


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Letzte Aktualisierung:
June 15, 2026
5 Minuten
Moderner Dokumentenbetrug ist selten offensichtlich. Er basiert nicht mehr auf groben Fälschungen, sondern auf Dokumenten, die glaubwürdig aussehen, korrekt lesbar sind und grundlegende Prüfungen bestehen. Betrug zu erkennen bedeutet heute weniger, Fehler zu finden, sondern vielmehr subtile technische Signale zu identifizieren, die auf Inkonsistenzen, Manipulationen oder unplausible Entstehungswege hinweisen. Dieser Artikel konzentriert sich auf genau diese schwachen, aber skalierbaren Signale – und darauf, warum ihre Kombination in einem probabilistischen Score deutlich aussagekräftiger ist als die Suche nach einem einzelnen Beweis.
Wie schwache technische Signale Dokumentenbetrug sichtbar machen.

Dokumentenbetrug wird häufig als binäre Frage betrachtet: Ist dieses Dokument echt oder gefälscht? In der Praxis stößt dieses Denken schnell an seine Grenzen. Die meisten betrügerischen Dokumente sind nicht vollständig gefälscht. Sie sind teilweise verändert, im falschen Kontext wiederverwendet oder so manipuliert, dass sie weiterhin plausibel wirken.
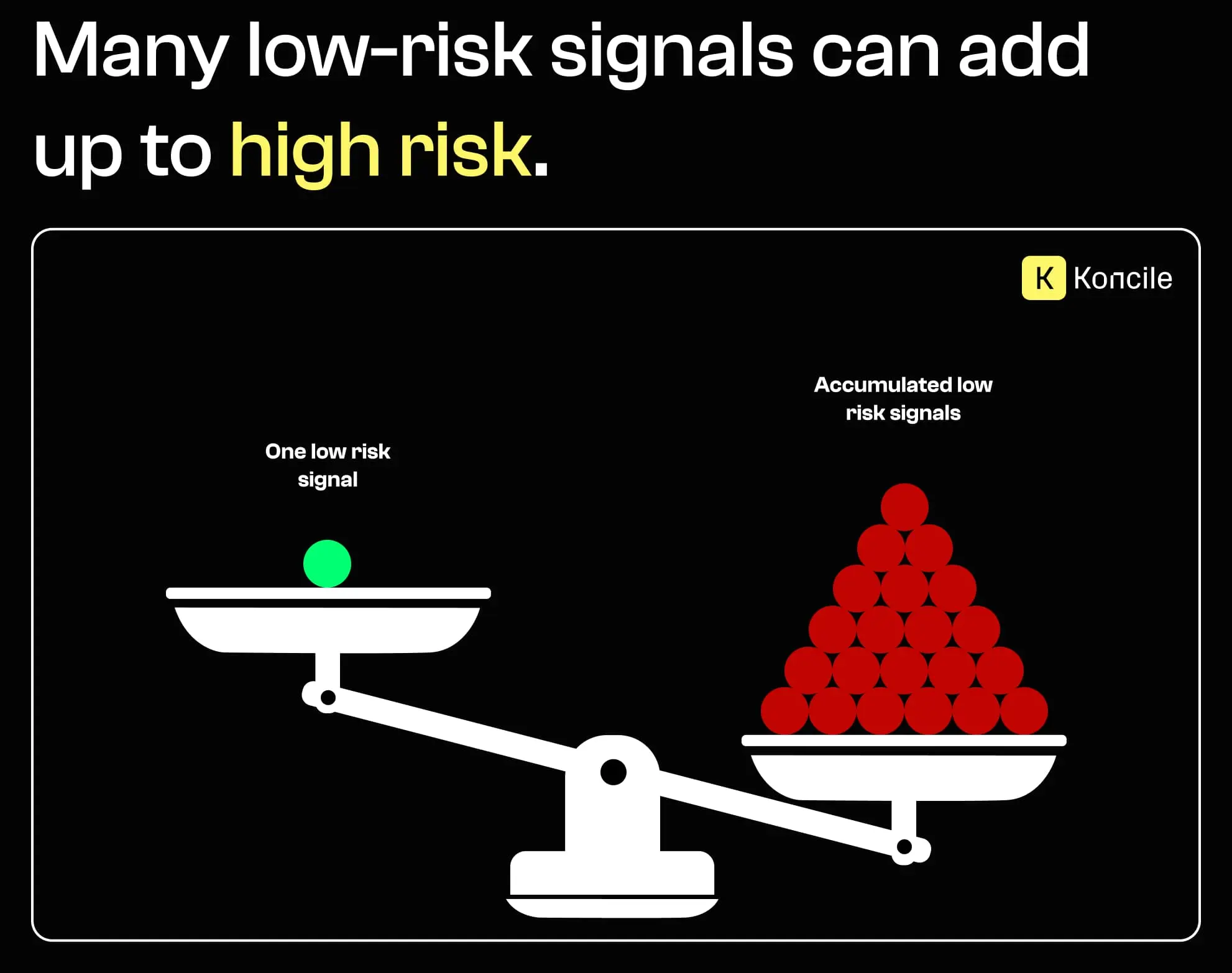
Ein effektiverer Ansatz besteht darin, Betrug als Scoring-Problem zu behandeln. Jedes Signal erhöht oder senkt das Gesamtrisiko geringfügig. Kein einzelner Test ist für sich genommen entscheidend, doch ihre Kombination erzeugt ein belastbares Vertrauensniveau.
Das ist besonders wichtig im industriellen Maßstab, wenn tausende Dokumente automatisiert und konsistent verarbeitet werden müssen.
PDF-Metadaten werden oft ignoriert oder als unzuverlässig betrachtet. Richtig eingesetzt gehören sie jedoch zu den skalierbarsten und kostengünstigsten Signalen überhaupt.
Ein häufig übersehenes Metadatenfeld ist die PDF-Version selbst.
Für sich genommen ist diese Information selten verdächtig. Im Verhältnis zum angeblichen Alter und Ursprung eines Dokuments kann sie jedoch aussagekräftig werden. Ein angeblich aktuelles Dokument, das mit einer veralteten PDF-Version erzeugt wurde, kann auf obsolete Werkzeuge, inoffizielle Produktionswege oder manuelle Re-Exporte hinweisen. Wie bei anderen Metadaten ist das Signal isoliert betrachtet schwach, trägt jedoch dazu bei zu beurteilen, ob der technische Kontext des Dokuments plausibel ist – insbesondere im Hinblick auf seine document structure und die mit seinem Ursprung verbundenen Erwartungen.
PDF-Dateien speichern technische Zeitstempel, darunter das Erstellungsdatum und das letzte Änderungsdatum. Sichtbare Inhalte lassen sich verändern, ohne visuelle Spuren zu hinterlassen. Ein Datum, ein Betrag oder ein Name kann manuell angepasst werden, während das Dokument weiterhin authentisch wirkt.
Metadaten erzählen eine andere Geschichte. Eine auffällige zeitliche Lücke zwischen CreationDate und ModDate wirft Fragen auf.
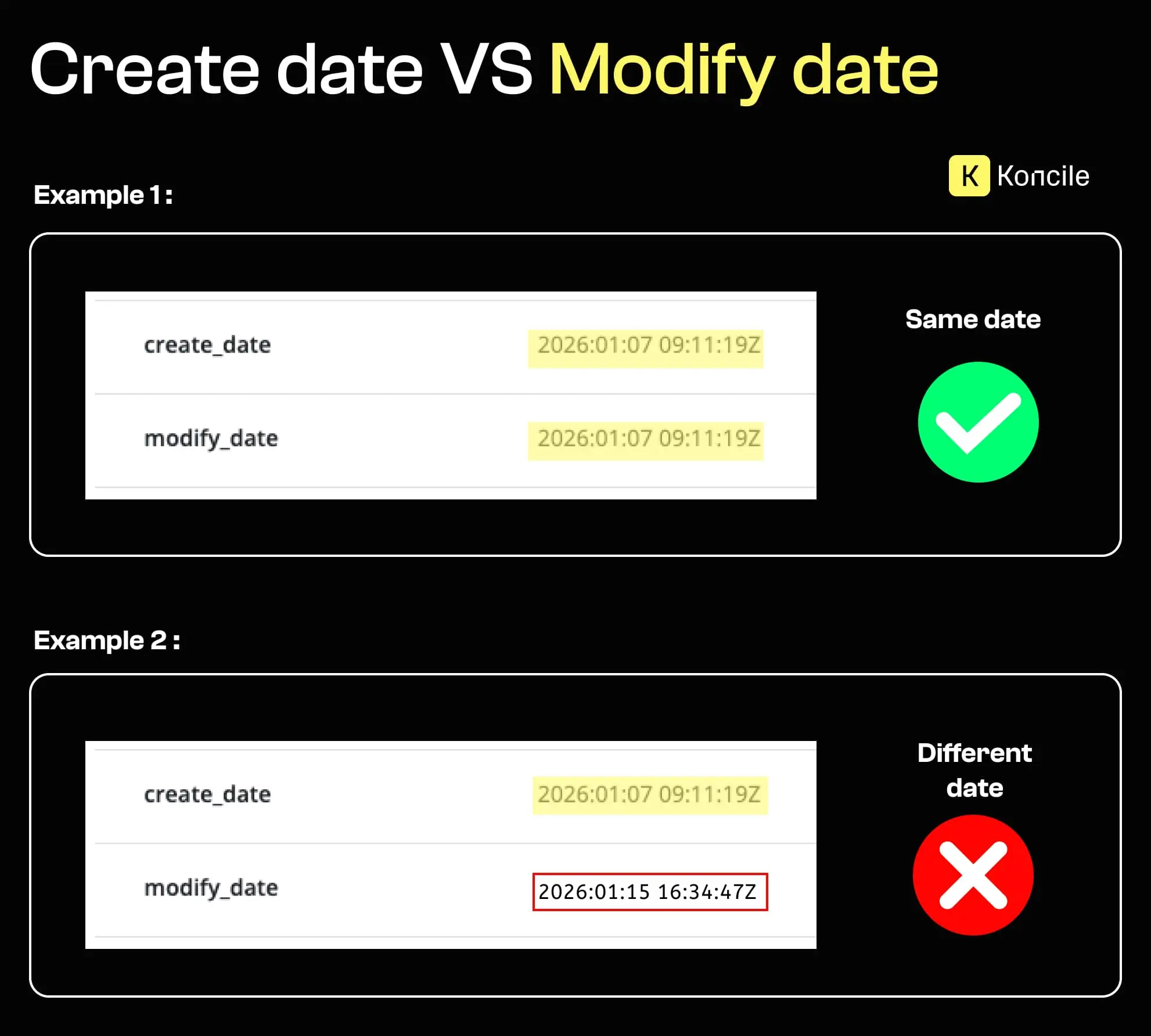
Dieses Signal ist für sich genommen schwach. Viele legitime Dokumente werden nachträglich verändert. Entscheidend ist der Kontext: Wie lange nach der Erstellung erfolgte die Änderung, um welchen Dokumenttyp handelt es sich, und sind solche Anpassungen im normalen Workflow zu erwarten?
Ein spätes Änderungsdatum bedeutet nicht automatisch Betrug. Ohne Kontext führt es zu Rauschen und Fehlalarmen. Wertvoll wird dieses Signal erst in Kombination mit weiteren Faktoren wie Dokumenttyp, semantischer Relevanz der Änderung und der Übereinstimmung mit erwarteten Zeitabläufen.
Einige Metadatenfelder kommen in legitimen Geschäfts- oder Verwaltungsdokumenten nahezu nie vor. Eingebettetes JavaScript gehört dazu. Obwohl PDF Skripting technisch unterstützt, ist es in Standardprozessen extrem selten. Wird es erkannt, deutet dies häufig auf nicht standardisierte Vorgänge wie Automatisierung, dynamische Manipulation oder versuchte Verhaltensänderungen beim Öffnen hin. Aufgrund seiner Seltenheit erhält dieses Signal meist ein höheres Risikogewicht als klassische Metadaten.
Jede PDF-Datei enthält Informationen über die Software, mit der sie erzeugt wurde. Dazu zählen die Felder Creator und Producer. Sie geben oft Aufschluss darüber, ob ein Dokument automatisiert von einem System oder manuell mit einem Endnutzer-Tool bearbeitet wurde.
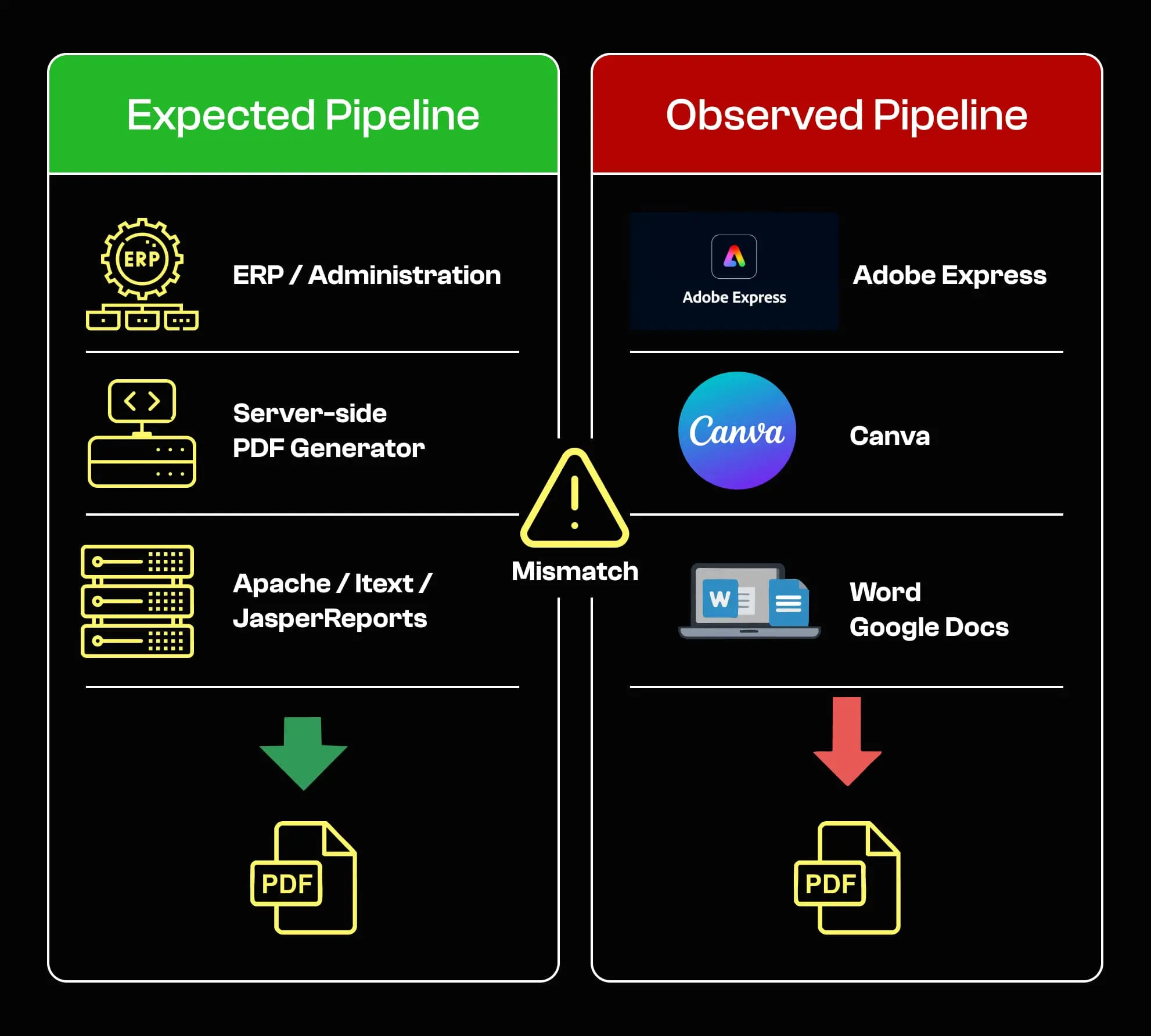
In der Praxis zeigen Creator- und Producer-Metadaten sehr deutlich, ob ein Dokument automatisch erzeugt oder manuell bearbeitet wurde. PDFs aus serverseitigen oder industriellen Systemen wie Reporting-Engines, ERP-Systemen oder Formular-Generatoren enthalten häufig Creator wie Apache-basierte Generatoren, iText-Serverbibliotheken, JasperReports oder Adobe LiveCycle.
Diese Werkzeuge werden typischerweise von Behörden und Unternehmen eingesetzt, um Dokumente in großem Umfang mit minimalem manuellen Eingriff zu erzeugen.
Demgegenüber weisen Creator wie Adobe Express, Canva, Microsoft Word, Google Docs oder PowerPoint meist auf manuelle Bearbeitung hin.
Das bedeutet nicht automatisch Betrug. Es wird jedoch zu einem starken Risikosignal, wenn solche Tools für Dokumente verwendet werden, die üblicherweise automatisiert erzeugt werden, etwa amtliche Bescheinigungen, Verträge oder administrative Nachweise. Genau diese Art von kontextuellem, multi-signalbasiertem Denken unterscheidet einen heuristischen Ansatz von echtem intelligent document processing mit Fokus auf Risikobewertung.
Beispiel:
1 – Dieses Dokument wurde laut Creator-Metadaten mit Adobe Express erstellt.
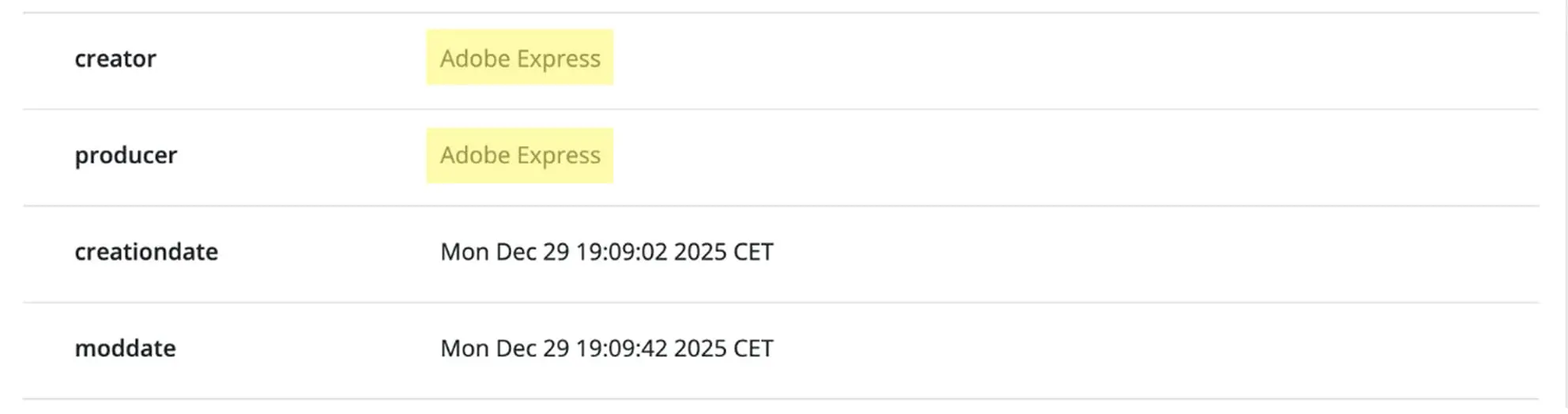
2 – Die ursprüngliche Version dieses Dokuments wurde mit einer Apache-basierten PDF-Engine erzeugt und später mit einem Bearbeitungstool erneut geöffnet und verändert. Das geänderte CreationDate macht diesen Übergang sichtbar.

Ein Marketing-Flyer aus Canva ist völlig normal. Ein behördliches Zertifikat aus Canva hingegen nicht. Dasselbe Tool kann in einem Kontext harmlos und in einem anderen hochgradig verdächtig sein.
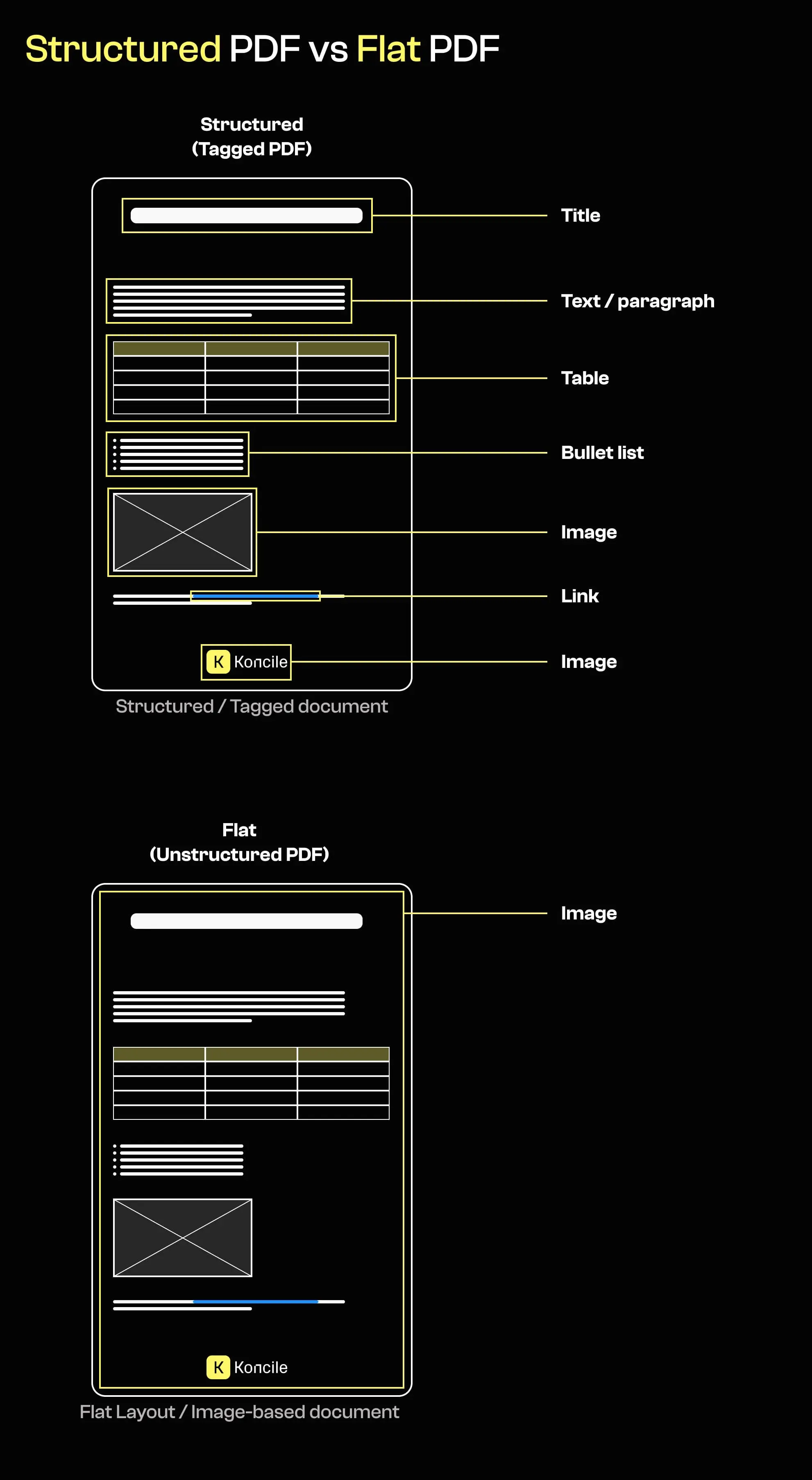
Neben der verwendeten Software liefert auch die interne Struktur eines PDFs wertvolle Hinweise auf dessen Ursprung. Viele offizielle oder regulierte Dokumente werden mit strukturierten Templates erzeugt und enthalten klar identifizierbare Textobjekte, logische Hierarchien und teilweise semantische Tags.
Dokumente, die als flache Layouts oder reine Bilder exportiert wurden, weisen diese Struktur oft nicht auf. Sie bestehen häufig aus einem einzigen Vollseitenbild pro Seite, gelegentlich ergänzt durch eine nachträglich hinzugefügte OCR-Textebene.
Das Fehlen einer Struktur beweist keine Manipulation. Es kann jedoch darauf hindeuten, dass das Dokument mit Werkzeugen oder Prozessen erzeugt oder verändert wurde, die nicht zum behaupteten Ursprung passen.
Ein Dokument sollte nicht nur danach beurteilt werden, wie es aussieht, sondern ob seine Entstehung zu dem passt, was es vorgibt zu sein.
Strukturelle Signale gehen häufig mit weiteren technischen Spuren einher, die Aufschluss über die tatsächliche Entstehung eines Dokuments geben. Dazu zählen Farbprofile in den Metadaten.
ICC-Farbprofile werden typischerweise durch Scanner, Drucker oder Bildverarbeitungs-Pipelines eingebracht. Enthält ein als nativ digital präsentiertes Dokument Metadaten, die üblicherweise mit gescannten Bildern verbunden sind, wirft dies Fragen zur tatsächlichen Herkunft auf.
Dieses Signal ist subtil und für sich genommen selten entscheidend. In Kombination mit einer flachen Struktur oder fehlender semantischer Auszeichnung hilft es jedoch, echte digitale Dokumente von als Original präsentierten Scans zu unterscheiden.

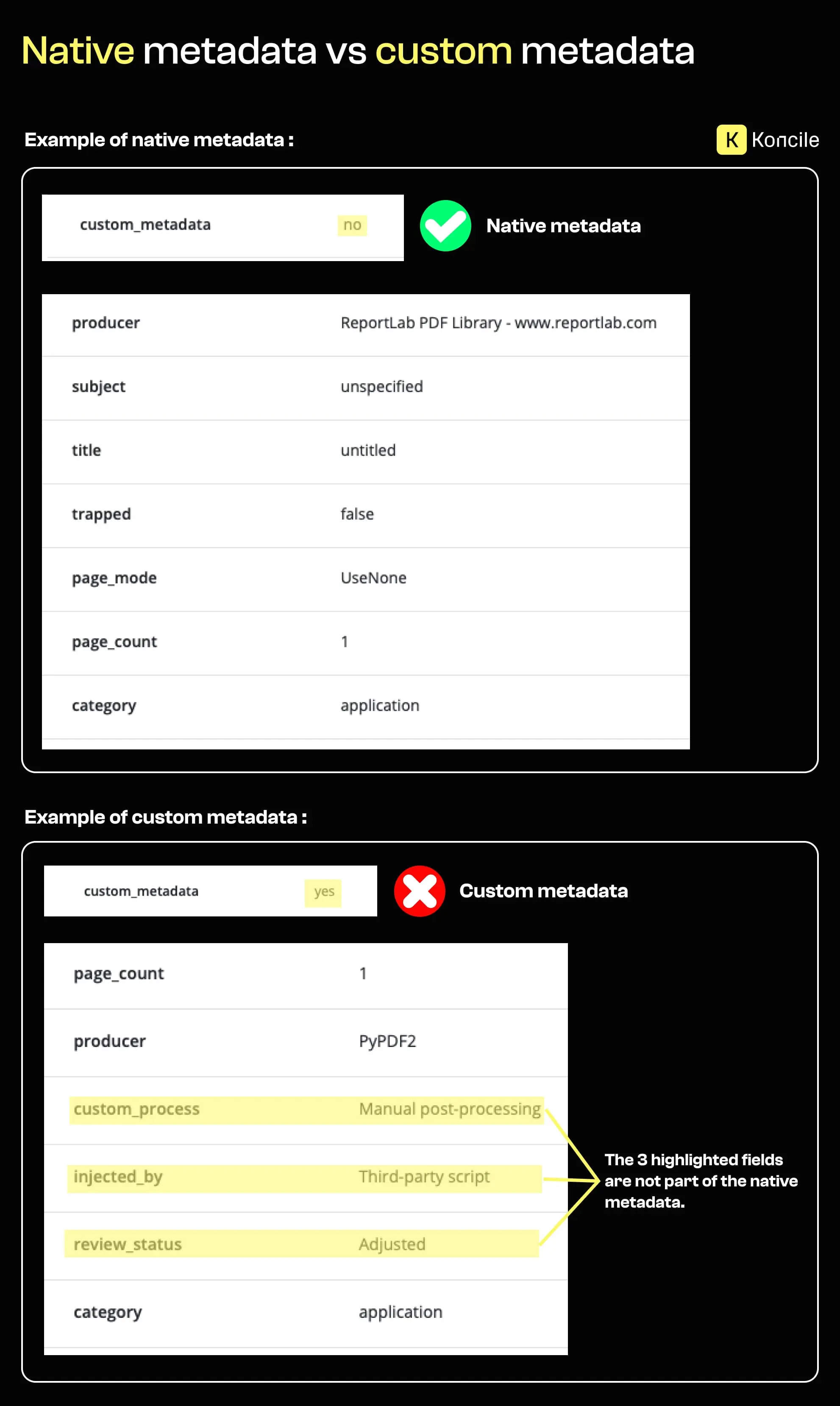
Einige PDFs enthalten benutzerdefinierte Metadatenfelder, die nach der ursprünglichen Erstellung hinzugefügt wurden. Sie entstehen häufig durch Skripte, Drittanbieter-Tools oder manuelle Prozesse.
In offiziellen oder regulierten Dokumenten sind solche Felder selten. Ihre Existenz beweist keine Manipulation, deutet jedoch auf einen nicht standardisierten Produktions- oder Transformationsprozess hin.
Im großen Maßstab können wiederkehrende Muster benutzerdefinierter Metadaten über viele Dokumente hinweg auf industrialisierte Manipulationen statt auf Einzelfälle hinweisen.
Nicht jede technisch saubere Idee eignet sich zur Betrugserkennung. Einige Ansätze sind intuitiv, weit verbreitet und dennoch irreführend.
Dateihashes werden häufig zur Manipulationserkennung vorgeschlagen. Ein Hash identifiziert eine Datei eindeutig. Jede Änderung erzeugt einen neuen Hash.
Das ist korrekt, aber trivial. Jede Änderung – legitim oder nicht – führt zu einem neuen Hash. Hashes zeigen nur, ob zwei Dateien exakt identisch sind. Sie sagen nichts über Glaubwürdigkeit, Kontext oder Betrugsabsicht aus.
Hashes sind sinnvoll für Deduplikation und Integritätsprüfungen, nicht jedoch für Betrugserkennung.
Forensische Werkzeuge ermöglichen tiefgehende Analysen von Dateistrukturen, binären Unterschieden und historischen Spuren. Sie sind unverzichtbar für Untersuchungen und Gutachten.
Für eine kontinuierliche, automatisierte Betrugserkennung im großen Maßstab sind sie jedoch ungeeignet. Sie erklären, was passiert ist – nicht, wo Risiko besteht.
Entscheidend ist nicht, ob sich eine Datei geändert hat, sondern ob die Änderung relevant ist. Eine Annotation oder Tippfehlerkorrektur ist nicht mit der Änderung eines Betrags, Datums oder einer Identität gleichzusetzen.
Semantische Änderungen beeinflussen die Bedeutung oder rechtliche Wirkung eines Dokuments. Kosmetische Änderungen nicht. Effektive Systeme müssen diesen Unterschied erkennen und entsprechend bewerten.
Betrug existiert selten isoliert. Einzelne Dokumente wirken oft plausibel, doch über Zeit oder Nutzer hinweg entstehen Muster.
Wiederholte Ähnlichkeiten, minimale Variationen, unplausible Zeitachsen oder wiederverwendete Strukturen können auf organisierte Manipulationen hinweisen. Kontextanalyse macht aus schwachen Einzelsignalen belastbare Hinweise.
Für einen umfassenderen Überblick siehe unseren Leitfaden zur Dokumentenbetrugserkennung auf der Koncile-Website.
Die Erkennung von Dokumentenbetrug entfernt sich zunehmend von binären Regeln und offensichtlichen Fehlern. Die effektivsten Systeme zur Dokumentenbetrugserkennung konzentrieren sich auf schwache technische Signale, kontextuelle Kohärenz und nachvollziehbare Bewertungsmodelle. Metadaten, Produktionswerkzeuge und subtile Unstimmigkeiten werden oft übersehen, liefern jedoch wertvolle Erkenntnisse, wenn sie intelligent miteinander kombiniert werden. Da die Erstellung von Dokumenten immer einfacher und stärker automatisiert wird, wird die Betrugserkennung künftig weniger von starren Regeln abhängen und stärker davon, beurteilen zu können, was plausibel ist. Einen Marktvergleich bietet unsere Auswahl der besten Software zur Dokumentenbetrugserkennung.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


