


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion
.avif)
Letzte Aktualisierung:
December 24, 2025
5 Minuten
DeepSeek OCR erregt Aufmerksamkeit durch starke Leistungen bei langen Dokumenten, bleibt in seiner Funktionsweise jedoch oft schwer verständlich. Dieser Artikel erklärt Architektur, Kontextkompression und deren praktische Bedeutung für OCR.
Eine klare und strukturierte Erklärung von DeepSeek OCR und seinem Umgang mit Dokumentenkontext.

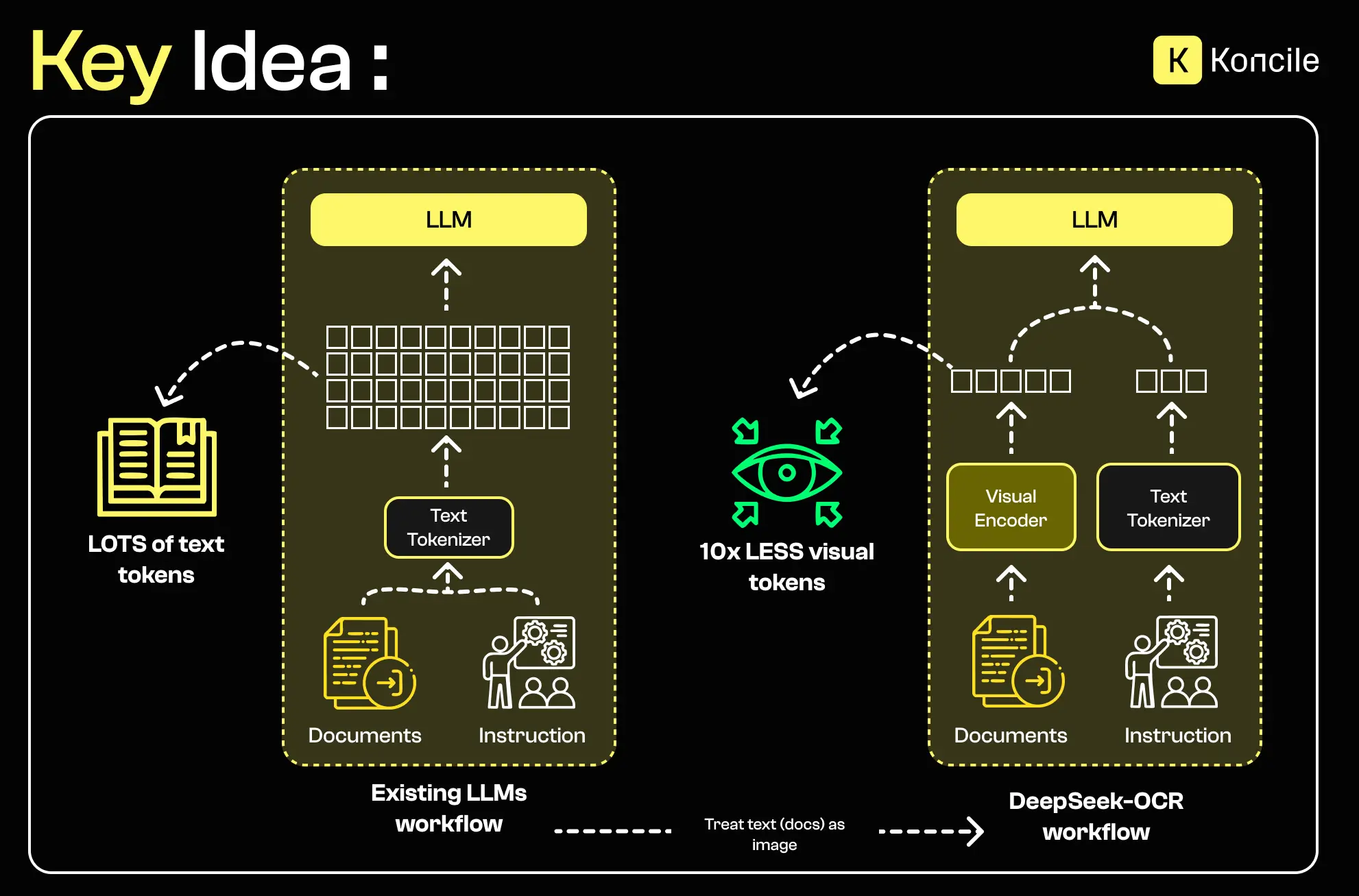
Moderne OCR Systeme unterscheiden sich heute nicht mehr nur durch ihre Fähigkeit zur Texterkennung, sondern vor allem durch ihren Umgang mit langen, komplexen und heterogenen Dokumenten – ohne die Rechenkosten explodieren zu lassen. DeepSeek OCR reiht sich in diese Entwicklung ein und setzt gezielt auf visuelle Kontextkompression und effiziente Inferenz.
In vielen realen Anwendungsfällen bestehen Dokumente nicht aus einer einzelnen Seite. Verwaltungsakten, Verträge, Archive oder mehrseitige Formulare haben ein gemeinsames Problem: Je länger das Dokument, desto höher der Speicherbedarf und desto größer das Risiko von Kontextverlust.
Klassische OCR-Pipelines – ebenso wie einige multimodale Ansätze – verarbeiten solche Dokumente durch Seitenaufteilung oder begrenzte Kontextfenster. Diese Methoden funktionieren grundsätzlich, führen jedoch zu Verständnisbrüchen zwischen weit auseinanderliegenden Seiten oder Abschnitten.
Diese Verfahren sind weit verbreitet und standardisiert, bleiben aber in einem Punkt schwach: der Verarbeitung langer Kontexte.
Die Herausforderung besteht nicht nur darin, Text zu lesen, sondern eine globale Kohärenz über das gesamte Dokument hinweg zu erhalten. Abhängige Felder, Querverweise und über mehrere Seiten verteilte Informationen erfordern eine kompakte, aber verlässliche Repräsentation von visuellen und textuellen Inhalten.
Genau an dieser Stelle setzt DeepSeek OCR mit seinem technischen Ansatz an.
DeepSeek OCR berichtet über starke Ergebnisse in spezialisierten Benchmarks, insbesondere im FOX-Datensatz, der häufig zur Bewertung der Informationsextraktion aus strukturierten Verwaltungsdokumenten genutzt wird. Diese Art der Bewertung steht im Kontext von Intelligent Document Processing, bei dem es nicht mehr nur um das Lesen von Text, sondern um verlässliche und nutzbare Datenergebnisse geht.
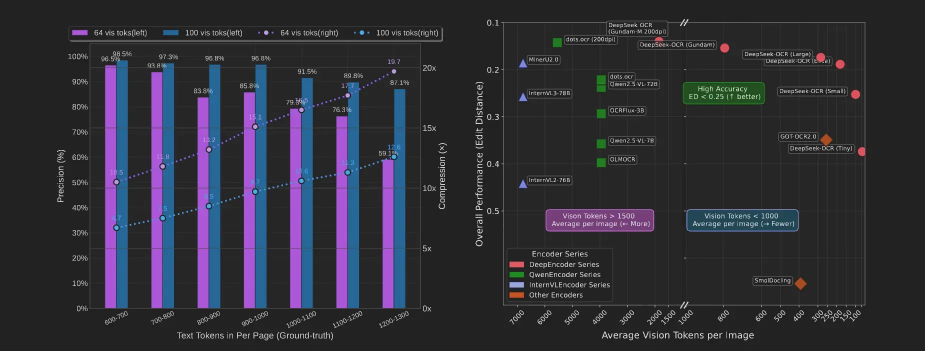
Der FOX-Datensatz konzentriert sich auf Dokumente mit hoher Informationsdichte, wiederkehrenden Strukturen, benannten Entitäten und impliziten Beziehungen. Gute Ergebnisse deuten daher auf ein Verständnis der Dokumentstruktur hin, das über reine Zeichenerkennung hinausgeht.
Die folgende Tabelle vergleicht die gemeldeten Leistungen anhand mehrerer Kriterien: Genauigkeit, Dokumenttypen, durchschnittliche Eingabelänge und Testannahmen.
Wenn DeepSeek OCR von einer „10x-Kompression“ spricht, geht es nicht um das Komprimieren von Quelldateien. Gemeint ist die Reduktion der internen Repräsentationen (Tokens), die vom Modell verwendet werden. Ziel ist es, relevante Informationen zu erhalten und gleichzeitig den Speicherbedarf für lange Kontexte deutlich zu senken.
Die Architektur von DeepSeek OCR trennt visuelle Kodierung und textuelle Dekodierung klar voneinander und verbindet beide über einen Mechanismus zur Repräsentationskompression.
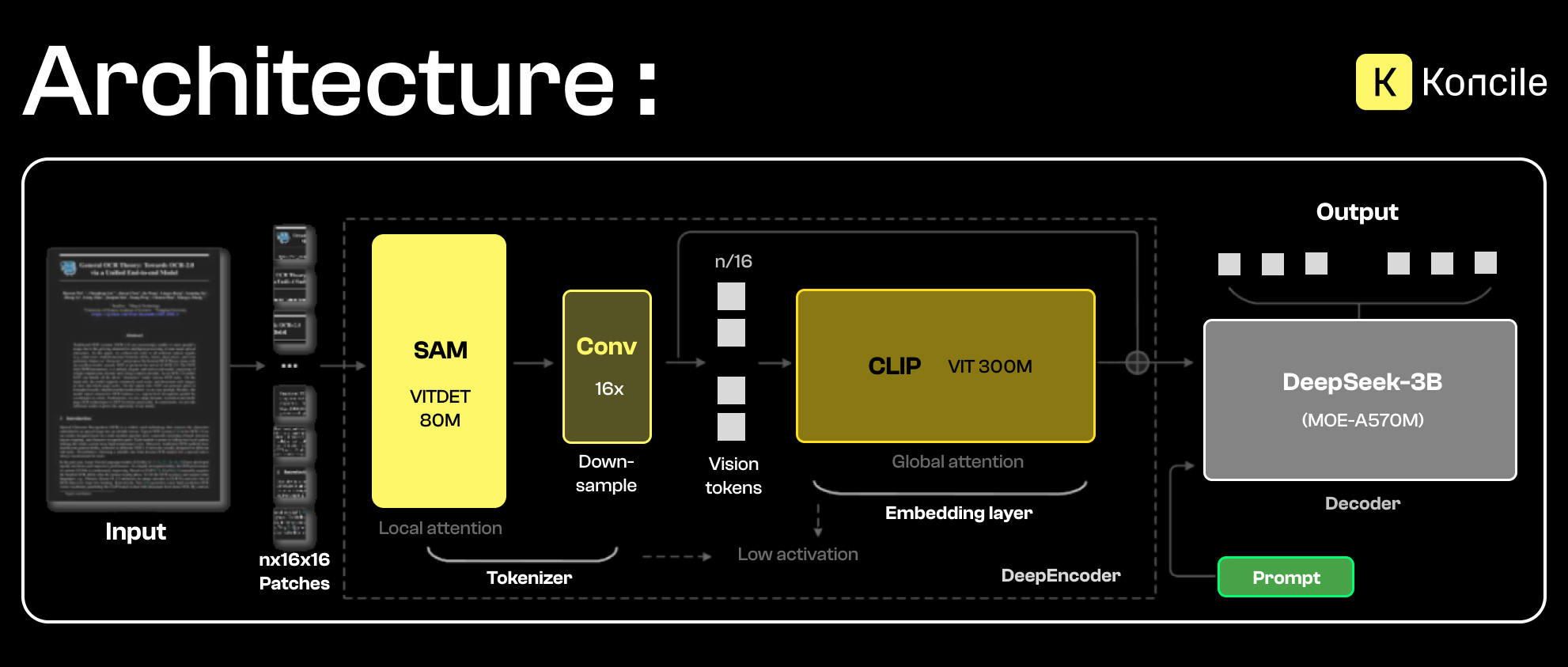
Der Vision-Encoder von DeepSeek OCR basiert auf zwei komplementären Komponenten, die visuelle Informationen auf unterschiedlichen Ebenen verarbeiten.
Einerseits wird SAM (Segment Anything Model) für die Segmentierung und lokale Bildanalyse eingesetzt. Durch seinen lokalen Aufmerksamkeitsmechanismus kann SAM relevante Dokumentbereiche wie Textblöcke, Tabellen, Ränder oder visuelle Trennlinien präzise identifizieren. Dieser Schritt ist entscheidend, um feine Details, Konturen und räumliche Strukturen zu erfassen.

Andererseits sorgt CLIP (Contrastive Language–Image Pretraining) für ein globales, semantisches Verständnis. Im Gegensatz zu SAM fokussiert sich CLIP nicht auf lokale Details, sondern projiziert das Bild in einen semantischen Raum, der mit Sprache verknüpft ist. Dadurch lassen sich erkannte Regionen mit Bedeutungen, Absichten oder übergeordneten Dokumentstrukturen verbinden.

Die Kombination beider Ansätze erzeugt eine visuelle Repräsentation, die zugleich präzise und kontextualisiert ist. SAM liefert eine feingranulare, strukturierte Sicht auf das Dokument, während CLIP die globale Interpretation ermöglicht. Diese angereicherte Darstellung bildet die Grundlage für die Kontextkompression und die anschließende Textgenerierung.
MoE steht für „Mixture of Experts“ und bezeichnet eine Architektur, die zunehmend in großen KI-Modellen eingesetzt wird. Sie lässt sich als Zusammenspiel spezialisierter Teilmodelle verstehen, sogenannter Experten, die jeweils auf bestimmte Muster oder Aufgaben fokussiert sind. Ein intelligenter Router entscheidet, welche Experten für eine Anfrage aktiviert werden.
Der zentrale Gedanke besteht darin, nur die tatsächlich benötigten Ressourcen zu nutzen und unnötige Berechnungen zu vermeiden. Dadurch lassen sich sehr große Modelle mit extrem vielen Parametern realisieren, ohne dass die Inferenzkosten proportional steigen. Gleichzeitig können sich die einzelnen Experten stärker spezialisieren, was die Ergebnisqualität verbessert. Bei vergleichbarer Dichte sind MoE-Architekturen zudem häufig schneller als vollständig dichte Modelle.
Vereinfacht gesagt ähnelt dies einem Krankenhausbesuch, bei dem man direkt an die passende Fachabteilung weitergeleitet wird, statt zuerst einen Allgemeinmediziner aufzusuchen.
Eine MoE-Architektur steigert die Effizienz der Inferenz, ihre Qualität hängt jedoch stark vom Routing und den verwendeten Trainingsdaten ab.
Diese Kennzahlen liefern eine erste Einschätzung der behaupteten Vorteile, entfalten ihre Aussagekraft jedoch erst im Zusammenspiel mit den zugrunde liegenden Mechanismen. Die folgende Tabelle fasst die wichtigsten Metriken zusammen.
Der Prozess beginnt mit der Aufteilung des Bildes in Patches. Diese werden lokal analysiert, um relevante visuelle Strukturen zu extrahieren. Anschließend reduziert eine Kompressionsstufe die Dimensionalität der Repräsentationen, bevor eine globale Kontextualisierung erfolgt.
Ziel dieser Pipeline ist es, Redundanzen zu minimieren und gleichzeitig wichtige Beziehungen zwischen den Dokumentbereichen zu bewahren.
DeepSeek OCR integriert optimierte Aufmerksamkeitsmechanismen, um den Speicherbedarf bei langen Kontexten zu reduzieren. Dadurch bleiben die Leistungen stabil, auch wenn die Dokumentlänge zunimmt.
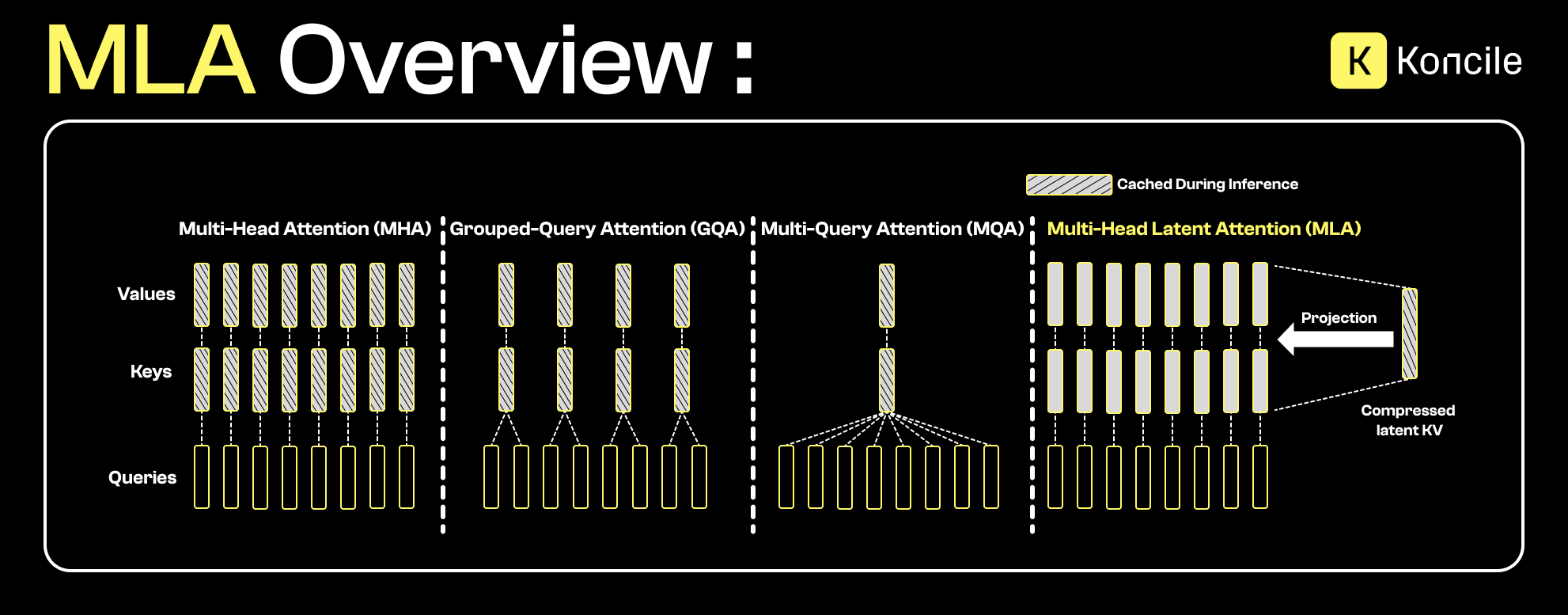
Bevor Flash MLA betrachtet wird, ist es hilfreich, das Prinzip der Multi-Head Latent Attention (MLA) zu verstehen.
Im Gegensatz zu klassischen Aufmerksamkeitsmechanismen, bei denen Schlüssel und Werte (KV) explizit gespeichert werden, projiziert MLA diese Informationen in einen komprimierten latenten Raum. So bleiben zentrale Beziehungen zwischen Tokens erhalten, während der Speicherbedarf für den KV-Cache drastisch sinkt.
MLA lässt sich als Weiterentwicklung von Ansätzen wie Multi-Query Attention (MQA) oder Grouped-Query Attention (GQA) verstehen. Während diese Methoden Schlüssel und Werte teilweise teilen, geht MLA einen Schritt weiter und komprimiert die Repräsentation selbst. Das ist insbesondere bei langen Kontexten relevant, bei denen der KV-Cache schnell zum Engpass wird.
DeepSeek OCR nutzt Flash MLA, eine optimierte Implementierung der latenten Multi-Head Attention. Sie verwendet NVIDIA-GPU-Kernels, um Berechnungen zu beschleunigen und gleichzeitig den Speicherverbrauch zu senken. Auch bei deutlich reduziertem Speicher bleibt die Leistung stabil.
Zu den praktischen Vorteilen zählen ein geringerer Speicherbedarf ohne proportionale Qualitätseinbußen, eine deutliche Reduktion des „Lost-in-the-Middle“-Effekts, die Verarbeitung sehr langer Kontexte sowie eine verbesserte Energieeffizienz.
Große, heterogene und wenig standardisierte Dokumente mit internen Abhängigkeiten profitieren besonders von einer besseren globalen Kontextverarbeitung. Dazu zählen Archive, juristische Akten oder umfangreiche Berichte.
Bei kurzen, stark strukturierten und bereits gut segmentierten Dokumenten können die Vorteile einer fortgeschrittenen Kontextkompression geringer ausfallen. In solchen Fällen sollten Integrations- und Wartungskosten gegen den tatsächlichen Nutzen abgewogen werden.
Wie jeder fortgeschrittene Ansatz bringt auch DeepSeek OCR Einschränkungen mit sich. Eine zu aggressive Kompression kann in bestimmten Fällen feine Detailinformationen verlieren. Zudem basiert die Architektur auf mehreren vortrainierten Komponenten, was die Anpassung an sehr spezifische Anwendungsfälle erschweren kann.
Auch der technische Aufwand für Deployment und Optimierung spielt in produktiven Umgebungen eine wichtige Rolle.
In produktiven Systemen stellt sich eine weitere Frage: Wie lassen sich diese technischen Fortschritte in verlässliche, kontrollierbare und skalierbare Lösungen überführen?
Lösungen wie Koncile verfolgen genau diesen Ansatz. Statt maximale Kontextkompression um jeden Preis anzustreben, liegt der Fokus auf robuster Extraktion, Nachvollziehbarkeit der erkannten Felder und Anpassungsfähigkeit an reale Dokumentvielfalt. In der Praxis entsteht der Mehrwert häufig durch die Einbettung in einen klaren dokumenten Workflow.
Hier beruht Kontextverarbeitung nicht allein auf Modellgröße oder latenter Kompression, sondern auch auf Strukturierung, Validierung und fachlichen Kontrollmechanismen. So lässt sich eine stabile Extraktionsqualität auch bei langen oder heterogenen Dokumenten gewährleisten – ohne unvorhersehbares Verhalten in der Produktion.
DeepSeek OCR verdeutlicht eine klare Entwicklung im modernen OCR-Bereich: weg von reiner visueller Dekodierung hin zu intelligenter Kontextverarbeitung. Durch die Kombination aus Vision-Encoder, Repräsentationskompression und MoE-Architektur sollen längere Dokumente effizienter verarbeitet werden.
Vor einer Einführung ist es jedoch entscheidend, die Leistungen anhand realer Dokumente, Integrationsanforderungen und konkreter Geschäftsziele zu bewerten.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


