


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité
.webp)
Dernière mise à jour :
June 19, 2026
5 minutes
Toutes les OCR open source ne proposent pas d’API prête à l’emploi. Voici un test terrain pour comprendre les différences.
Test comparatif de 5 OCR API open source en 2026 : intégration, rendu JSON et facilité de mise en place analysés.

Il existe une multitude d’OCR disponibles sur le marché, cependant dès lors que l’on parle de leur intégration à des process le sujet de l’API et du prix de la solution est omniprésent. Une question se pose, qu’en est-il des solutions open source, et quelles sont leurs difficultés d’intégration ?
Je vous ai donc préparé un classement des 5 meilleures solutions OCR open source disponibles par API. Par ailleurs je tiens à vous préciser que je ne suis pas développeur, les solutions présentées ici sont pour la grande majorité assez simples à intégrer et sont compréhensibles pour les amateurs en intégration.
La très grande majorité des solutions OCR SaaS actuelles ne sont pas open source mais proposent des OCR API. Cependant, si vous avez déjà cherché des OCR API open source sur internet, vous vous êtes sûrement heurtés à un mur. Tous les OCR open source ne proposent pas une API clé en main. Il faut souvent la construire soi-même.
Il y a quelque chose d’important à savoir avant de commencer, c’est que chaque solution peut être intégrée de manière différente et avec des utilisations et une disponibilité open source plus ou moins limitées. C’est pourquoi on se retrouve avec plusieurs catégories. De fait, si les OCR open source proposaient des solutions API clé en main, ne touchant aucun revenu sur l’utilisation de leur modèle, il serait impossible de financer l’hébergement et la maintenance des solutions. C’est là tout l’intérêt des Saas de ce domaine, le service est donc payant, la clé API l’est donc aussi, néanmoins la solution est stable, rapide, sécurisée et souvent plus performante. Il existe aussi un entre-deux où les solutions sont des OCR Open source mais leurs API sont hébergées par des SaaS.
Aujourd’hui je vais vous présenter 3 types de solutions open source :
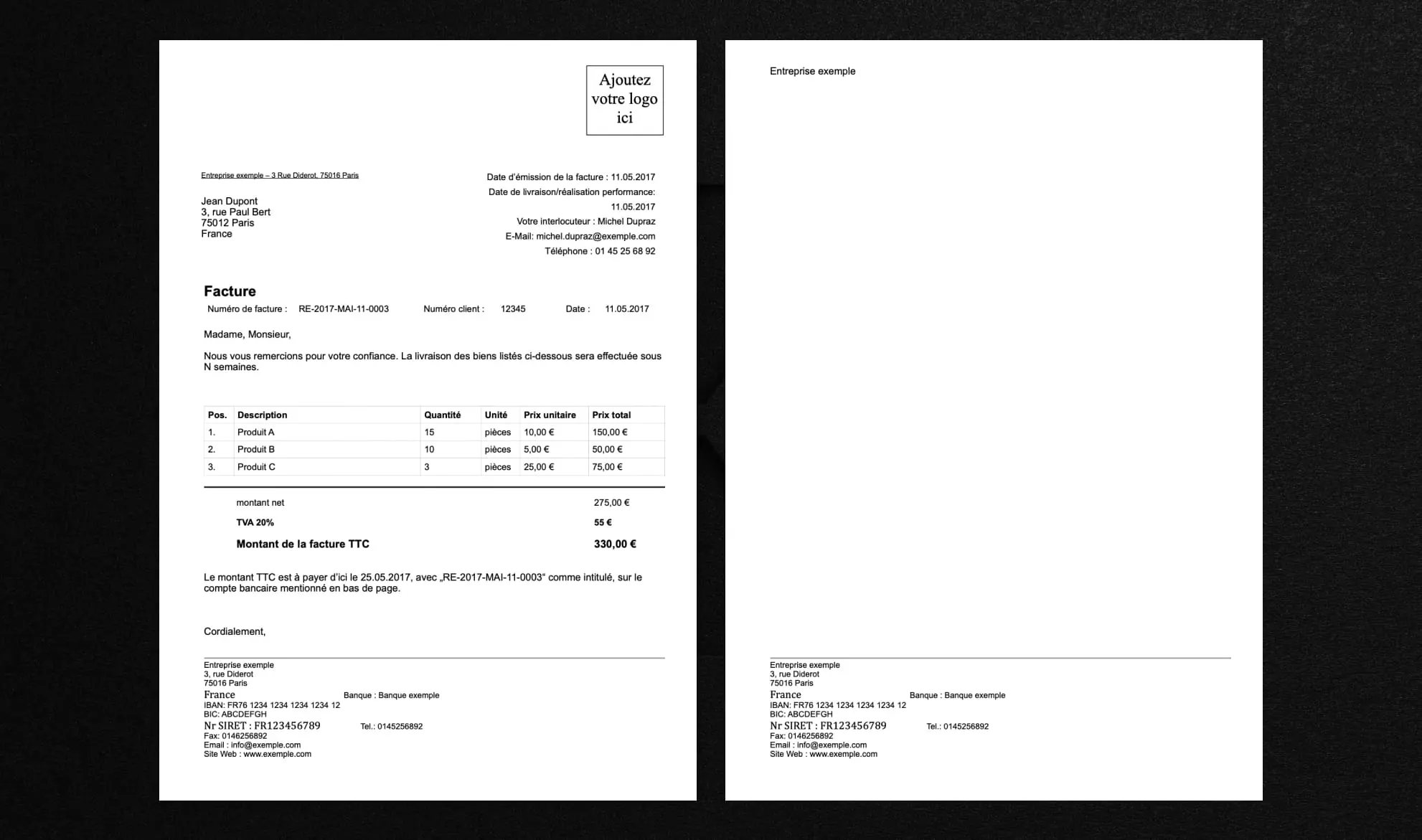
Cette facture, assez simple, fait office de document test pour cette comparaison, à titre indicatif ; des tests réellement poussés portent sur des batteries de documents plus fournis et variés. Surtout pour les cas d’automatisation de documents à grande échelle.
Cette catégorie représente les solutions OCR strictement open source.

Simple : j’ai réussi à créer cette API HTTP sans connaissance en code, cependant le processus a été assez long, le temps de trouver la bonne méthode. Si vous rencontrez des problèmes, un LLM vous expliquera assez bien le chemin à suivre.
Possibilité de télécharger le fichier JSON de l’extraction prêt à être envoyé dans un ERP ou un CRM, par exemple. L’exécution est assez rapide et tout a été extrait correctement, il a repéré les tableaux et a bien classé les données. Il attribue même un score de confiance. C’est sûrement la solution la plus efficace de cette catégorie en rapport temps investi/données récoltées.
Voici en image un extrait du document JSON output pour Doc TR

Moyenne : Paddle OCR n’intègre pas nativement le traitement des PDF, alors j’ai ajouté un support supplémentaire pour cette fonction. Cela a marché mais m’a pris plus de temps, j’ai donc refait le test en transformant en amont mon PDF en image. Une fois transformé, j’ai donc récupéré 2 images, et ajouté la possibilité de charger plusieurs fichiers pour une même extraction. L’intégration de Paddle OCR comporte certaines subtilités, il est clairement prévu à l’origine pour de l’extraction de texte dans les images. Si vous l’utilisez pour cela, son intégration est bien plus rapide.
L’intégration àa marché, Paddle OCR a réussi à extraire parfaitement la donnée, cependant l’export JSON est bien moins structuré.
Voici en image un extrait du document JSON output pour Paddle OCR
Simple : La création d’une API via FastAPI se fait rapidement et l’envoi d’images fonctionne immédiatement. En revanche, l’installation du moteur système est obligatoire et la gestion des PDF nécessite un traitement supplémentaire.
Tesseract extrait correctement le texte de la facture. Les informations principales sont présentes, mais le résultat est renvoyé sous forme de bloc texte brut. Aucune structuration des tableaux ou des champs métier n’est fournie. Un parsing complémentaire est donc indispensable pour exploiter les données.
Voici en image un extrait du document JSON output pour Tesseract

Plutôt compliquée. Contrairement à Tesseract, Kraken ne fonctionne pas immédiatement après installation. Il faut télécharger un modèle séparément, comprendre où il est stocké sur le système et adapter le code en conséquence. L’intégration demande plus de manipulation et quelques ajustements avant d’obtenir une API fonctionnelle. Ce n’est pas vraiment du plug-and-play.
Kraken utilise une approche basée sur le deep learning et commence par analyser la structure visuelle de la page avant d’extraire le texte. Sur une facture moderne, le texte est bien extrait mais comporte davantage d’erreurs que Tesseract. Comme ce dernier, le résultat est renvoyé sous forme de bloc texte brut, sans tableau structuré ni séparation automatique des champs importants. Kraken semble donc plus adapté à des documents complexes ou anciens qu’à des documents administratifs classiques.
Voici en image un extrait du document JSON output pour Kraken
Contrairement aux autres solutions présentées ci-dessus, OCR.space n’est pas une librairie open source auto-hébergée. Il s’agit d’un service SaaS exposant une API publique, partiellement basée sur Tesseract. J’ai testé son intégration via n8n afin d’évaluer la simplicité d’appel API par rapport à une API auto-hébergée.
Simple : L’intégration via n8n repose uniquement sur un appel HTTP configuré graphiquement. Aucun serveur n’est à déployer, aucune dépendance à installer. En quelques minutes, il est possible de récupérer un fichier, l’envoyer à l’API OCR.space et d'exploiter le JSON retourné. Comparé à une API auto-hébergée (FastAPI + librairie open source), le gain en temps d’installation est significatif. Il n‘y a pas besoin de créer d’infrastructure.
L’exécution est rapide et le texte est correctement extrait. La réponse JSON est exploitable immédiatement et peut être redirigée vers un Google Sheet, un CRM ou tout autre outil connecté. En revanche, le rendu reste relativement brut. La structuration des données (tableaux, champs métier, hiérarchisation) dépendra d’un traitement supplémentaire en aval.
Voici en image un extrait de la structure de l’output pour Tesseract.

Intégration complexe : Après quelques essais, il s’avère que GOT - OCR n’est pas une solution open source plug and play comme Doc TR pour les documents ou Paddle OCR pour les images. Son installation nécessite un accès spécifique ou un setup plus avancé.
L’idée d’une solution VLM (Vision Language Model) comme GOT-OCR est de proposer une couche de compréhension dans l’analyse du document. Ce type de modèle permet de faire des liens entre les différentes informations présentes dans un document et d’en faire une analyse sémantique. Ce qui est intéressant dès lors que vos problématiques de documentation sortent un peu de l’ordinaire. C’est certainement la proposition la moins éloignée de ce que proposent des solutions d’Intelligent Document Processing clés en main comme Koncile.
Voici quelques détails complémentaires :
DocTR
C’est la solution open source la plus équilibrée dans ce test. Le JSON est structuré par blocs et lignes, ce qui facilite la reconstruction des tableaux et des champs métier. L’intégration demande un peu de mise en place, mais reste accessible.
Paddle OCR
Très performant sur l’extraction pure du texte, notamment sur image. En revanche, le JSON repose principalement sur des coordonnées, ce qui rend la reconstruction logique du document plus complexe. Il est efficace, mais demande du travail en aval.
Tesseract
Le plus simple à intégrer techniquement, mais le rendu est brut. Tout est renvoyé sous forme d’un bloc texte. Il constitue une bonne base, mais nécessite un parsing complémentaire pour une exploitation métier.
Kraken
Plus complexe à mettre en place et moins performant sur une facture moderne. Il semble davantage adapté à des documents anciens ou spécifiques qu’à des documents administratifs classiques. L’intégration est clairement plus lourde.
OCR.space
Le plus simple à intégrer grâce à son API SaaS. Aucun serveur à déployer. Le rendu est propre, surtout sur PDF natifs. En revanche, la structuration reste limitée et dépend d’un traitement supplémentaire.
GOT-OCR
Plus avancé dans l’approche, avec une logique orientée compréhension du document. En revanche, l’installation est plus lourde et moins adaptée à une intégration rapide. Intéressant pour des cas complexes, moins pour un usage standard.
Ce test montre surtout une chose : l’OCR, ce n’est pas juste une question de précision, c’est une question d’intégration. Les moteurs open source fonctionnent, mais ils demandent du temps, de la configuration et parfois pas mal d’ajustements avant d’être réellement exploitables. Plus vos besoins sont simples, plus une solution brute peut suffire. Plus vos usages sont métiers et structurés, plus la couche d’intégration devient centrale. Au final, le choix ne se fait pas uniquement sur la qualité du texte extrait, mais sur l’équilibre entre effort d’intégration, structure du rendu et stabilité dans le temps.
Les solutions open source sont de bons moyens de limiter les coûts directs et d’effectuer des travaux d'automatisation de documents à petite échelle, cependant pour des intégrations plus stables, scalable, et clés en main, il sera plus simple de s’orienter vers des solutions d’Intelligent Document Processing.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Tristan Thommen conçoit et déploie les briques technologiques qui transforment des documents non structurés en données exploitables. Il allie IA, OCR et logique métier pour simplifier la vie des équipes.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


