to train the models.
Yes. You describe your checks in natural language, no code, and Koncile applies them to your document types and business rules, with an audit trail on every decision.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives

Five French OCR solutions compared for extracting your document data with full GDPR compliance, hosted on servers in France.
Comparatives
.png)


