


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité
.webp)
Dernière mise à jour :
January 9, 2026
5 minutes
L’automatisation de la gestion administrative n’est plus un luxe, mais une nécessité. Parmi les tâches chronophages, l’extraction de données de factures figure en tête de liste. Les modèles de langage de grande taille (LLM, pour Large Language Models) tels que Claude (Anthropic), GPT (OpenAI) et Gemini (Google DeepMind) se positionnent comme des solutions puissantes pour transformer un document non structuré en données exploitables.Mais lequel est le plus performant ? Pour répondre, nous avons analysé leur précision, rapidité, coût, sécurité et facilité d’intégration.
Comparatif GPT, Claude et Gemini pour l’extraction de factures, selon précision, coûts, vitesse, sécurité et intégration.
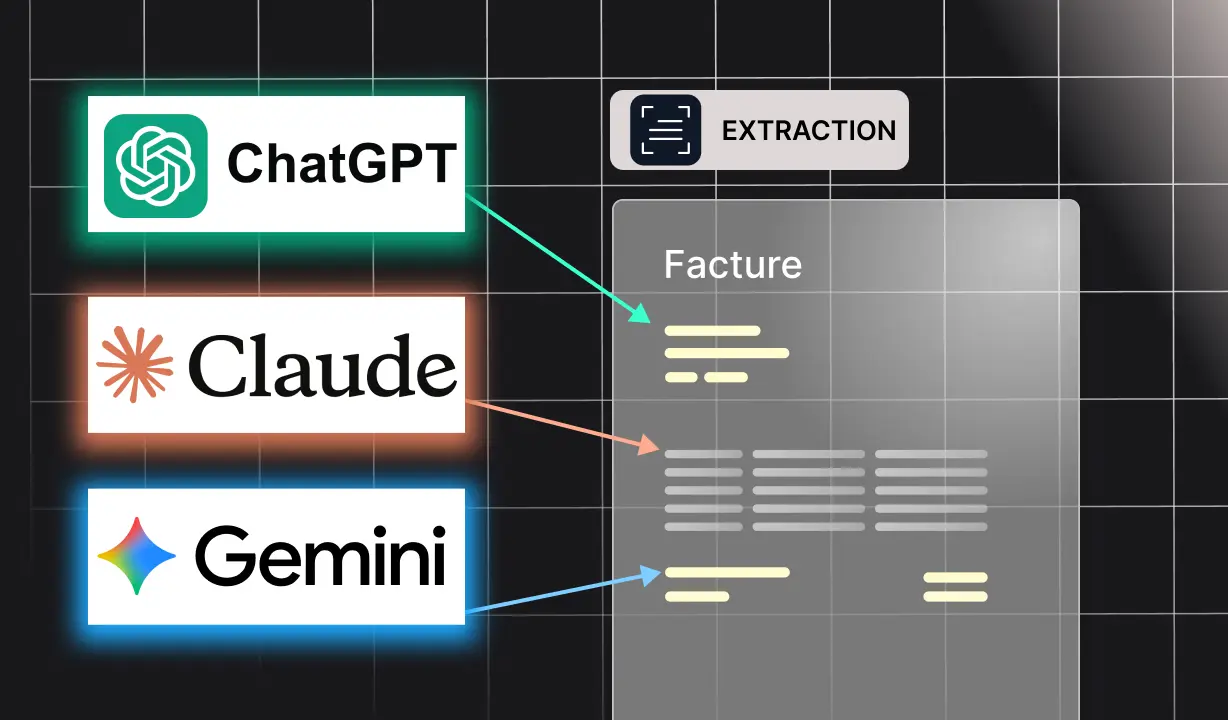
Un LLM (Large Language Model) est un modèle d’intelligence artificielle entraîné à comprendre et générer du langage naturel. Lorsqu’on l’applique au domaine des documents financiers, il devient capable d’extraire des informations précises et structurées à partir de contenus complexes. Concrètement, il peut identifier des champs clés tels que la date, le numéro de facture, les montants hors taxes, la TVA ou encore le total TTC. Il sait également interpréter le contexte, par exemple distinguer un numéro de client d’un numéro de facture, et organiser les données extraites dans des formats standards comme JSON, CSV ou XML, directement exploitables dans un ERP.
Le processus d’extraction d’une facture passe généralement par deux étapes principales. La première est l’OCR (Reconnaissance Optique de Caractères), qui permet de convertir une image ou un PDF scanné en texte brut exploitable par un système informatique. La seconde est le parsing via un LLM, qui analyse le texte obtenu et le structure dans un format normalisé et prêt à être intégré à un outil de gestion. Ce duo technologique est aujourd’hui au cœur de nombreux workflows financiers automatisés.

Pour les entreprises, l’enjeu ne se limite pas à l’extraction pure : il s’agit de minimiser les erreurs de lecture, de traiter rapidement un grand volume de documents, tout en garantissant la confidentialité et la conformité aux réglementations comme le RGPD. Un outil performant doit donc combiner robustesse technique, vitesse d’exécution et respect des standards de sécurité des données.
GPT se distingue par une excellente compréhension contextuelle et une capacité à produire des sorties formatées de manière fiable. Sa vaste documentation et son écosystème mature facilitent l’intégration dans des pipelines existants. Ses limites résident dans sa dépendance à un OCR externe pour les documents scannés, ainsi que dans un coût qui peut devenir élevé en cas de traitement massif.
Claude excelle dans le respect des formats, la prudence dans le traitement de données sensibles et la gestion de structures complexes. Il se montre particulièrement adapté aux environnements où la conformité et la rigueur sont essentielles. En revanche, il dispose de moins d’intégrations natives avec des solutions OCR, ce qui peut nécessiter des ajustements supplémentaires.
Gemini apporte un avantage clé : la capacité à traiter simultanément du texte et des images, ce qui lui permet d’intégrer nativement l’OCR grâce à Google Cloud Vision. Sa rapidité de traitement et son intégration fluide avec l’écosystème Google en font une option particulièrement compétitive. Cependant, son environnement plus fermé et sa dépendance à Google Cloud peuvent limiter certaines flexibilités d’implémentation.
Pour évaluer ces trois modèles, nous avons constitué un jeu de données comprenant 300 factures PDF textuelles et 200 factures scannées, volontairement variées en termes de qualité (résolution faible, angles biaisés, etc.). Les critères d’évaluation incluaient la précision d’extraction, la capacité multimodale, le temps de traitement, le coût par facture et le respect des formats structurés. Nous avons également pris en compte les aspects de conformité et de sécurité.
Sur des PDF textuels, GPT a atteint une précision de 98 %, suivi de près par Claude (97 %) et Gemini (96 %). Claude s’est distingué par une meilleure cohérence de format, tandis que Gemini s’est montré très régulier même sur des mises en page atypiques.
Gemini a dominé ce test avec 94 % de précision, grâce à sa vision intégrée. GPT, couplé à un OCR comme Tesseract ou Google Vision, a atteint 91 %, tandis que Claude, également dépendant d’un OCR externe, a obtenu 90 %, avec une moindre tolérance aux imperfections de scan.
Claude a offert la meilleure régularité de format (JSON valide en toutes circonstances). GPT a montré d’excellents résultats mais, en très haute volumétrie, quelques erreurs de syntaxe ont été relevées. Gemini s’est révélé fiable, bien que nécessitant parfois un léger post-traitement.
Pour estimer le coût de traitement de 1 000 factures via les API de ChatGPT (OpenAI), Gemini (Google) et Claude (Anthropic), nous avons défini une hypothèse commune permettant de comparer équitablement les trois modèles.
Une facture type, une fois le texte extrait grâce à un OCR, comprend deux éléments envoyés au modèle :
Ainsi, le total estimé par facture est d’environ 2 500 tokens. Ce volume n’est toutefois qu’une moyenne : une facture simple d’une seule page avec peu de lignes sera plus légère, tandis qu’un document multi-pages avec de nombreux articles sera plus lourd à traiter.
Sur cette base, nous avons calculé le coût pour 1 000 factures, en utilisant les tarifs Pay-as-you-go (paiement à l’usage) en vigueur en août 2025 pour chaque API. Les prix sont présentés initialement en dollars, puis convertis en euros à un taux indicatif de 1 $ = 0,92 €.
Claude se distingue par une politique stricte : les données ne sont pas utilisées pour l’entraînement par défaut. GPT permet un opt-out, mais nécessite une configuration spécifique. Gemini dépend des paramètres Google Cloud, avec un stockage temporaire possible. Côté certifications, Gemini est conforme ISO 27001, mais le lieu d’hébergement peut poser question selon les régions.
GPT et Claude offrent des API robustes et compatibles avec de nombreux langages (Python, Node.js, Java, .NET), mais nécessitent un OCR externe pour les documents scannés. Gemini, avec sa vision intégrée, s’impose comme un choix naturel si l’entreprise est déjà sur Google Cloud.
Le choix du modèle dépendra avant tout de votre contexte. Pour des PDF textuels, GPT et Claude sont d’excellentes options. Si vous devez traiter un volume important de documents scannés, Gemini est le plus adapté. Enfin, si la conformité et la sécurité sont prioritaires, Claude se positionne comme la meilleure alternative.
Aucun LLM ne surpasse tous les autres dans tous les scénarios d’extraction de factures. GPT, Claude et Gemini présentent chacun des atouts spécifiques qui répondent à des besoins distincts : la polyvalence et la maturité pour GPT, la rigueur et la sécurité pour Claude, la multimodalité et la rapidité pour Gemini. L’évaluation préalable de vos documents, volumes et contraintes réglementaires sera donc essentielle pour orienter votre choix.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Tristan Thommen conçoit et déploie les briques technologiques qui transforment des documents non structurés en données exploitables. Il allie IA, OCR et logique métier pour simplifier la vie des équipes.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


