


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
March 6, 2026
5 minutes
DeepSeek OCR is drawing attention for long-document performance, but its design often feels opaque. This article breaks down its architecture, context compression, and what it means in practice.
A clear, structured explanation of DeepSeek OCR and its approach to document context.

Modern OCR systems are no longer judged only by how well they recognize text, but by how well they handle long, complex, heterogeneous documents without blowing up compute costs. DeepSeek OCR fits into this shift with an approach centered on visual-context compression and inference efficiency.
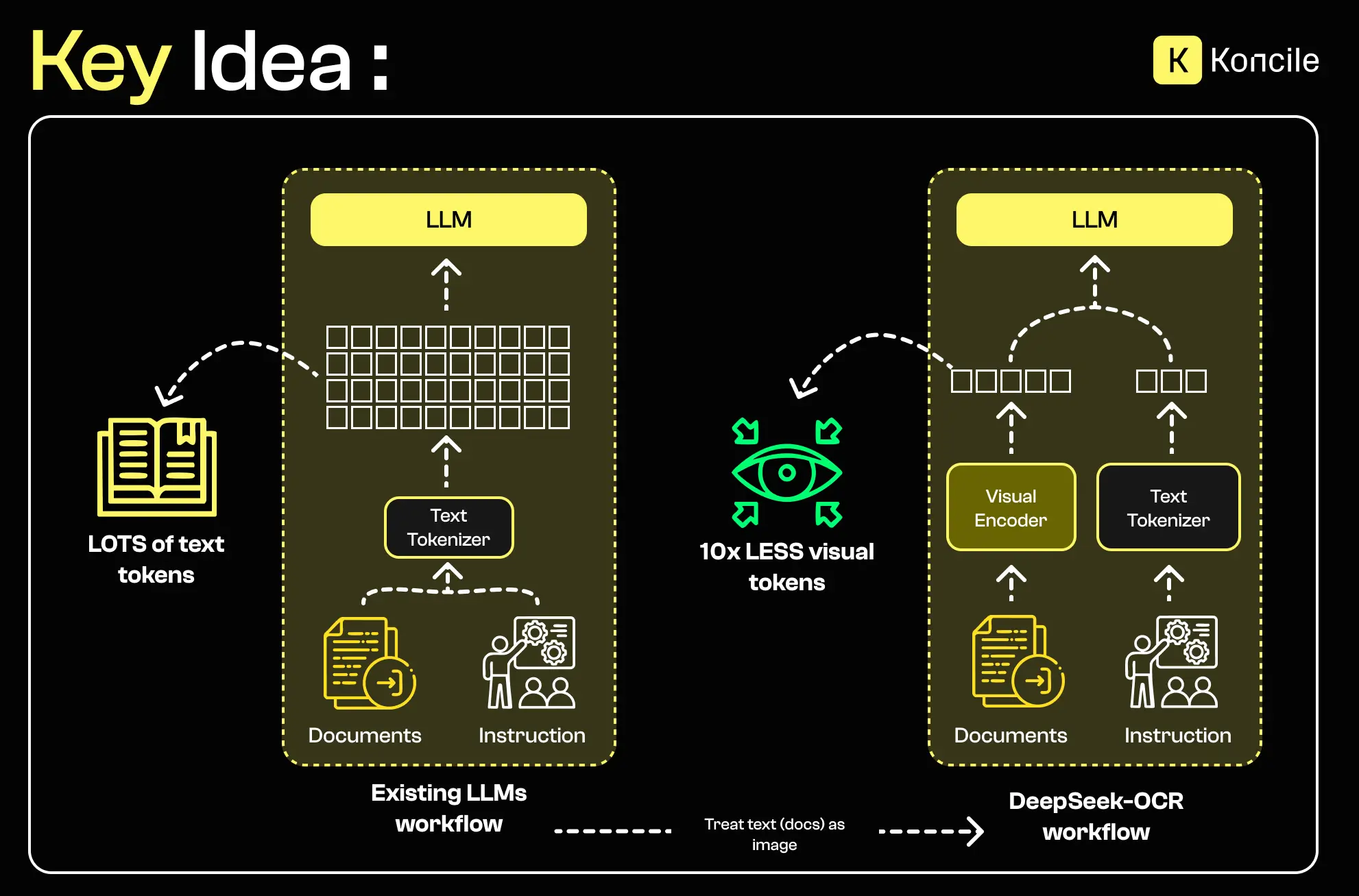
In many real-world use cases, documents are not a single isolated page. Administrative files, contracts, archives, and multi-page forms all share a recurring problem: the longer the document, the higher the memory cost and the greater the risk of losing context.
Classic OCR pipelines, and even some multimodal approaches, often handle long documents by splitting them into chunks or using limited context windows. It can work, but it introduces breaks in understanding between distant pages or sections.
These techniques are standardized and widely used, but they remain weak on one point: long-context handling.
The challenge is not only reading text, but maintaining global consistency across the entire document. Dependent fields, cross-references, and information spread across pages require a compact yet faithful representation of both the visual and textual content.
This is exactly where DeepSeek OCR positions its technical proposal.
DeepSeek OCR highlights strong results on specialized benchmarks, including the FOX dataset, often used to evaluate information extraction on structured administrative documents. This kind of evaluation sits within a broader intelligent document processing approach, where the goal is no longer just reading text, but extracting reliable, usable information.
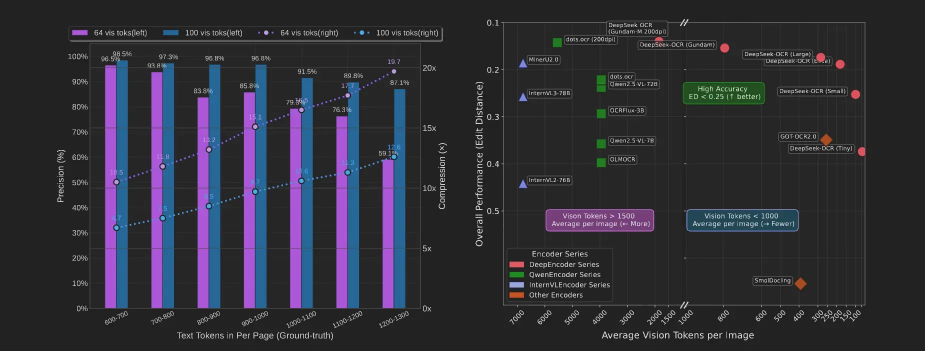
The FOX dataset focuses on high-density documents with repeated structures, named entities, and implicit relationships. Strong results on this benchmark typically indicate the ability to capture document structure beyond plain character recognition.
The table below helps compare the reported performance across several dimensions: accuracy, document type, average input length, and test assumptions.
When DeepSeek OCR mentions “10x compression,” it does not mean compressing source files. It refers to shrinking the internal representations used by the model (tokens). The goal is to preserve the essential information while reducing the memory required to process long contexts.
DeepSeek OCR separates visual encoding from text decoding, connected through a mechanism that compresses intermediate representations.
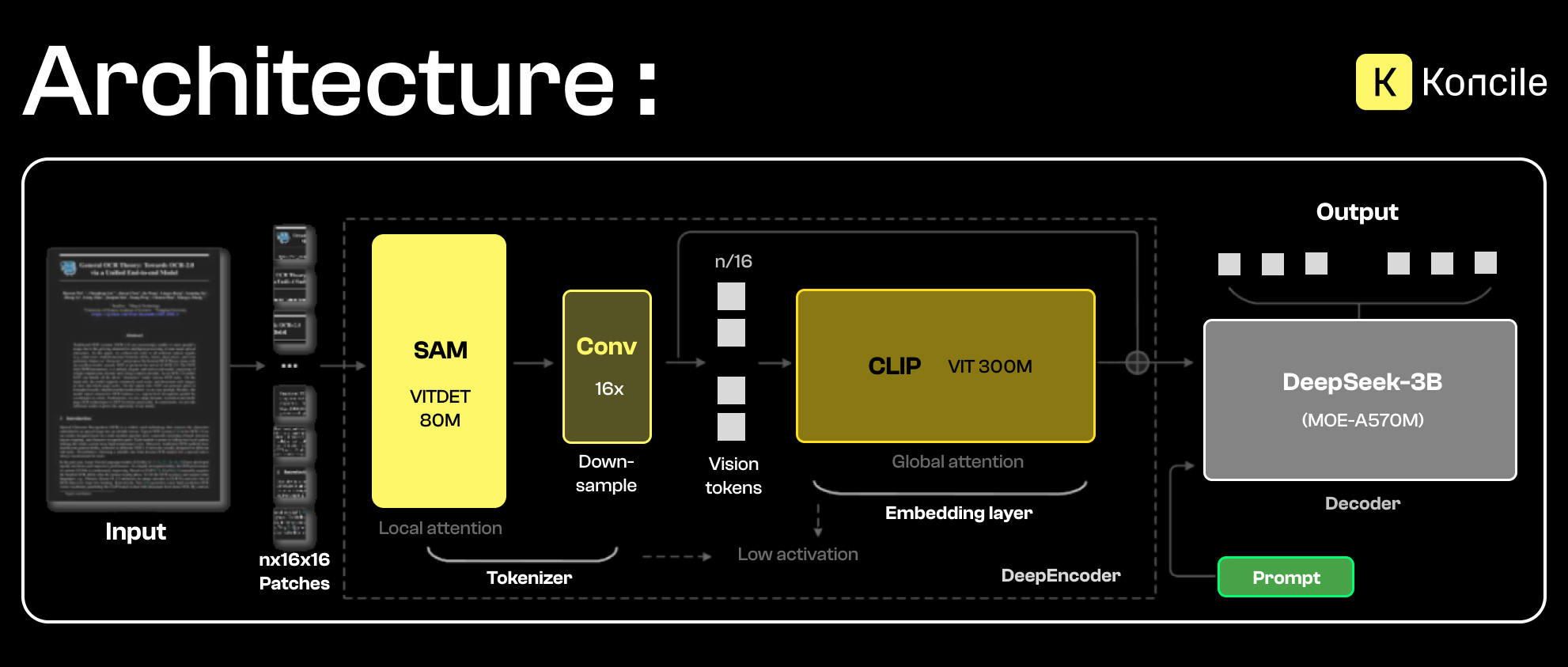
DeepSeek OCR’s vision encoder relies on two complementary components designed to process visual information at different levels.
On one side, SAM (Segment Anything Model) supports segmentation and local image analysis. Thanks to its local attention behavior, it can identify relevant regions of a document such as text blocks, tables, margins, and visual separators. This step is key to capturing fine details, contours, and spatial structure.

On the other side, CLIP (Contrastive Language–Image Pretraining) contributes a more global and semantic understanding. Unlike SAM, CLIP is not focused on local details; it maps the image into a semantic space aligned with language, which helps associate detected regions with concepts, intents, or broader document structures.

By combining both approaches, DeepSeek OCR produces a visual representation that is both precise and contextual. SAM provides a structured, fine-grained reading of the document, while CLIP supports global interpretation. This enriched representation becomes the basis for context compression and text generation, before the decoder steps in.
MoE, or Mixture of Experts, is an increasingly common model architecture. As the name suggests, it can be viewed as a mixture of specialized experts, each focused on a specific kind of pattern. Each “expert” is a sub-network, and the whole system is controlled by an intelligent router that decides which experts should process a given request.
The idea is to activate only the resources needed for the user’s request and avoid unnecessary computation. This approach also enables very large models with extremely high total parameter counts without necessarily increasing inference cost proportionally. Experts can specialize strongly in their domains, improving output quality. Finally, at comparable density and scale, MoE architectures often deliver faster inference than fully dense models.
In simple terms, it is like going to a hospital and being routed directly to the most relevant department, rather than seeing a general practitioner who is decent at many topics but not truly specialized in any.
MoE can improve inference efficiency, but quality depends heavily on routing and the data used.
These indicators provide a first read of the claimed gains, but they make much more sense once you understand the underlying mechanisms. The table below summarizes the core metrics before diving deeper into the pipeline and memory optimizations.
The pipeline starts by splitting the image into patches. These are analyzed locally to extract relevant visual structures. A compression step then reduces the dimensionality of representations before global contextualization.
This chain aims to reduce redundancy while preserving important relationships between different areas of the document.
DeepSeek OCR includes attention optimizations designed to reduce the memory footprint of long-context processing. These optimizations help keep performance stable as document size grows.
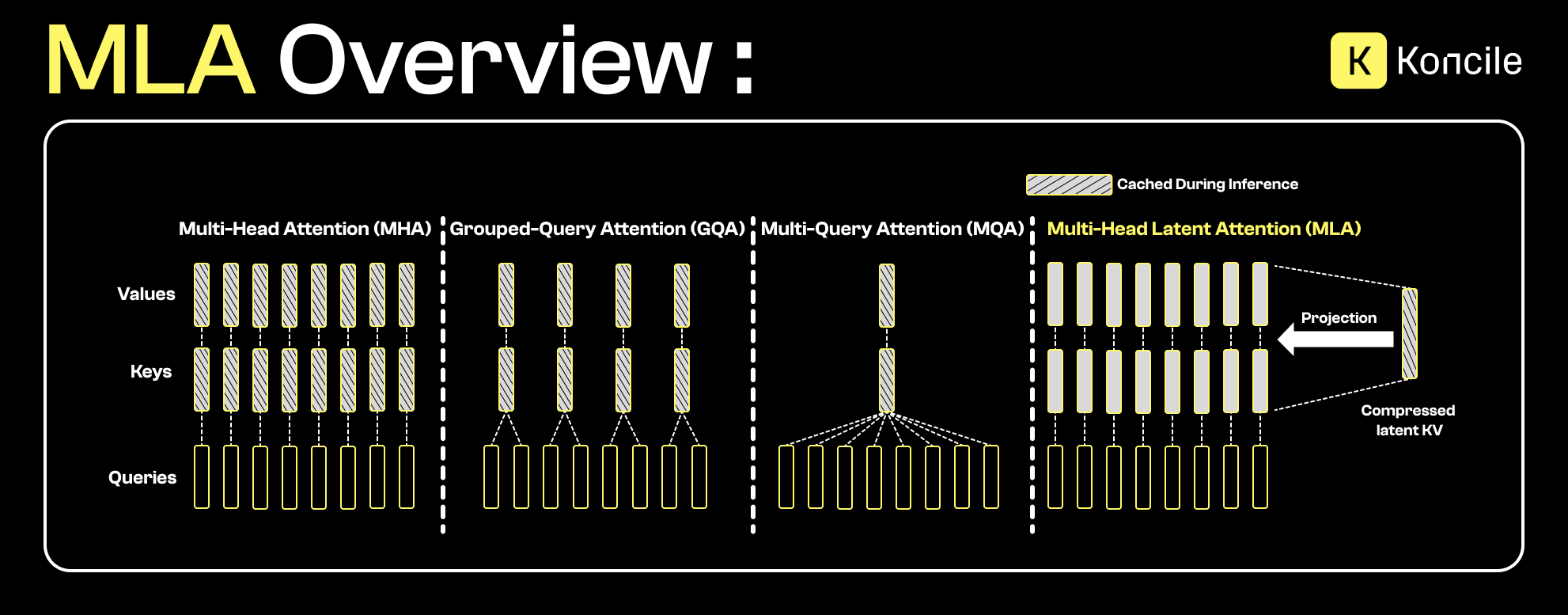
Before introducing Flash MLA, it helps to understand the idea behind Multi-Head Latent Attention (MLA).
Unlike standard attention mechanisms, where keys and values (KV) are stored explicitly for each attention head, MLA projects this information into a compressed latent space. This keeps essential token relationships while drastically reducing the KV-cache memory required at inference.
In practice, MLA can be seen as an evolution of approaches such as Multi-Query Attention (MQA) or Grouped-Query Attention (GQA). Where those methods partially share keys and values, MLA goes further by compressing the representation itself. This is especially relevant for long contexts, where KV-cache memory becomes the limiting factor.
DeepSeek OCR uses Flash MLA, an optimized implementation of latent multi-head attention. It leverages NVIDIA GPU kernels to speed up computation while reducing memory needed for the KV cache. Performance can remain stable even when memory is reduced significantly.
Flash MLA’s benefits are practical: less memory without a proportional quality drop, reduced “lost in the middle” behavior, longer contexts without memory saturation, and improved energy efficiency.
Large, heterogeneous, weakly standardized documents with internal dependencies can benefit from better global context handling. Archives, legal files, and multi-section reports often fall into this category.
For short, highly structured documents that are already well segmented, the benefits of advanced context compression may be marginal. In those cases, integration and maintenance costs should be weighed against the real-world gain.
Like any advanced approach, DeepSeek OCR comes with constraints. Compression can cause loss of fine-grained information in specific cases. The architecture also relies on multiple pre-trained components, which can make adaptation to very specific contexts more challenging.
Finally, deployment and optimization complexity remains a key factor in production environments.
In production settings, these advances raise another question: how do you turn technical capabilities into systems that are reliable, controllable, and scalable?
Solutions like Koncile follow that logic. Rather than maximizing context compression at all costs, the production priority is robust extraction, field traceability, and the ability to adapt to a wide range of real documents. In practice, the value often comes from integration into a clear document workflow, with validation and operational controls.
In that kind of system, context handling is not only about model size or latent compression. It also relies on structuring, validation, and business-level controls to keep extraction quality stable on long or heterogeneous documents, without introducing unpredictable behavior in production.
DeepSeek OCR illustrates a clear direction in modern OCR: moving beyond visual decoding toward smarter context handling. By combining a vision encoder, representation compression, and an MoE-based decoder, the approach aims to process longer documents more efficiently.
Before adopting it, it remains essential to evaluate performance on real documents, integration constraints, and business objectives.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


