


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
June 19, 2026
5 minutes
La fraude documentaire moderne est rarement évidente. Elle ne repose plus sur des faux grossiers, mais sur des documents qui semblent légitimes, se lisent correctement et passent les contrôles basiques. Aujourd’hui, détecter la fraude consiste moins à repérer des erreurs visibles qu’à identifier des signaux techniques subtils qui révèlent des incohérences, des manipulations ou des trajectoires improbables. Cet article se concentre sur ces signaux faibles mais scalables, et explique pourquoi les combiner dans un score probabiliste compte davantage que de chercher une preuve unique.
Comment des signaux techniques faibles révèlent les risques de fraude documentaire.

La détection de fraude documentaire est souvent abordée comme une question binaire : ce document est-il faux ou authentique ? En pratique, ce réflexe échoue rapidement. La plupart des fraudes ne sont pas totalement “fausses”. Elles sont partiellement modifiées, réutilisées hors contexte, ou manipulées juste assez pour rester plausibles.
Une approche plus efficace consiste à traiter la détection comme un problème de scoring. Chaque signal augmente ou diminue légèrement le niveau de risque. Aucun test n’est décisif à lui seul, mais leur accumulation construit un niveau de confiance réellement exploitable.
C’est particulièrement critique à grande échelle, lorsque des milliers de documents doivent être traités automatiquement et de façon cohérente.

Les métadonnées PDF sont souvent ignorées ou jugées peu fiables. Pourtant, utilisées avec méthode, elles offrent certains des signaux les plus scalables et les moins coûteux à exploiter.
Un autre champ de métadonnées souvent négligé est la version PDF elle-même.
Cette information déclenche rarement une alerte à elle seule, mais elle devient intéressante dès qu’on la compare à l’âge supposé et à l’origine du document. Un document présenté comme récent, mais généré avec une version PDF très ancienne, peut indiquer l’usage d’outils obsolètes, de pipelines non officiels, ou un ré-export manuel. Comme pour les autres métadonnées, le signal est faible isolément, mais il contribue à évaluer si le contexte technique du document “fait sens”, notamment lorsqu’on l’analyse au regard de la document structure et des attentes liées à son origine.
Les PDF stockent des timestamps techniques, notamment le moment de création et la dernière modification. Il est tout à fait possible d’altérer du contenu visible d’un PDF sans laisser de trace visuelle. Une date, un montant ou un nom peuvent être modifiés manuellement, alors que le document paraît toujours authentique.
Les métadonnées racontent une autre histoire. Lorsqu’un document présente un écart significatif entre sa date de création et sa date de modification, cela soulève des questions.

Le signal reste faible. De nombreux documents légitimes sont modifiés après leur création. Ce qui compte, c’est le contexte : combien de temps après la création la modification intervient, de quel type de document il s’agit, et si ce type d’édition correspond à un workflow normal.
Une modification tardive ne signifie pas fraude par défaut. Sans interprétation, ce signal génère du bruit et des faux positifs. Ce qui le rend réellement utile, c’est sa combinaison avec d’autres facteurs : type de document, impact sémantique de l’édition, et cohérence avec des délais attendus.
Certains champs de métadonnées sont presque jamais présents dans des documents professionnels ou administratifs légitimes. Le JavaScript embarqué en fait partie. Même si le format PDF supporte des scripts pour des cas avancés, leur présence est rare dans les workflows documentaires standard. Lorsqu’on en détecte, cela signale souvent un comportement non standard : automatisation, manipulation dynamique, ou tentatives de modifier le comportement du document à l’ouverture. En raison de sa rareté, ce champ porte généralement un poids de risque plus élevé que des indicateurs plus courants.
Chaque PDF contient des informations sur le logiciel qui l’a généré. Cela inclut notamment les champs Creator et Producer. Ces valeurs révèlent souvent si un document a été généré automatiquement par un système, ou s’il a été manipulé via des outils grand public.
En pratique, les champs Creator et Producer indiquent souvent si un document a été généré automatiquement ou édité manuellement. Les PDFs produits par des outils serveur ou industriels, comme des moteurs de reporting, des ERP ou des générateurs de formulaires, affichent typiquement des creators comme des générateurs basés sur Apache, des librairies iText côté serveur, JasperReports, ou Adobe LiveCycle.
Ces outils sont couramment utilisés par des administrations et des entreprises pour générer des documents à grande échelle, avec peu d’intervention humaine. À l’inverse, des documents dont les creators indiquent Adobe Express, Canva, Microsoft Word, Google Docs ou PowerPoint suggèrent plus souvent une édition manuelle.
Cela n’implique pas fraude en soi, mais cela devient un signal de risque fort lorsque ces outils sont utilisés pour des documents qui, normalement, sont générés automatiquement : certificats officiels, contrats ou pièces administratives. C’est précisément ce type de raisonnement contextuel et multi-signaux qui distingue une approche heuristique d’un véritable intelligent document processing orienté risque.
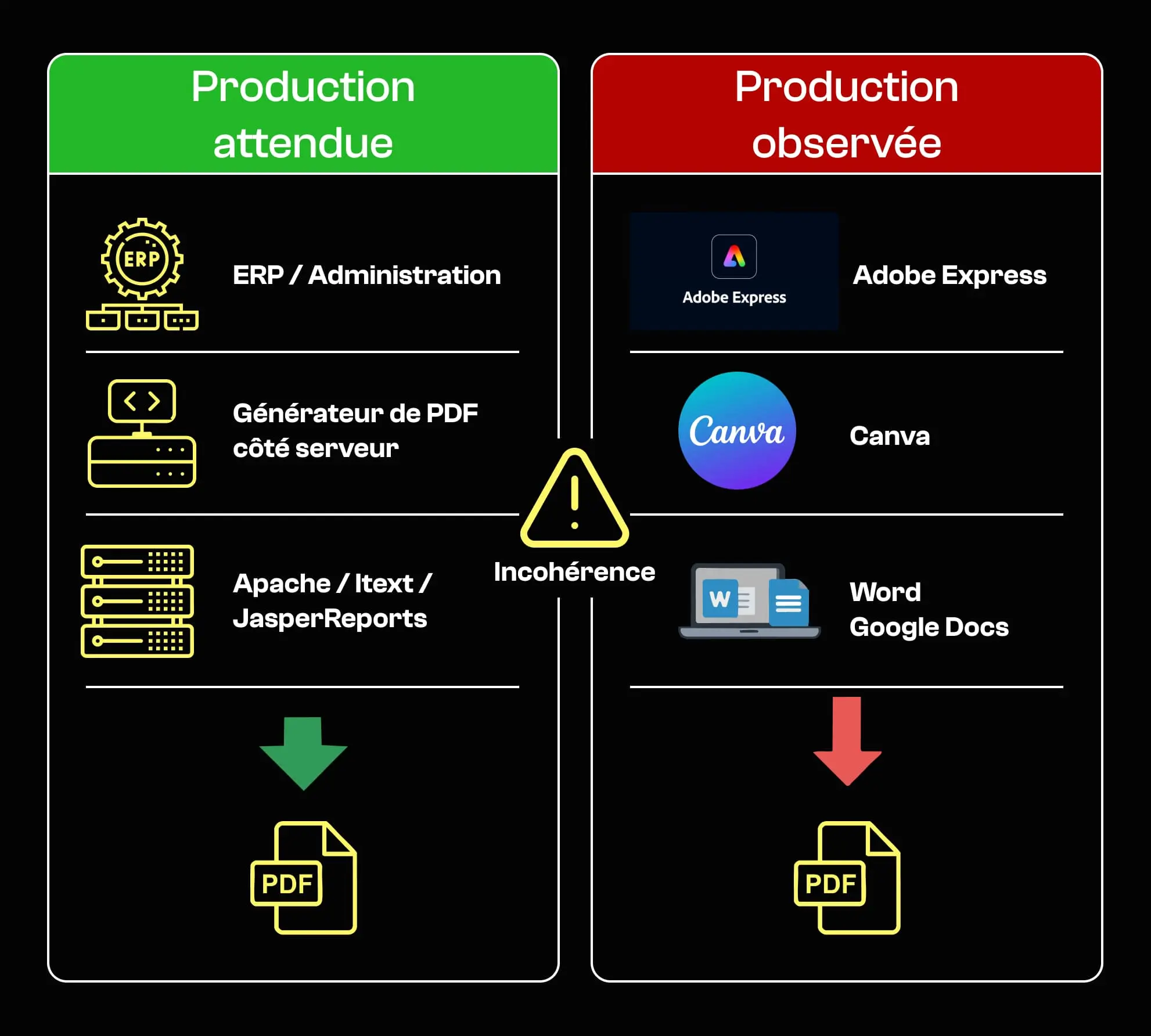
Par exemple :
1 – Ce document a été généré avec Adobe Express, comme l’indique le champ Creator dans ses métadonnées.
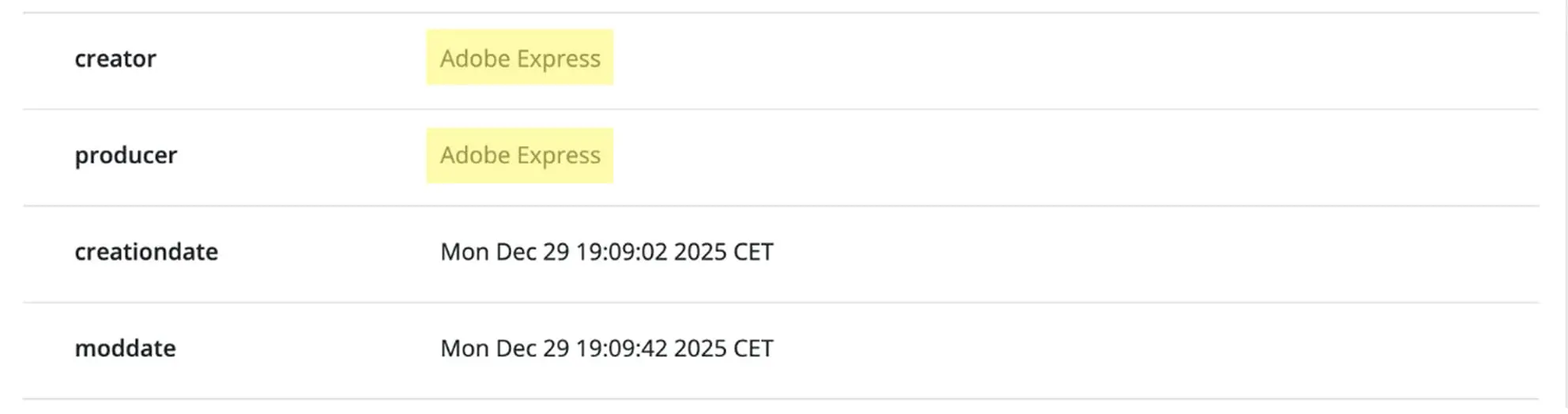
2 – La version originale de ce document a été générée par un moteur PDF basé sur Apache, puis rouverte et modifiée via un outil d’édition. On voit aussi que la CreationDate a été ajustée en conséquence.

Une brochure marketing générée dans Canva est parfaitement normale. Un certificat gouvernemental généré dans Canva ne l’est pas. Le même outil peut être anodin dans un contexte et très suspect dans un autre.
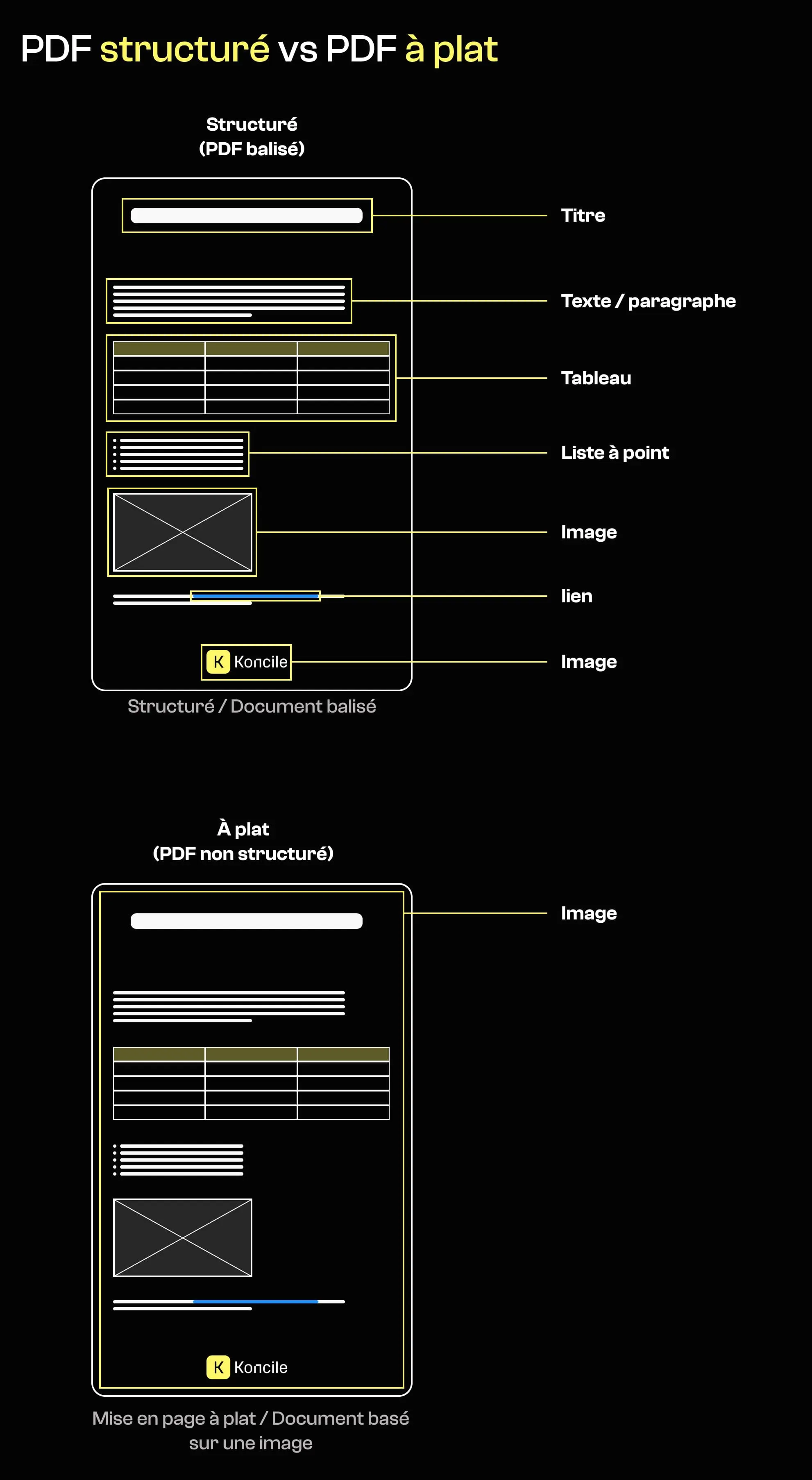
Au-delà du logiciel de génération, la structure interne d’un PDF fournit des indices importants sur son origine. De nombreux documents officiels ou réglementés sont produits via des templates structurés, avec des objets texte identifiables, des hiérarchies logiques, et parfois un balisage sémantique.
À l’inverse, les documents exportés comme des mises en page “à plat” ou des images manquent souvent de structure interne. Ils peuvent se résumer à une image pleine page par page, parfois complétée par une couche de texte OCR ajoutée après coup.
L’absence de structure ne prouve pas, à elle seule, une manipulation. En revanche, elle peut indiquer que le document a été généré ou transformé via des outils ou des pipelines différents de ceux normalement associés à son origine supposée.
Un document ne devrait pas être évalué uniquement sur son apparence, mais aussi sur la cohérence entre ce qu’il prétend être et la manière dont il a été produit.
Les signaux liés à la structure s’alignent souvent avec d’autres traces techniques qui révèlent comment un fichier a été produit. Les métadonnées peuvent, par exemple, donner des indices sur l’origine réelle du document via des éléments comme les profils colorimétriques.
Les profils ICC sont fréquemment introduits par des scanners, des imprimantes ou des pipelines de traitement d’image. Lorsqu’un document présenté comme “nativement digital” contient des métadonnées typiques d’images scannées, cela soulève des questions sur la façon dont il a réellement été produit.
Ce signal est subtil et rarement significatif isolément. Mais combiné à une structure à plat ou à l’absence de balisage sémantique, il aide à distinguer un document réellement numérique d’un scan présenté comme un original.

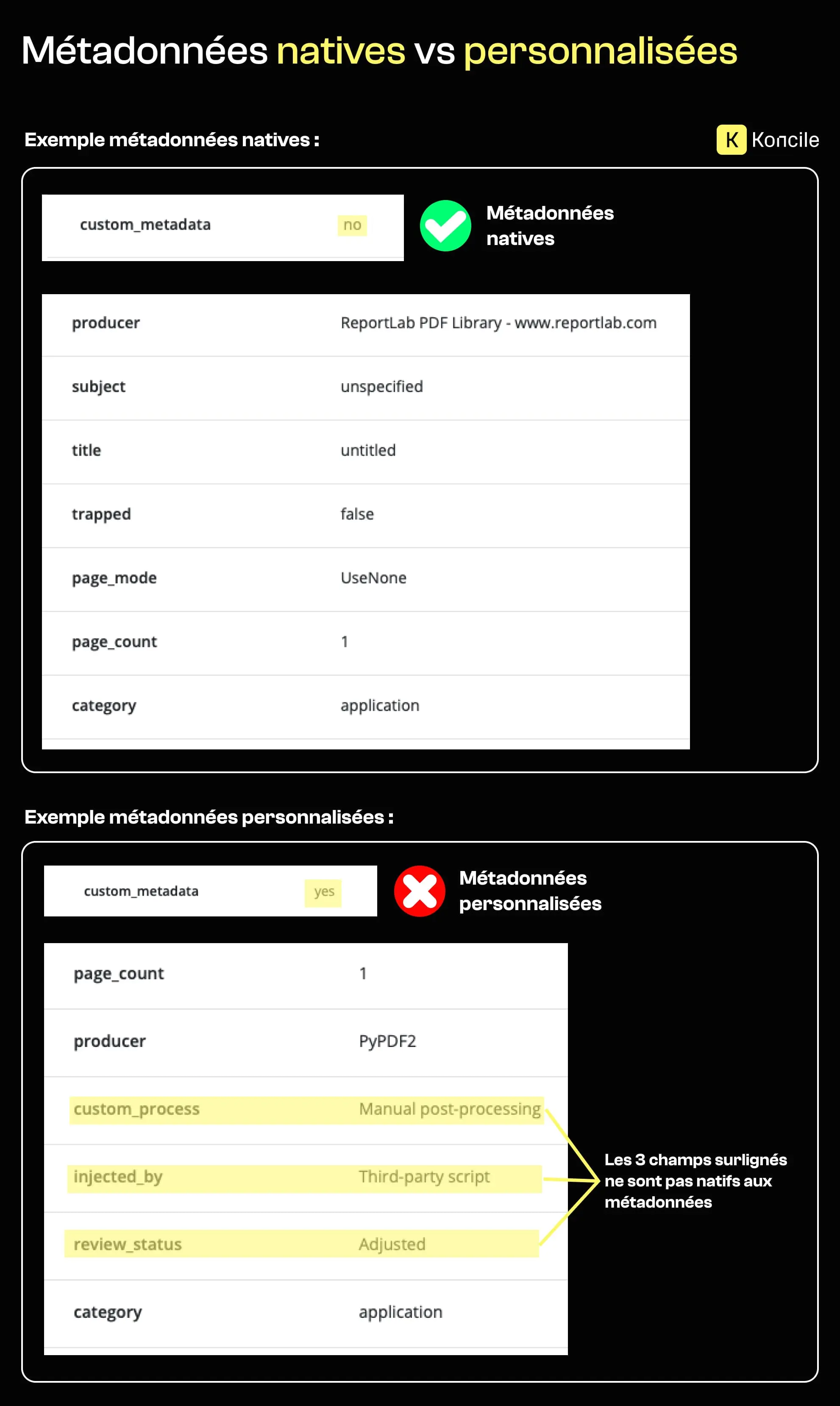
Certains PDFs contiennent des champs de métadonnées personnalisés ajoutés après la génération initiale. Ces champs apparaissent souvent lorsque des scripts, des outils tiers ou des processus manuels injectent des informations supplémentaires dans le fichier.
Dans les documents officiels ou réglementés, ces champs personnalisés sont relativement rares. Leur présence ne prouve pas la manipulation, mais elle indique que le document est passé par un processus de production ou de transformation non standard.
À grande échelle, des patterns récurrents de métadonnées personnalisées sur des documents similaires peuvent révéler une manipulation industrialisée plutôt que des edits isolés ou légitimes.
Toutes les idées “techniques” qui semblent rigoureuses ne sont pas utiles pour détecter la fraude. Certaines approches sont intuitives, populaires, et pourtant trompeuses.
Les hashs de fichier sont souvent présentés comme un moyen de détecter des altérations. Un hash représente un fichier de manière unique. Si le fichier change, le hash change.
C’est vrai, mais trivial. Toute modification, légitime ou non, produit un nouveau hash. Les hashs disent uniquement si deux fichiers sont strictement identiques. Ils ne disent rien sur la crédibilité du document, sa cohérence ou l’intention derrière une modification.
Les hashs sont utiles pour la déduplication et les contrôles d’intégrité. Ce ne sont pas des signaux de fraude.
Les outils d’analyse forensique permettent d’inspecter en profondeur la structure d’un fichier, ses différences binaires, et parfois des traces historiques. Ils sont précieux pour des investigations et des expertises.
Mais ils sont lents, complexes, et nécessitent une intervention humaine. Ils servent à expliquer ce qui s’est passé une fois qu’un doute existe, pas à détecter du risque sur des milliers de documents en continu.
La distinction critique en détection de fraude documentaire n’est pas “le fichier a-t-il changé ?”, mais “le changement a-t-il du sens ?”. Ajouter une annotation ou corriger une typo n’est pas équivalent à modifier un montant, une date ou une identité.
Les changements sémantiques modifient la signification ou l’impact juridique d’un document. Les changements cosmétiques n’ont pas cet effet. Un système efficace doit distinguer les deux et attribuer un niveau de risque en conséquence.
Cela implique de combiner signaux techniques et compréhension du document, plutôt que de se limiter à des contrôles au niveau du fichier.
La fraude existe rarement en isolation. Un document pris seul peut sembler légitime, mais des patterns émergent lorsqu’on compare les documents dans le temps ou entre utilisateurs.
Similarités répétées, micro-variations, timelines improbables, structures réutilisées : tout cela peut signaler une manipulation organisée. L’analyse contextuelle transforme des signaux faibles isolés en preuves fortes.
Pour une vue plus large des stratégies et méthodes de prévention, consultez notre guide existant sur la fraude documentaire sur le site de Koncile.
La détection de fraude documentaire s’éloigne progressivement des règles binaires et des erreurs visibles. Les systèmes de détection de fraude documentaire les plus performants reposent sur des signaux techniques faibles, la cohérence contextuelle et des mécanismes de scoring explicables. Les métadonnées, les outils de production et les incohérences subtiles sont souvent négligés, alors qu’ils apportent des informations précieuses lorsqu’ils sont analysés de manière combinée et intelligente. À mesure que la génération de documents devient plus simple et plus automatisée, la détection de fraude dépendra moins de règles strictes et davantage de la capacité à évaluer ce qui est plausible. Pour comparer les outils du marché, découvrez notre sélection des meilleurs logiciels de détection de fraude documentaire.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


