


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
June 15, 2026
5 minutes
Modern document fraud is rarely obvious. It does not rely on crude forgeries anymore, but on documents that look legitimate, read correctly, and pass basic checks. Detecting fraud today is less about spotting errors, and more about identifying subtle technical signals that reveal inconsistencies, manipulation, or implausible trajectories. This article focuses on those weak but scalable signals, and on why combining them into a probabilistic score matters more than searching for a single proof.
How weak technical signals reveal document fraud risks.

Document fraud detection is often approached as a binary question: is this document fake or real. In practice, this mindset fails quickly. Most fraudulent documents are not fully fake. They are partially altered, reused in the wrong context, or manipulated just enough to remain plausible.
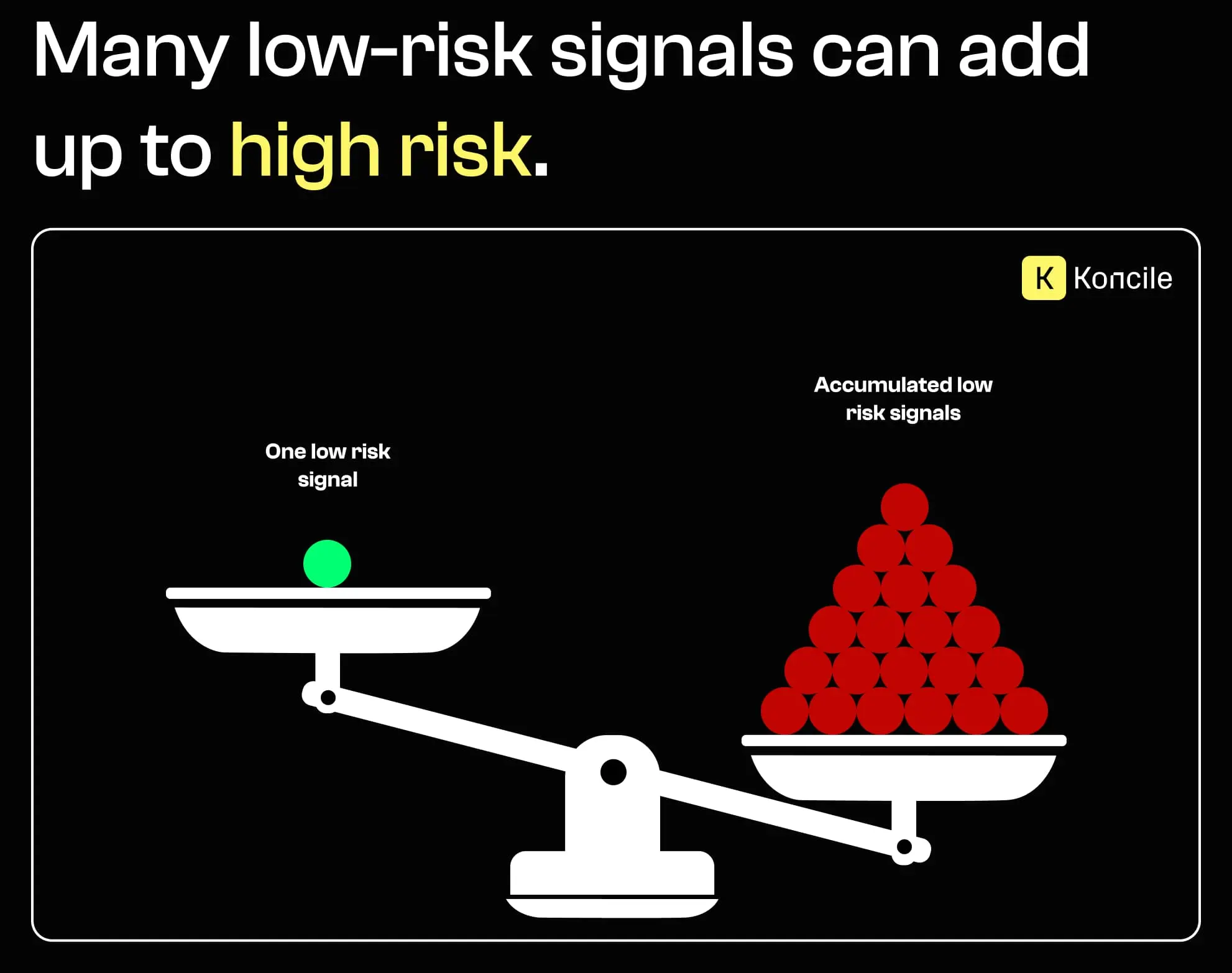
A more effective approach is to treat fraud detection as a scoring problem. Each signal slightly increases or decreases the overall risk. No single test is decisive on its own, but their accumulation creates a meaningful confidence level.
This is especially important at scale, where thousands of documents must be processed automatically and consistently.
PDF metadata is often ignored or treated as unreliable. Yet, when used carefully, it provides some of the most scalable and low-cost signals available.
Another often overlooked metadata field is the PDF version itself.While this information rarely raises suspicion on its own, it becomes meaningful when compared with the document’s supposed age and origin. A document presented as recent but generated using an outdated PDF version can indicate the use of obsolete tools, unofficial pipelines, or manual re-exporting. As with other metadata, the signal is weak in isolation, but it helps assess whether the document’s technical context actually makes sense, especially when evaluated against its document structure and the expectations tied to its origin.
PDF files store technical timestamps, including the moment they were created and the last time they were modified. It is entirely possible to alter visible content in a PDF without leaving any visual trace. A date, an amount, or a name can be changed manually, while the document still looks authentic.
Metadata tells a different story. When a document shows a significant gap between its creation date and its modification date, it raises questions.
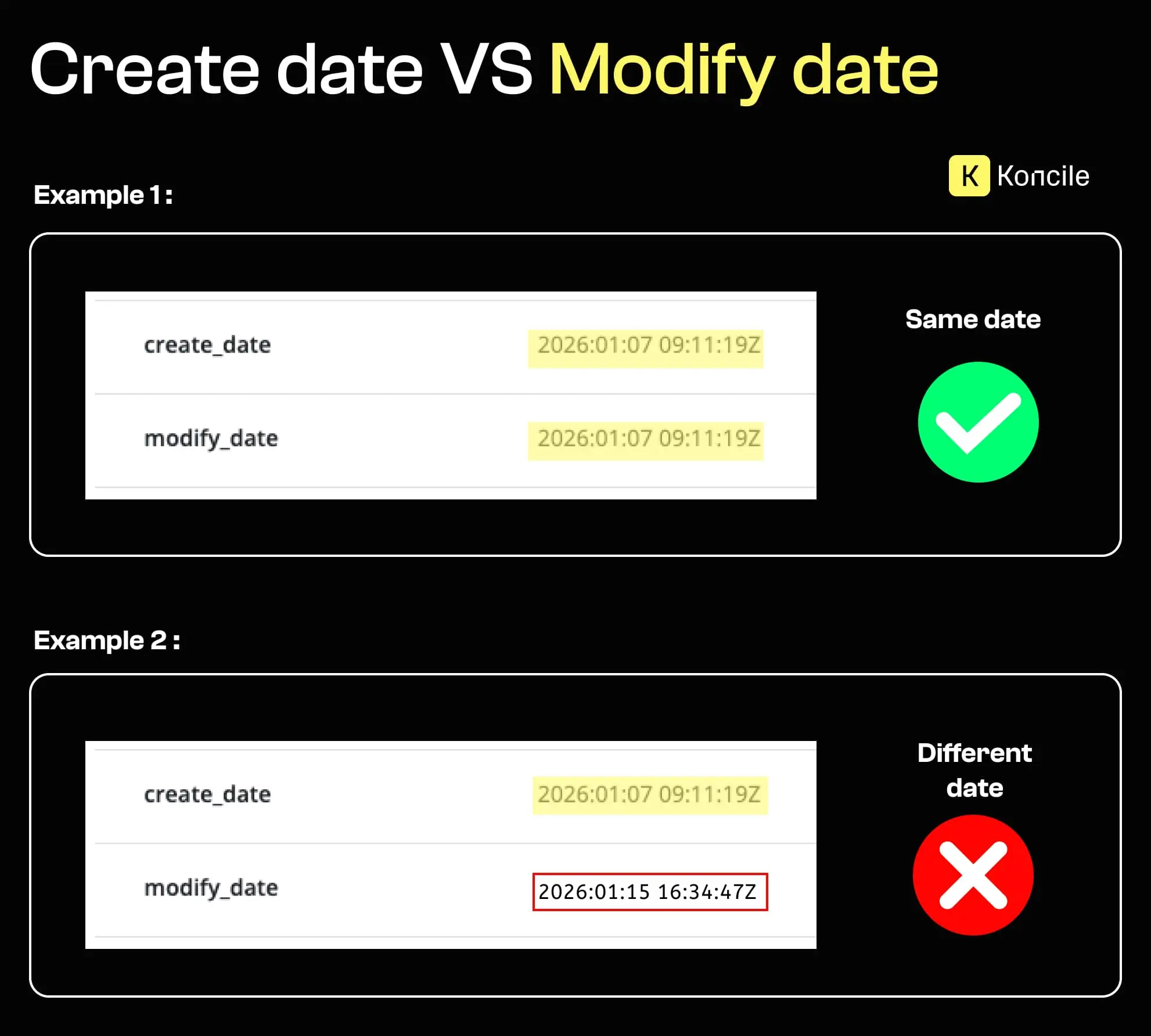
The signal itself is weak. Many legitimate documents are modified after creation. What matters is the context: how long after creation the modification occurred, what type of document it is, and whether such edits are expected in a normal workflow.
Why ModDate alone is not enoughA late modification does not mean fraud by default. Without interpretation, it creates noise and false positives. What makes the signal valuable is its combination with other factors: document type, semantic impact of the edit, and consistency with expected timelines.
Some metadata fields are almost never present in legitimate business or administrative documents. Embedded JavaScript is one of them. While PDF supports scripting for advanced use cases, its presence is rare in standard document workflows. When detected, it often signals non-standard behavior such as automation, dynamic manipulation, or attempts to alter how the document behaves when opened. Because of its rarity, this field typically carries a higher risk weight than more common metadata indicators.
Every PDF contains information about the software that generated it. This includes the Creator and Producer fields. These values often reveal whether a document was generated automatically by a system, or manually edited using consumer tools.
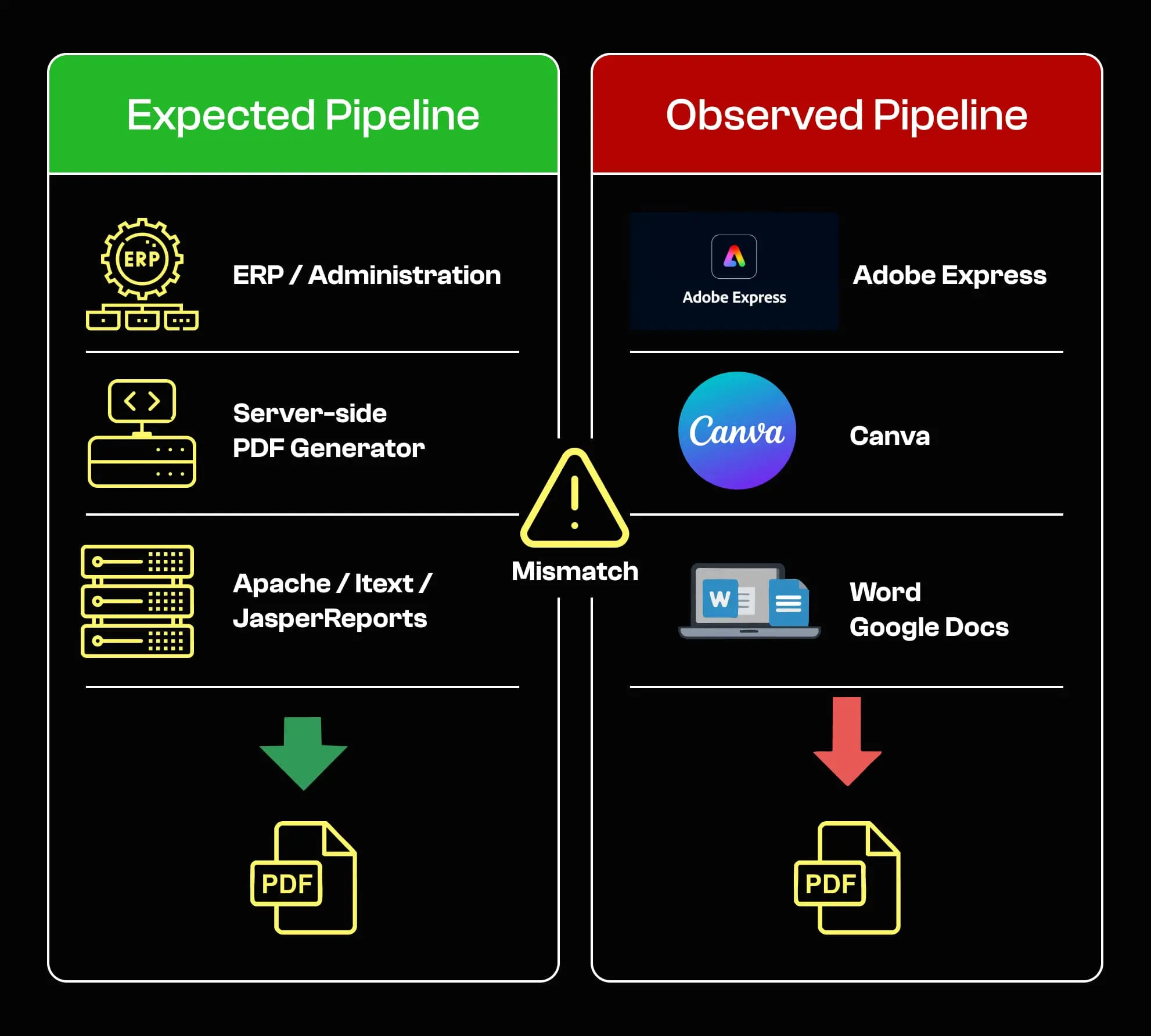
On practice, Creator and Producer metadata often reveals whether a document was generated automatically or manually edited. PDFs produced by server-side or industrial tools such as reporting engines, ERP systems, or form generators typically include creators like Apache-based generators, iText server libraries, JasperReports, or Adobe LiveCycle.
These tools are commonly used by administrations and enterprises to generate documents at scale, with limited human intervention. By contrast, documents showing creators such as Adobe Express, Canva, Microsoft Word, Google Docs, or PowerPoint often indicate manual editing.
This does not imply fraud by itself, but it becomes a strong risk signal when such tools are used for documents that are normally generated automatically, such as official certificates, contracts, or administrative records. This is precisely the kind of contextual, multi-signal reasoning that distinguishes a heuristic approach from true intelligent document processing focused on risk."
For example:
1 – This document was generated using Adobe Express, as indicated by its Creator metadata.
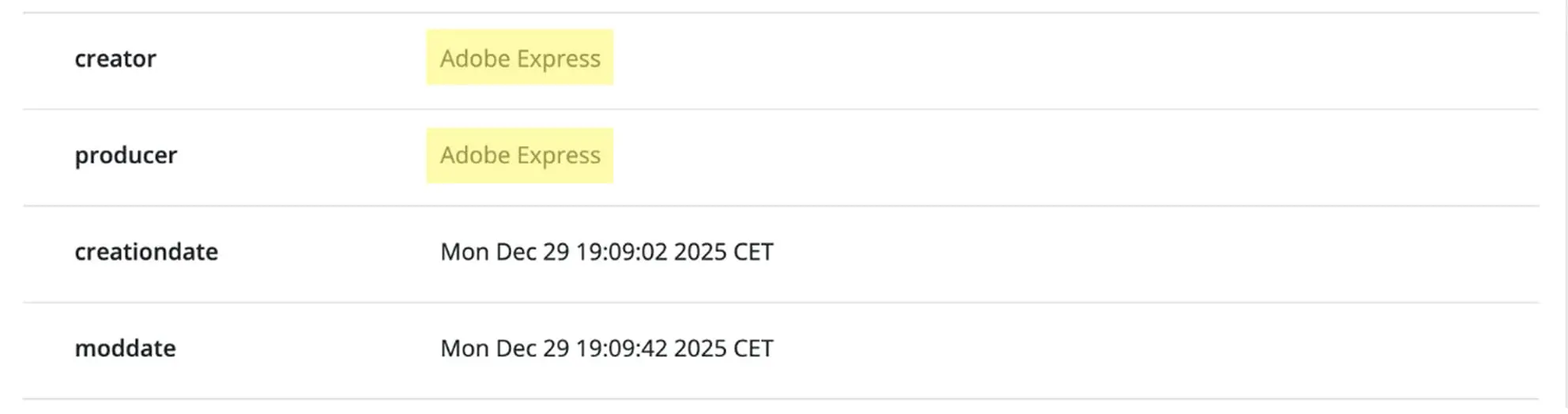
2 – The original version of this document was generated by an Apache-based PDF engine, before being reopened and modified using an editing tool. You can also see that the CreationDate was altered accordingly.

A marketing brochure generated in Canva is perfectly normal. A government certificate generated in Canva is not. The same tool can be harmless in one context and highly suspicious in another.
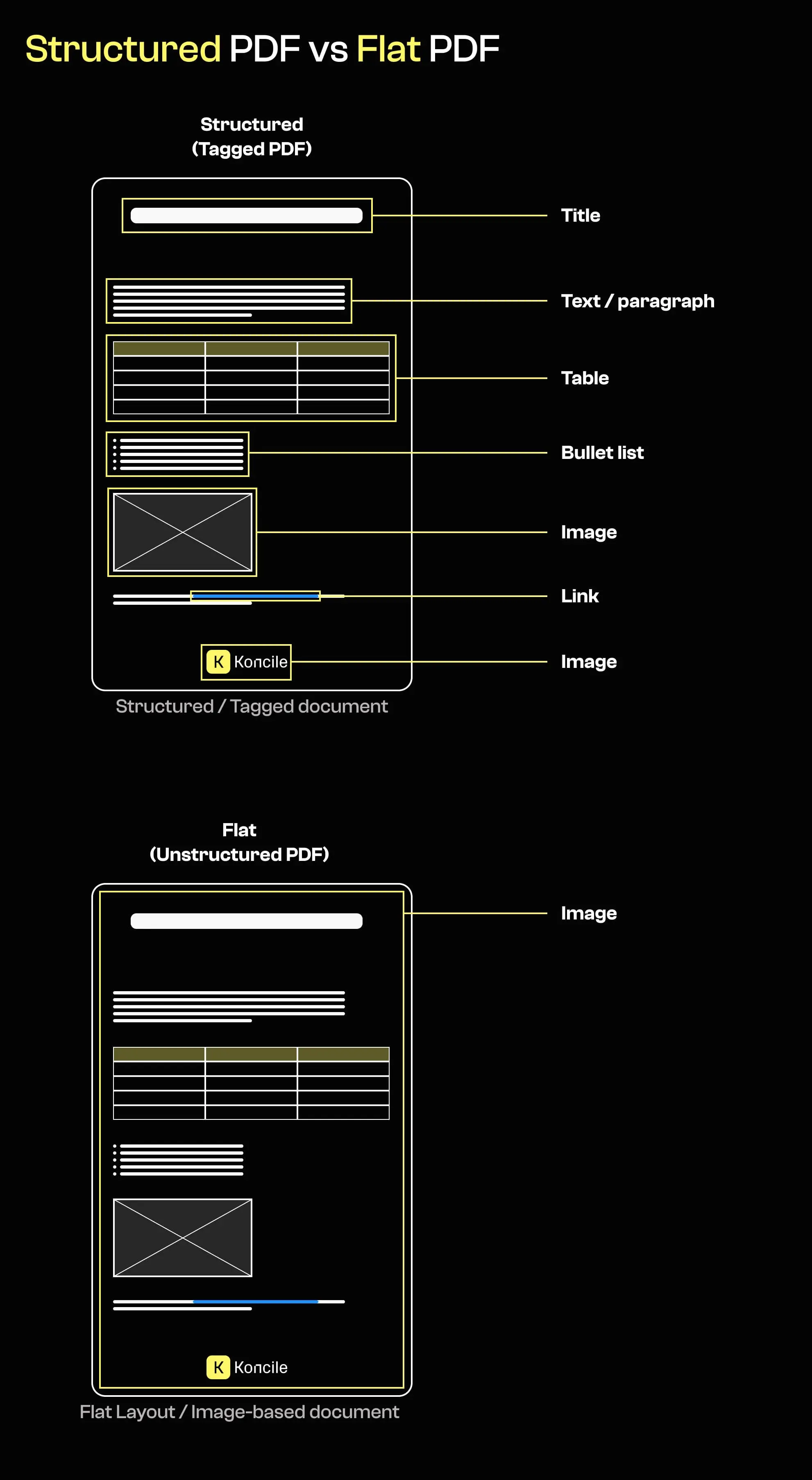
Beyond the software used to generate a PDF, its internal structure provides important clues about its origin. Many official or regulated documents are produced using structured templates that contain identifiable text objects, logical hierarchies, and sometimes semantic tagging.
By contrast, documents exported as flat layouts or images often lack this internal structure. They may consist of a single full-page image per page, occasionally augmented with an OCR text layer added after the fact.
The absence of structure does not prove manipulation on its own. However, it can indicate that the document was generated or transformed using tools or pipelines that differ from those normally associated with its supposed origin.
A document should not only be evaluated based on how it looks, but on whether the way it was produced makes sense for what it claims to be.
Signals related to document structure often align with other technical traces that reveal how a file was produced. Metadata can, for instance, expose clues about the document’s origin through elements such as color profiles.
ICC color profiles are commonly introduced by scanners, printers, or image-processing pipelines. When a document presented as natively digital contains metadata typically associated with scanned images, it raises questions about how it was actually produced.
This type of signal is subtle and rarely meaningful on its own. But when combined with a flat document structure or the absence of semantic tagging, it helps distinguish genuinely digital documents from scans presented as originals.

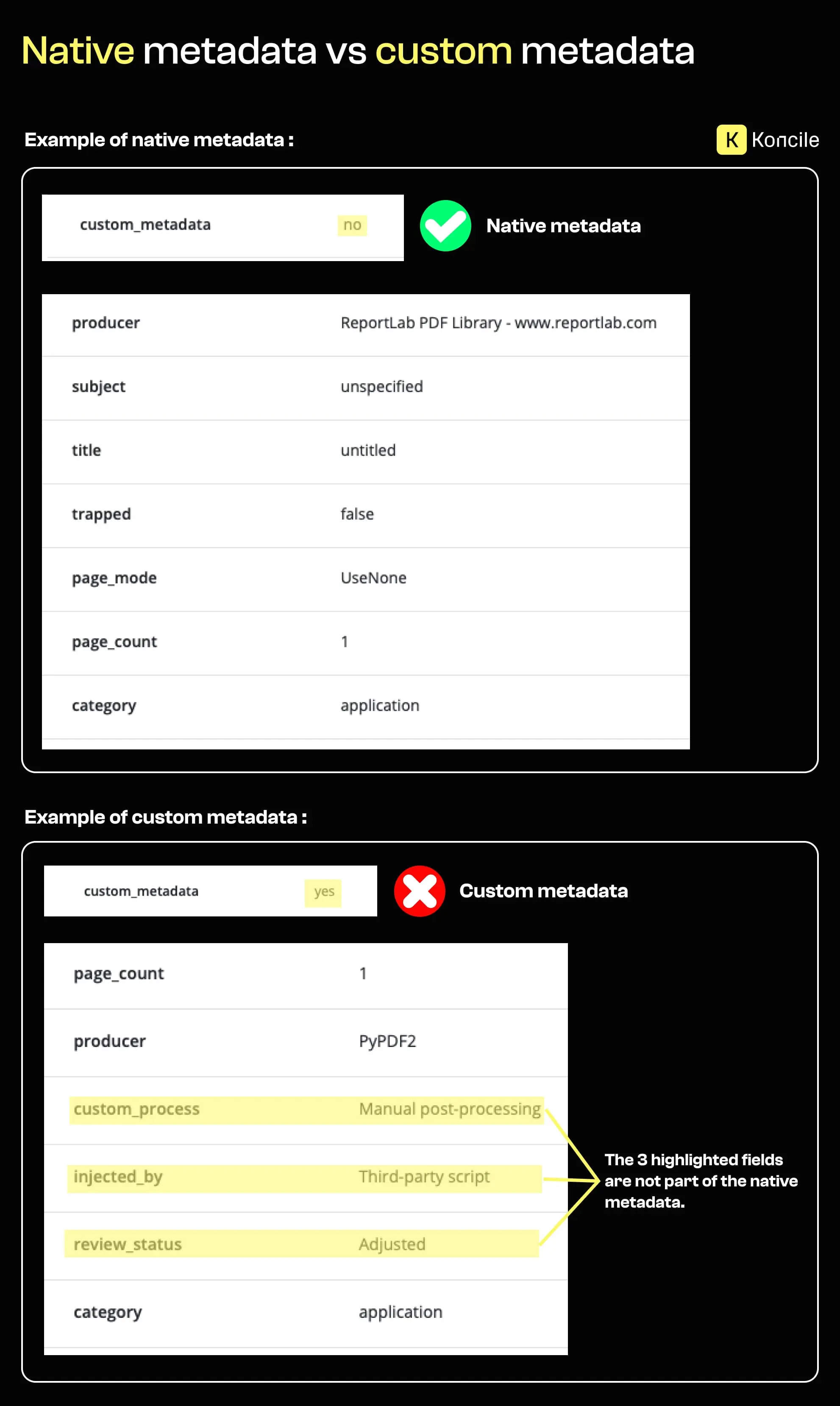
Some PDFs contain custom metadata fields that were added after the initial document generation. These fields often appear when scripts, third-party tools, or manual processes inject additional information into the file.
In official or regulated documents, custom metadata is relatively rare. Its presence does not prove manipulation, but it indicates that the document went through a non-standard production or transformation process.
At scale, recurring custom metadata patterns across similar documents can reveal industrialized manipulation rather than isolated or legitimate edits.
Not every technical idea that sounds rigorous actually helps detect fraud. Some approaches are intuitive, popular, and ultimately misleading.
File hashes are often suggested as a way to detect tampering. A hash uniquely represents a file. If the file changes, the hash changes.
This is true, but also trivial. Any modification, legitimate or not, produces a new hash. Hashes only tell whether two files are strictly identical. They say nothing about whether a document is credible, consistent, or fraudulent.
Hashes are useful for deduplication and file integrity checks. They are not fraud detection signals.
Forensic analysis tools allow deep inspection of file structures, binary differences, and historical traces. They are invaluable for investigations and legal expertise.
However, they are slow, complex, and require human intervention. They are designed to explain what happened after suspicion arises, not to detect risk across thousands of documents automatically.
The real challenge: detecting meaningful changes
The critical distinction in document fraud detection is not whether a file changed, but whether the change matters. Adding an annotation or correcting a typo is not equivalent to modifying a monetary amount, a date, or an identity.
Semantic changes alter the meaning or legal impact of a document. Cosmetic changes do not. Effective systems must differentiate between the two and assign risk accordingly.
This requires combining technical signals with document understanding, rather than relying on file-level checks alone.
Fraud rarely exists in isolation. A single document may appear legitimate, but patterns emerge when documents are compared over time or across users.
Repeated similarities, micro-variations, improbable timelines, or reused structures can all indicate organized manipulation. Contextual analysis transforms isolated weak signals into strong evidence.
For a broader overview of document fraud strategies and prevention methods, see our existing guide on document fraud detection on the Koncile website.
Document fraud detection is shifting away from binary rules and visible errors. The most effective fraud detection system focuses on weak technical signals, contextual coherence, and explainable scoring. Metadata, production tools, and subtle inconsistencies are often overlooked, yet they provide valuable insight when combined intelligently. As document generation becomes easier and more automated, detecting fraud will depend less on strict rules and more on understanding what is plausible. To compare the tools available, explore our roundup of the leading document fraud detection software.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


