


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité
.avif)
Dernière mise à jour :
December 24, 2025
5 minutes
DeepSeek OCR attire l’attention par ses performances sur les documents longs, mais son fonctionnement reste souvent opaque ou complexe à comprendre. Cet article propose une lecture claire et progressive de son architecture, de la compression du contexte et de leurs implications concrètes pour l’OCR.
Une explication claire et structurée de DeepSeek OCR et de son approche du contexte documentaire.

Les systèmes OCR récents ne se distinguent plus uniquement par leur capacité à reconnaître du texte, mais par leur aptitude à gérer des documents longs, complexes et hétérogènes sans exploser les coûts de calcul. DeepSeek-OCR s’inscrit dans cette évolution en proposant une approche centrée sur la compression du contexte visuel et l’efficacité à l’inférence.
Dans de nombreux cas d’usage, les documents ne se résument pas à une page isolée. Dossiers administratifs, contrats, archives ou formulaires multi-pages posent un problème récurrent : plus le document est long, plus le coût mémoire et le risque de perte de contexte augmentent.
Les approches OCR classiques ou même certaines solutions basées sur des modèles multimodaux traitent ces documents par découpage ou par fenêtres de contexte limitées. Cette méthode fonctionne, mais introduit des ruptures de compréhension entre les pages ou les sections éloignées.
Ces différentes techniques bien que très standardisées restent faibles sur un point : la gestion de contextes long.
La difficulté n’est pas uniquement de lire le texte, mais de maintenir une cohérence globale sur l’ensemble du document. Champs dépendants, références croisées, informations réparties sur plusieurs pages nécessitent une représentation compacte mais fidèle du contenu visuel et textuel.
C’est sur ce point précis que DeepSeek-OCR positionne sa proposition technique.
DeepSeek-OCR met en avant des résultats élevés sur des benchmarks spécialisés, notamment sur le dataset FOX, souvent utilisé pour évaluer l’extraction d’informations dans des documents administratifs structurés. Ce type d’évaluation s’inscrit dans une logique plus large d’intelligent document processing, où l’enjeu n’est plus seulement de lire le texte, mais d’en extraire des informations fiables et actionnables.
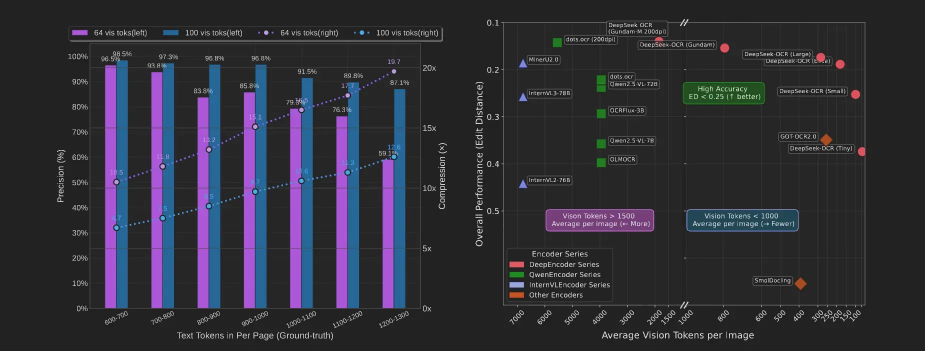
Le dataset FOX se concentre sur des documents à forte densité informationnelle, avec des structures répétitives, des entités nommées et des relations implicites. De bons résultats sur ce type de benchmark indiquent une capacité à comprendre la structure globale d’un document, au-delà de la simple reconnaissance de caractères.
Le tableau permet de comparer les performances annoncées selon plusieurs critères : précision, type de documents, longueur moyenne des entrées et hypothèses de test.
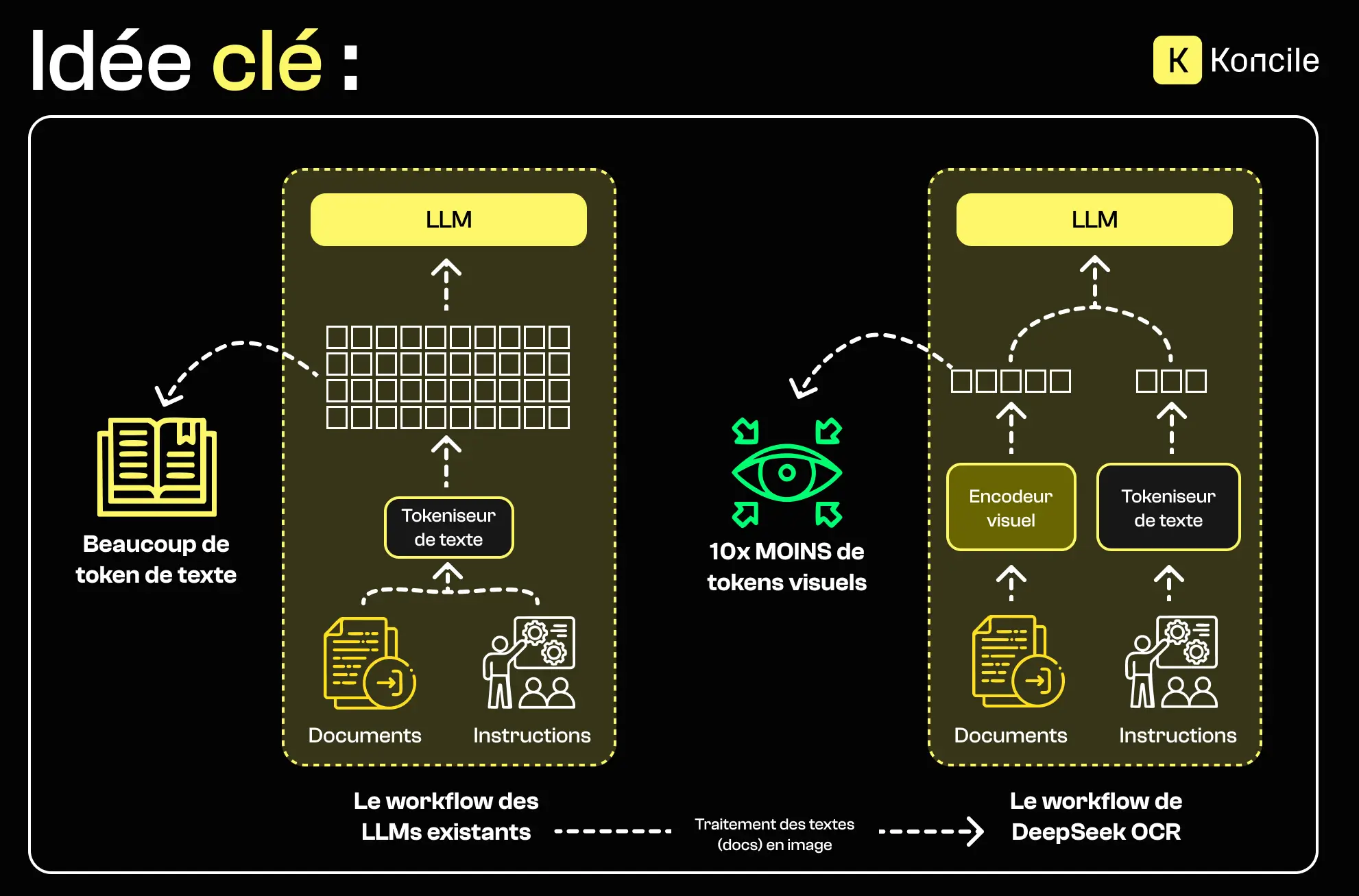
Lorsque DeepSeek-OCR évoque une compression “10x”, il ne s’agit pas de compresser les fichiers sources, mais de réduire la taille des représentations internes utilisées par le modèle "les tokens". L’objectif est de conserver l’essentiel de l’information tout en limitant la mémoire nécessaire pour traiter des contextes longs.
L’architecture de DeepSeek-OCR repose sur une séparation claire entre l’encodage visuel et le décodage textuel, reliés par un mécanisme de compression des représentations.
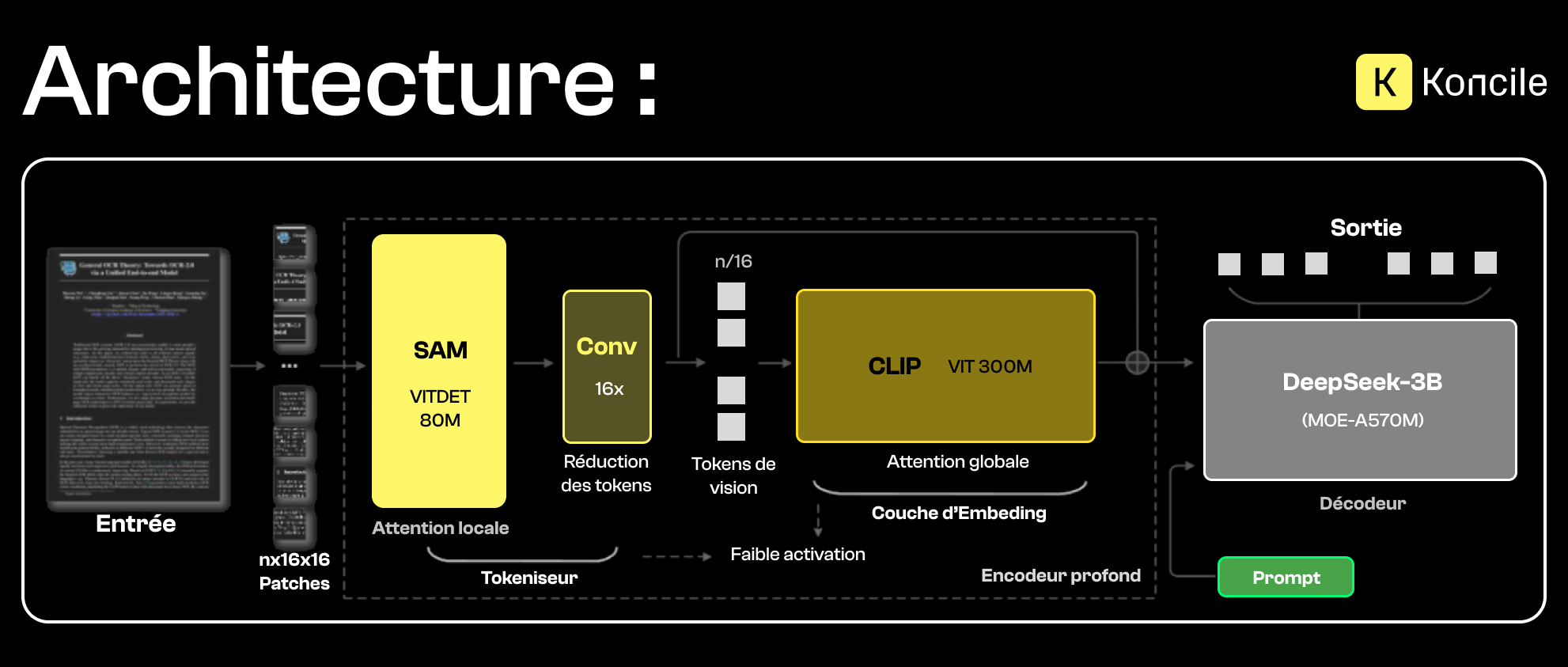
L’encodeur de DeepSeek-OCR repose sur deux composants complémentaires, conçus pour traiter l’information visuelle à différents niveaux.
D’un côté, SAM (Segment Anything Model) est utilisé pour la segmentation et l’analyse locale de l’image. Grâce à son mécanisme d’attention locale, il permet d’identifier avec précision les zones pertinentes du document, comme les blocs de texte, les tableaux, les marges ou les séparations visuelles. Cette étape est essentielle pour capter les détails fins, les contours et la structure spatiale du document.

De l’autre côté, CLIP (Contrastive Language–Image Pretraining) intervient pour apporter une compréhension plus globale et sémantique. Contrairement à SAM, CLIP ne se concentre pas sur les détails locaux, mais sur le sens général du contenu visuel. Il projette l’image dans un espace sémantique partagé avec le langage, ce qui permet d’associer les régions détectées à des concepts, des intentions ou des structures documentaires plus larges.

La combinaison de ces deux approches permet à DeepSeek-OCR de produire une représentation visuelle à la fois précise et contextualisée. SAM fournit une lecture fine et structurée du document, tandis que CLIP en assure l’interprétation globale. Cette représentation enrichie sert ensuite de base à la compression contextuelle et à la génération de texte, avant toute intervention du décodeur.
Un MoE, ou “Mixture of Experts”, est une architecture de modèles d’IA de plus en plus répandue. Comme son nom l’indique, elle peut être vue comme un mélange d’experts, chacun spécialisé dans un domaine spécifique. Par définition, chaque “expert” est un sous-réseau, et l’ensemble est piloté par un “chef d’orchestre”, à savoir un routeur intelligent.
L’idée est de ne mobiliser que les ressources essentielles à la requête de l’utilisateur, afin d’éviter des calculs inutiles. Cette approche présente également d’autres avantages, comme la possibilité de créer des modèles très volumineux, avec un nombre total de paramètres extrêmement élevé sans forcément augmenter le coût à l'inférence. Les experts se spécialisent fortement dans leur domaine respectif, ce qui renforce la qualité des réponses produites. Enfin, à densité et taille comparables, les architectures MoE offrent généralement une vitesse d’inférence supérieure à celle des modèles denses.
Pour conclure, c’est comme si vous alliez à l’hôpital pour un problème de santé et que l’on vous redirigeait vers l’un des services les plus adaptés, plutôt que de consulter un médecin généraliste, compétent dans de nombreux domaines mais expert dans aucun en particulier.
Une architecture MoE améliore l’efficacité à l’inférence, mais sa qualité dépend fortement du routage et des données utilisées.
Ces indicateurs donnent une première lecture des gains annoncés, mais ils prennent tout leur sens une fois le mécanisme sous-jacent compris. Le tableau ci-dessous synthétise ces métriques clés, avant d’expliquer le rôle de l’architecture Mixture of Experts dans cette efficacité.
Le traitement commence par un découpage de l’image en patches. Ces éléments sont analysés localement afin d’extraire les structures visuelles pertinentes. Une étape de compression réduit ensuite la dimension des représentations avant leur contextualisation globale.
Cette chaîne de traitement vise à limiter la redondance tout en préservant les relations importantes entre les différentes zones du document.
DeepSeek-OCR intègre des mécanismes d’attention optimisés, conçus pour réduire l’empreinte mémoire associée au traitement de contextes longs. Ces optimisations permettent de maintenir des performances stables lorsque la taille des documents augmente.
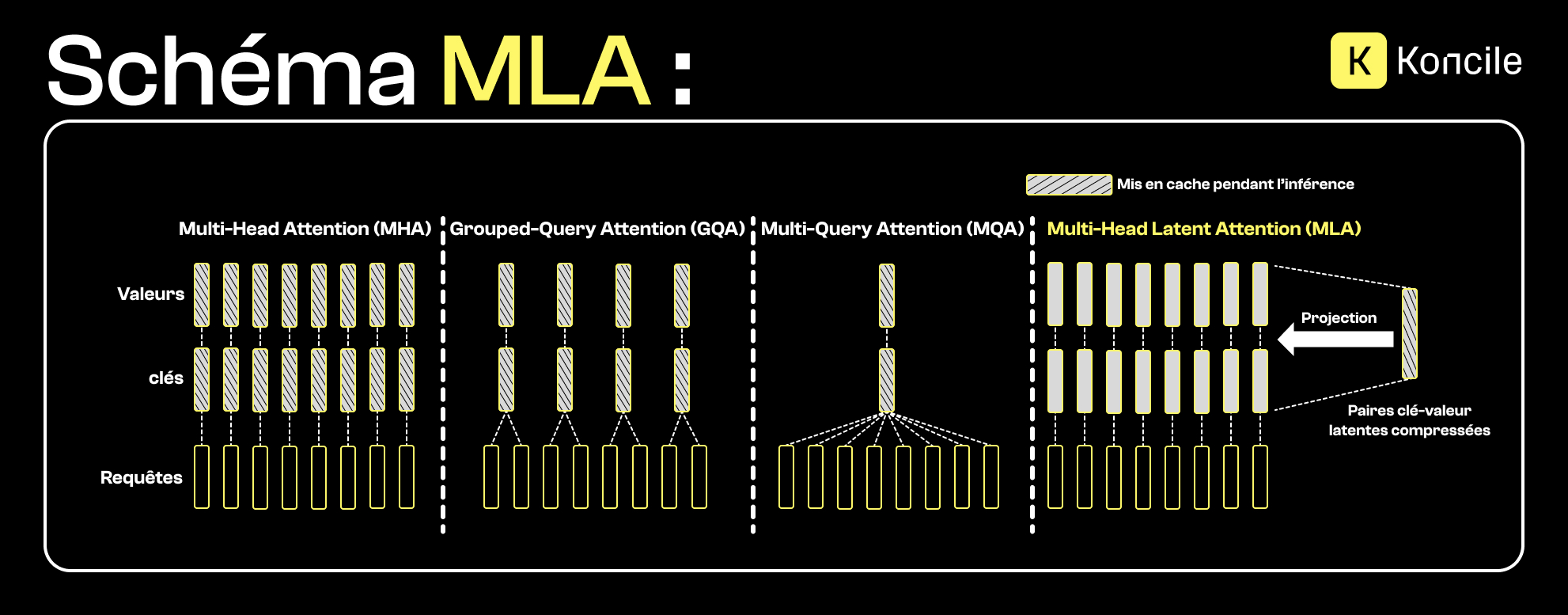
Avant d’introduire Flash MLA, il est important de comprendre le principe de la Multi-Head Latent Attention (MLA).
Contrairement aux mécanismes d’attention classiques, où les clés et valeurs (KV) sont stockées explicitement pour chaque tête d’attention, la MLA projette ces informations dans un espace latent compressé. Cette projection permet de conserver les relations essentielles entre les tokens tout en réduisant drastiquement la taille du cache mémoire nécessaire à l’inférence.
En pratique, la MLA représente une évolution des approches comme la Multi-Query Attention (MQA) ou la Grouped-Query Attention (GQA). Là où ces méthodes partagent partiellement les clés et valeurs, la MLA va plus loin en compressant leur représentation elle-même. Cette approche est particulièrement adaptée aux contextes longs, où le coût mémoire du cache KV devient un facteur limitant.
DeepSeek-OCR utilise Flash MLA, une version optimisée du mécanisme d'attention multi-têtes latente. Cette implémentation exploite les kernels GPU NVIDIA pour accélérer les calculs tout en réduisant la mémoire nécessaire pour le cache KV. Les performances restent stables même avec des réductions de mémoire importantes.
Les bénéfices de Flash MLA sont multiples. La mémoire requise diminue jusqu'à 6,7% sans impact sur la qualité. Le problème du "perdu au milieu" est atténué significativement. Les contextes longs peuvent être traités sans saturation mémoire. L'efficacité énergétique s'améliore proportionnellement.
Les documents volumineux, peu standardisés ou riches en dépendances internes peuvent bénéficier d’une meilleure gestion du contexte global. Archives, dossiers juridiques ou rapports multi-sections entrent souvent dans cette catégorie.
Sur des documents courts, très structurés ou déjà bien segmentés, les bénéfices d’une compression contextuelle avancée peuvent être marginaux. Le coût d’intégration et de maintenance doit alors être mis en balance avec le gain réel.
Comme toute approche avancée, DeepSeek-OCR présente certaines contraintes. La compression peut entraîner une perte d’informations fines dans des cas spécifiques. L’architecture repose également sur plusieurs composants pré-entraînés, ce qui peut compliquer l’adaptation à des contextes très spécifiques.
Enfin, la complexité technique du déploiement et de l’optimisation reste un facteur à considérer dans un environnement de production.
Dans des environnements de production, ces avancées soulèvent aussi une autre question : comment transformer ces capacités techniques en systèmes fiables, contrôlables et exploitables à grande échelle.
Des solutions comme Koncile s’inscrivent dans cette logique. On ne recherche pas à maximiser la compression du contexte à tout prix. En production, la valeur vient surtout de l’intégration dans un workflow documentaire clair, on privilégie la robustesse de l’extraction, la traçabilité des champs détectés et la capacité à s’adapter à une grande variété de documents réels.
Dans ce type de système, la gestion du contexte ne repose pas uniquement sur la taille du modèle ou la compression latente, mais aussi sur des mécanismes de structuration, de validation et de contrôle métier. Cela permet de maintenir une qualité d’extraction stable, y compris sur des documents longs ou hétérogènes, sans introduire de comportements difficiles à prédire en production.
DeepSeek-OCR illustre une tendance claire de l’OCR moderne : déplacer l’effort du simple décodage visuel vers une gestion plus intelligente du contexte. En combinant encodeur vision, compression de représentation et architecture MoE, cette approche vise à traiter des documents plus longs avec une meilleure efficacité.
Avant toute adoption, il reste essentiel d’évaluer ces performances à l’aune des documents réels, des contraintes d’intégration et des objectifs métier.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


