



Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dernière mise à jour :
June 19, 2026
5 minutes
L'OCR (Optical Character Recognition) ou reconnaissance optique de caractères est une technologie qui permet de convertir des documents papier, images ou PDF en texte exploitable par un ordinateur. Grâce à cette technologie, vous pouvez extraire les informations que vous souhaitez de vos documents PDF ou image.
On vous explique l’essentiel de l'OCR, ses usages concrets et ses atouts.
OCR signifie reconnaissance optique de caractères ou Optical Character Recognition en anglais. C'est une technologie qui permet de transformer un contenu visuel (texte imprimé ou manuscrit) en texte numérique interprétable par un ordinateur. Autrement dit, l'OCR permet d'extraire du texte ou des informations figurant sur une photo, un scan ou un PDF non modifiable.
Cette capacité à convertir des données analogiques en ressources numériques est d’ailleurs un levier stratégique pour la transformation digitale, comme le souligne cet article de McKinsey.
Un logiciel OCR est un outil qui permet d’appliquer cette technologie sur vos documents. Il prend en entrée un fichier image ou PDF non modifiable, et génère un texte structuré en sortie.
Certains logiciels OCR se contentent de copier le texte : vous passez d'un document PDF non éditable au même fichier éditable comme un document Word.
D’autres vont plus loin : ils détectent automatiquement des champs clés (noms, dates, montants), exportent les données vers Excel ou une base de données, et peuvent même s’intégrer à vos outils métier via API.
Il existe des solutions locales (dites "on premise"). Mais les plus performantes fonctionnent en majorité en ligne, via une connexion internet, étant donné qu'elles s'appuient souvent sur algorithmes de machine learning ou des LLMs gourmands en capacité de calcul.
Cette vidéo explique de manière simple ce qu’est l’OCR, son fonctionnement et ses principaux cas d’usage.
Un bon outil OCR permet avant tout d’éviter la ressaisie manuelle, longue et source d’erreurs. Il extrait automatiquement les informations importantes contenues dans vos documents (PDF, images scannées…) pour les organiser dans un fichier Excel ou les envoyer directement dans vos outils métier.
L’OCR permet ainsi de fiabiliser, accélérer et automatiser vos workflows documentaires, en particulier dans les échanges avec vos clients, fournisseurs ou prestataires.
Une fois les données extraites, elles deviennent une source précieuse pour vos contrôles, vérifications ou analyses, que ce soit en comptabilité, en audit ou en gestion opérationnelle.
Un logiciel OCR repose sur un ensemble de technologies :
Vision par ordinateur pour analyser l’image et identifier les formes du texte, les lignes, et les caractères.
Traitement du langage naturel pour comprendre le contexte du texte et ses informations d’intérêt. Par exemple, le système doit comprendre qu’une suite de caractères est une date, un nom, ou un montant dans le contexte du document et comment réagir en fonction.
Le processus OCR est généralement le suivant :
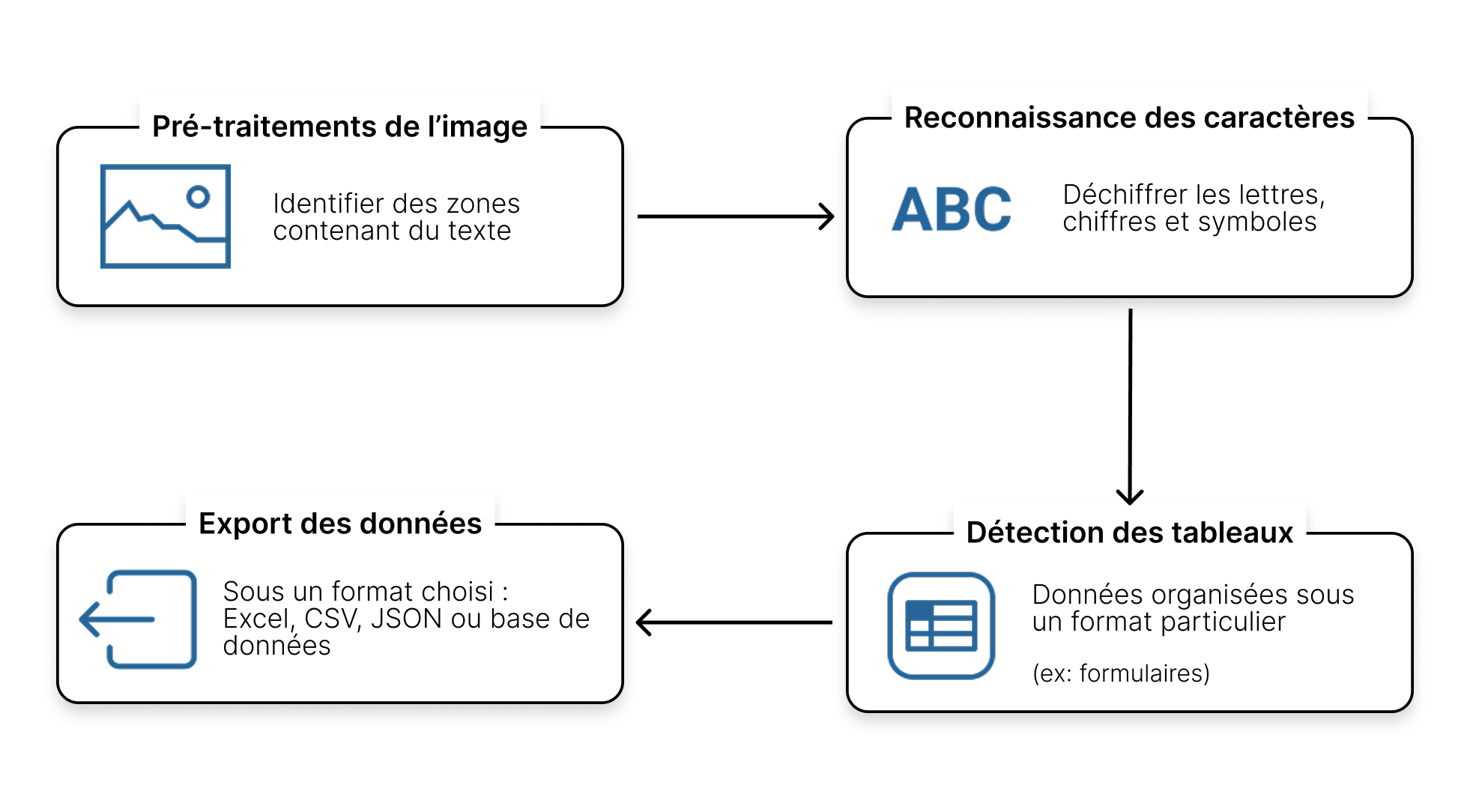
Aujourd’hui, les nouveaux outils OCR s’appuient également sur les LLMs (les technologies sous-jacentes à ChatGPT, Gemini ou Claude) pour reconnaître plus précisément les textes complexes, manuscrits ou mal scannés.
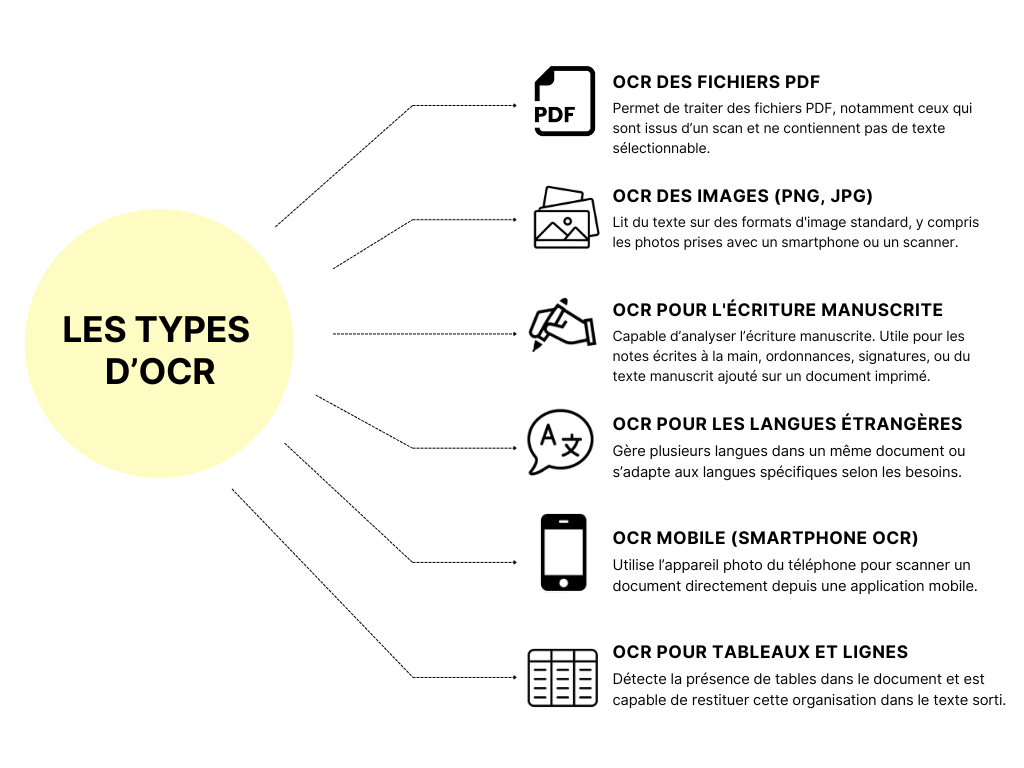
Une API OCR (interface de programmation applicative) permet d'océriser automatiquement des documents en appelant un service en ligne, sans passer par une interface utilisateur. En d’autres termes, elle donne à vos logiciels la capacité de lire, extraire et structurer du texte à la volée, depuis un document PDF, une image ou une photo.
C’est la solution idéale pour intégrer l’OCR directement dans un logiciel métier, automatiser la saisie de données, ou créer des flux documentaires 100 % digitaux — sans intervention humaine. Une bonne API OCR offre souvent des options de personnalisation (champs à extraire, langue, format de sortie) et s’intègre facilement à votre SI ou à des outils comme Zapier, Make, ou des ERP/CRM internes.
Si le cas le plus courant reste l’OCR pour factures fournisseurs, cette technologie s’adapte désormais à une grande variété de documents professionnels, qu’ils soient structurés, semi-structurés ou complètement libres. Grâce à l’intelligence artificielle, les outils modernes sont capables d’extraire des données même dans des formats complexes ou hétérogènes.
La majorité des outils comptables sont équipés d'une solution OCR comptabilité, capable de reconnaitre les principaux champs d'une facture pour la saisie comptable.
La même technologie fonctionne sur bons de commande, les devis, les bons de livraison, ou les relevés bancaires pour la gestion plus opérationnelle. De même, il est désormais possible de capter des informations dans des documents plus longs tels que les comptes d’entreprise, les rapports et états financiers. L’OCR permet d’automatiser l’entrée de données et d’alimenter vos outils comptables avec précision.
Liasses fiscales (BIC, BNC, SCI…), déclarations d’impôts, correspondances administratives : autant de documents où l’OCR facilite la centralisation, l’archivage et la conformité réglementaire.
CV, fiches de paie, contrats de travail, avenants, arrêts de travail… L’OCR structure vos données RH et alimente automatiquement vos SIRH, en réduisant la charge administrative.
Factures de transport (routier, maritime, express…), bons de livraison, CMR, lettres de voiture, connaissements maritimes (bills of lading) : des documents souvent non normalisés, que l’OCR rend exploitables pour le rapprochement logistique ou la traçabilité.
Compromis ou promesses de vente, baux commerciaux ou , diagnostics de performance énergétique (DPE), états des lieux… L’OCR permet d’en extraire les clauses clés et de fiabiliser la gestion documentaire.
Ordonnances médicales, cartes Vitales, feuilles de soins, résultats d’analyse, certificats médicaux… L’extraction OCR simplifie la gestion des dossiers patients ou des remboursements pour les assureurs.
Tickets de caisse, reçus, étiquettes produits, codes-barres : l’OCR permet d’analyser les ventes, suivre les prix ou vérifier la conformité des documents commerciaux.
Pour les documents plus longs ou denses comme les compromis de vente ou les contrats juridiques, il s’agit davantage d’une solution de captation de données intelligente que d’un simple OCR. L’enjeu est de comprendre, contextualiser et structurer l’information clef disséminée dans un volume important de texte.
Grâce à la modularité des outils actuels, vous pouvez également traiter des documents hors de cette liste, en définissant les champs que vous souhaitez extraire. L’OCR s’adapte à vos cas d’usage, même les plus spécifiques.
L'OCR est souvent un élément clef de l'automatisation des documents dans votre entreprise.
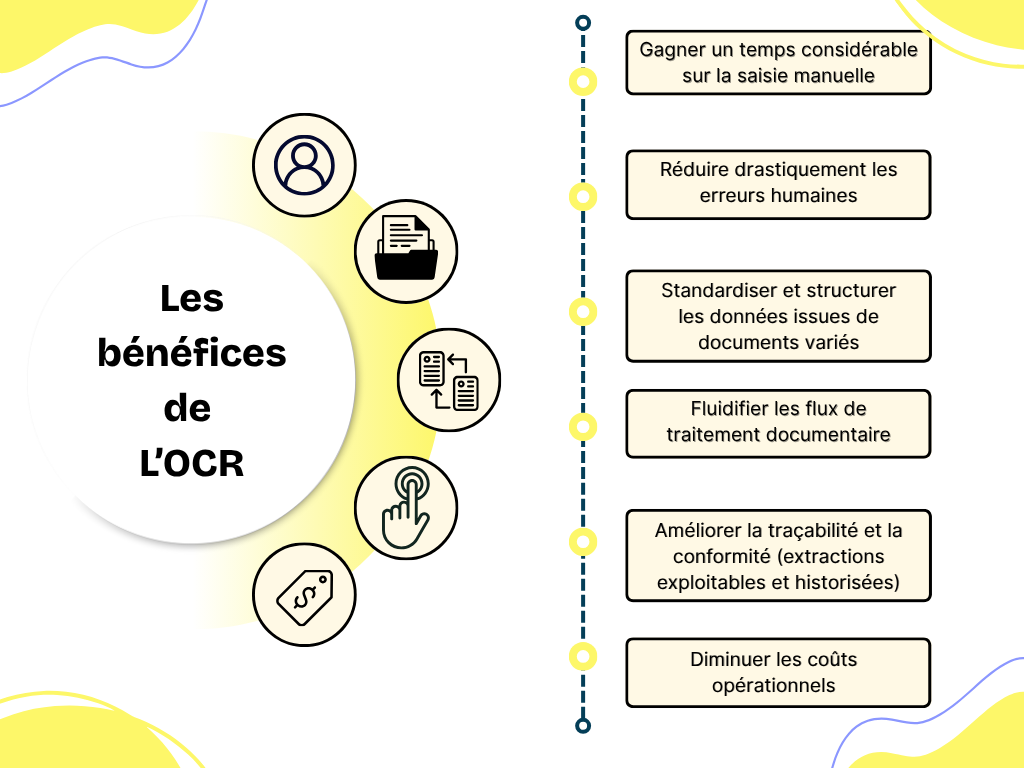
Dans un contexte professionnel, un OCR permet de transformer une charge administrative en un levier d’efficacité.
Un OCR classique se limite à détecter et convertir du texte brut. Il ne fait aucune distinction contextuelle, ne comprend pas les données extraites, et ne peut pas les structurer avec précision.
À l’inverse, un OCR propulsé par l’intelligence artificielle (IA), comme Koncile, est capable de :
L’OCR IA ne se contente pas d’extraire : il interprète, contrôle et valorise les données.
Avant de choisir une technologie OCR, posez-vous les bonnes questions :
Il n’existe pas de “meilleur” outil universel, mais plutôt des solutions adaptées à chaque usage :

Idéal pour les entreprises ayant besoin de traiter des volumes importants de documents (factures, contrats, justificatifs, etc.). Solution clé en main, personnalisable et intégrable via API.

Moteur OCR open source recommandé pour les développeurs souhaitant intégrer l’OCR dans leurs propres applications. Puissant, mais nécessite une bonne maîtrise technique.

Pratique pour un usage ponctuel, comme extraire le texte d’un PDF scanné ou convertir un document en Word. Facile à utiliser, mais peu flexible pour des traitements complexes ou en masse.
Le choix de l’outil dépend donc avant tout de votre niveau technique, du volume de documents à traiter, et des besoins spécifiques de votre organisation.
Il existe de nombreux outils d’OCR gratuits accessibles en ligne, parfaits pour des besoins ponctuels ou des tests. Ces solutions permettent souvent de convertir une image ou un PDF en texte en quelques clics, sans installation ni inscription. Parmi les plus connus : Online OCR, i2OCR ou encore Google Docs, qui intègre une fonction OCR de base.
Les OCR en ligne sont accessibles via un navigateur web et conviennent bien pour des documents simples. Ils sont faciles à utiliser mais peuvent être limités en termes de volume, de langues prises en charge ou de respect de la confidentialité (surtout si les données sont sensibles).
Pour un usage professionnel ou à grande échelle, il est recommandé d’opter pour un OCR plus robuste, sécurisé, et intégrable à vos outils via API.
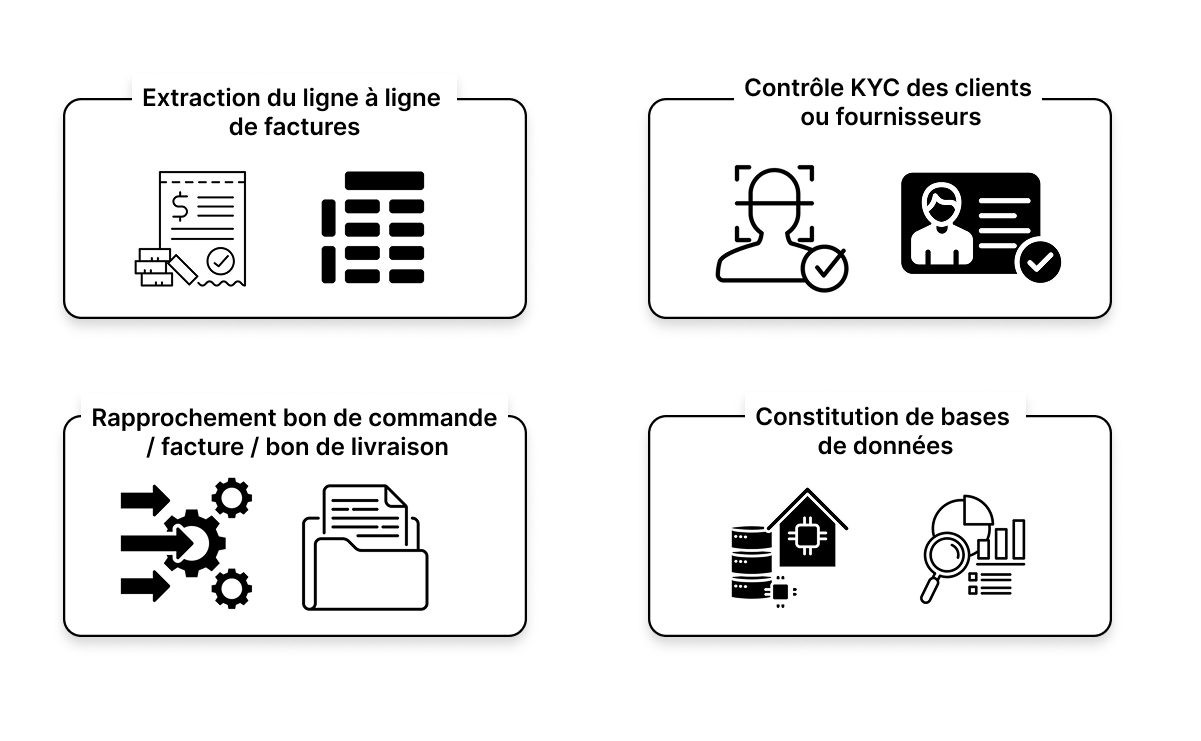
L'OCR extrait chaque ligne de factures et les restitue sous forme d'un tableau organisé reprenant chaque colonne. Vous avez accès à un tableau complet des éléments facturés, avec le libellé, le prix, la quantité, le conditionnement, etc.
Ces tableaux peuvent notamment être utilisés pour effectuer des croisements avec une grille tarifaire pour contrôler les prix
L'OCR extrait les informations clefs des cartes d'identité, passeports, Kbis, formulaires soumis par les clients ou fournisseurs. Une des données extraites sert de "pont" pour lier à votre base de données afin de vérifier si la personne ou entité est déjà dans votre CRM. Vous détectez des potentielles anomalies liées à la date de naissance, l'adresse pour idenfier des potentielles soumissions frauduleuses.
L’OCR permet d’extraire automatiquement les données présentes sur les bons de commande, les factures et les bons de livraison pour les croiser entre eux. Cela permet de vérifier les écarts entre ce qui a été commandé, livré et facturé, et ainsi automatiser les contrôles de conformité ou les workflows de validation. C’est particulièrement utile dans des contextes logistiques complexes ou multi-prestataires.
L’OCR transforme vos documents papier ou PDF en données structurées exploitables dans une base de données (Excel, SQL, CRM, etc.). Cette fonctionnalité permet de créer ou enrichir automatiquement un référentiel à partir de contrats, fiches produits, rapports techniques, documents RH… Plus besoin de saisie manuelle : vous alimentez directement vos outils avec des données fiables et triées.
Pour convertir une image (JPEG, PNG, TIFF, etc.) en texte, il faut utiliser un logiciel OCR. L’outil détecte les caractères présents dans l’image et les transforme en texte numérique. Le résultat peut ensuite être exporté dans un fichier Word, Excel, PDF éditable ou directement intégré à une base de données.
La première étape consiste à numériser votre document à l’aide d’un scanner ou d’un smartphone. Une fois le fichier (souvent en PDF ou en image) obtenu, vous l’importez dans un logiciel OCR qui va extraire automatiquement le texte qu’il contient. Certains scanners professionnels intègrent directement un moteur OCR pour produire un document éditable.
Oui, Google Drive intègre une fonction OCR. Si vous importez une image ou un PDF dans votre Drive, puis l’ouvrez avec Google Docs, le système convertit automatiquement le contenu en texte modifiable. Cette fonction est gratuite, mais reste limitée pour les documents complexes, les tableaux ou les contenus peu lisibles.
Le scan crée une image numérique du document, mais le contenu reste figé et non modifiable.
L’OCR va plus loin : il analyse cette image pour en extraire le texte, permettant ensuite de le copier, le modifier, ou l’exploiter dans des outils métiers. En résumé : le scan photographie, l’OCR interprète.
Tout dépend de la qualité du document et du moteur utilisé. Sur du texte imprimé clair et bien scanné, un OCR peut atteindre un taux de précision de 98 à 99 %. En revanche, ce taux baisse si le document est flou, mal cadré, ou si le texte est manuscrit. Les moteurs utilisant l’intelligence artificielle (OCR IA) offrent les meilleurs résultats sur des documents réels et variés.
Oui, mais uniquement s’il s’agit d’un moteur d’OCR avancé, capable de reconnaitre l’écriture manuscrite. On parle alors d’ICR (Intelligent Character Recognition). Ces solutions peuvent reconnaître des formulaires remplis à la main, des signatures ou des notes manuscrites, avec un certain niveau de fiabilité selon la lisibilité de l’écriture.
Oui. Les meilleurs moteurs OCR prennent en charge plusieurs langues simultanément, y compris au sein d’un même document. Il est souvent possible de spécifier les langues à traiter dans les paramètres, ou de laisser le système les détecter automatiquement.
Oui. De nombreuses solutions OCR sont disponibles en version locale (on-premise), installées sur vos serveurs ou ordinateurs. Cela permet un traitement sans connexion internet, idéal pour les environnements sensibles (santé, défense, juridique) ou pour répondre à des contraintes de confidentialité ou de souveraineté des données.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs

Cinq solutions OCR françaises comparées pour extraire vos données documentaires en toute conformité RGPD, serveurs hébergés en France.
Comparatifs
.png)


