


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
January 9, 2026
5 minutes
OCR (Optical Character Recognition) is a technology that converts paper documents, images, or PDFs into machine-readable text. With OCR, you can automatically extract the information you need from your scanned or image-based documents, turning them into usable, searchable data.
We simply explain to you the essentials of OCR, its concrete uses and its advantages.

OCR stands for Optical Character Recognition. It’s a technology that converts visual content such as printed or handwritten text into machine-readable digital text.
In other words, OCR makes it possible to extract text or information from a photo, a scan, or a non-editable PDF.
An OCR (Optical Character Recognition) software is a tool that applies this technology to your documents. It takes a non-editable image or PDF file as input and generates structured, machine-readable text as output.
Some OCR tools simply copy the text and turn a static PDF into an editable Word document.
Others go further by automatically detecting key fields such as names, dates, and amounts, exporting data into Excel or a database, and integrating with your business tools via API.
While some OCR solutions are installed locally (on-premise), the most advanced ones are typically cloud-based. These platforms rely on machine learning algorithms or large language models (LLMs), which require significant computing power and work best with an internet connection.
A good OCR tool primarily helps to eliminate manual data entry, which is time-consuming and prone to errors. It automatically extracts key information from your documents (PDFs, scanned images, etc.) and organizes it into an Excel file or sends it directly to your business tools.
OCR helps to secure, speed up, and automate your document workflows, especially in interactions with clients, suppliers, or service providers.
Once extracted, the data becomes a valuable resource for checks, audits, or analysis whether in accounting, auditing, or operational management.
An OCR software relies on a combination of technologies:
Computer vision is used to analyze the image and identify text shapes, lines, and characters.
Natural Language Processing is used to understand the context of the text and its information of interest. For example, the system needs to understand that a string of characters is a date, name, or amount in the context of the document and how to respond accordingly.
The OCR process is generally as follows:
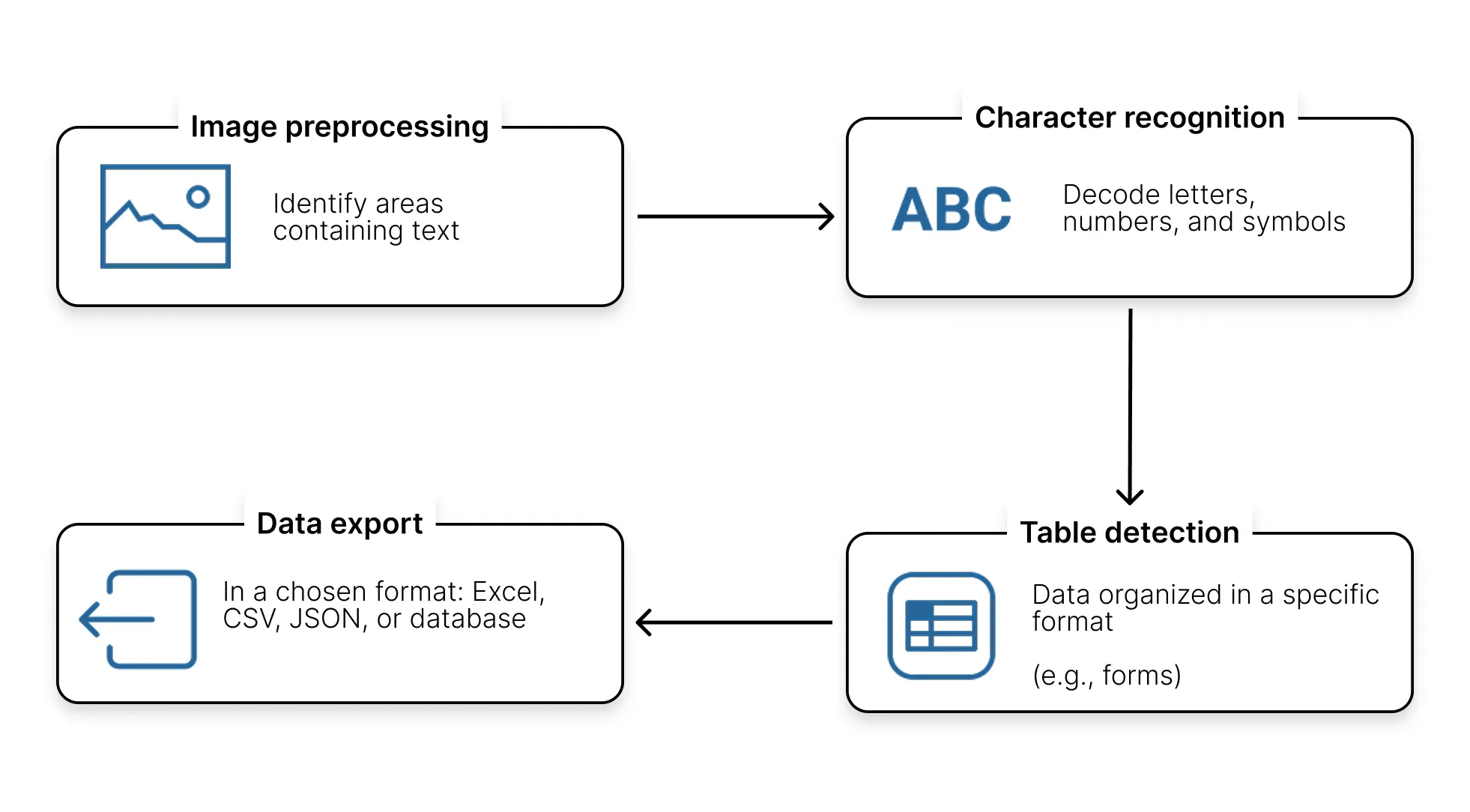
Some modern solutions such as new accounting software Koncile adds a layer of artificial intelligence for data validation, line-by-line context extraction, detection of errors, errors, inconsistencies, duplicates, or other anomalies.
An OCR API (Application Programming Interface) allows documents to be automatically processed by calling an online service, without using a user interface. In other words, it gives your software the ability to read, extract, and structure text in real time from a PDF, image, or photo.
It is the ideal solution to integrate OCR into a business application, automate data entry, or build fully digital document workflows without human intervention. A robust OCR API typically offers customization options (fields to extract, language, output format) and integrates easily with your IT system or tools like Zapier, Make, or internal ERP/CRM platforms.
import requests
files = {'file': open('facture.pdf', 'rb')}
response = requests.post('https://api.koncile.ai/ocr', files=files)
print(response.json())
While invoice OCR remains the most common use case, this technology now adapts to a wide range of professional documents whether structured, semi-structured, or unstructured. Thanks to artificial intelligence and intelligent document processing, modern OCR tools can extract data even from complex or inconsistent layouts.
Bank statements OCR, purchase orders, company accounts, financial statements... OCR helps automate data entry and feeds your accounting systems with high precision.
Tax packages (BIC, BNC, SCI…), tax returns, administrative correspondence: OCR streamlines archiving, compliance, and data centralization.
CVs, payslips, employment contracts, amendments, sick leave notices… OCR structures your HR documents and connects directly with your HRIS, reducing manual workload.
Freight invoices (road, maritime, express…), delivery slips, CMRs, waybills, bills of lading: OCR makes unstandardized documents usable for traceability and reconciliation.
Sales agreements, commercial or residential leases, energy performance certificates (EPC), check-in/out reports... OCR extracts key clauses and improves document reliability.
OCR medical prescriptions, national health cards, care sheets, lab results, medical certificates… OCR simplifies patient file management and reimbursement processes.
Receipts extraction, proof of purchase, product labels, barcodes… OCR allows for sales analysis, price monitoring, and commercial document compliance checks.
For longer or denser documents such as real estate agreements or legal contracts, OCR becomes more of an intelligent data capture solution. The challenge is to understand, contextualize, and structure key information hidden within large volumes of text.
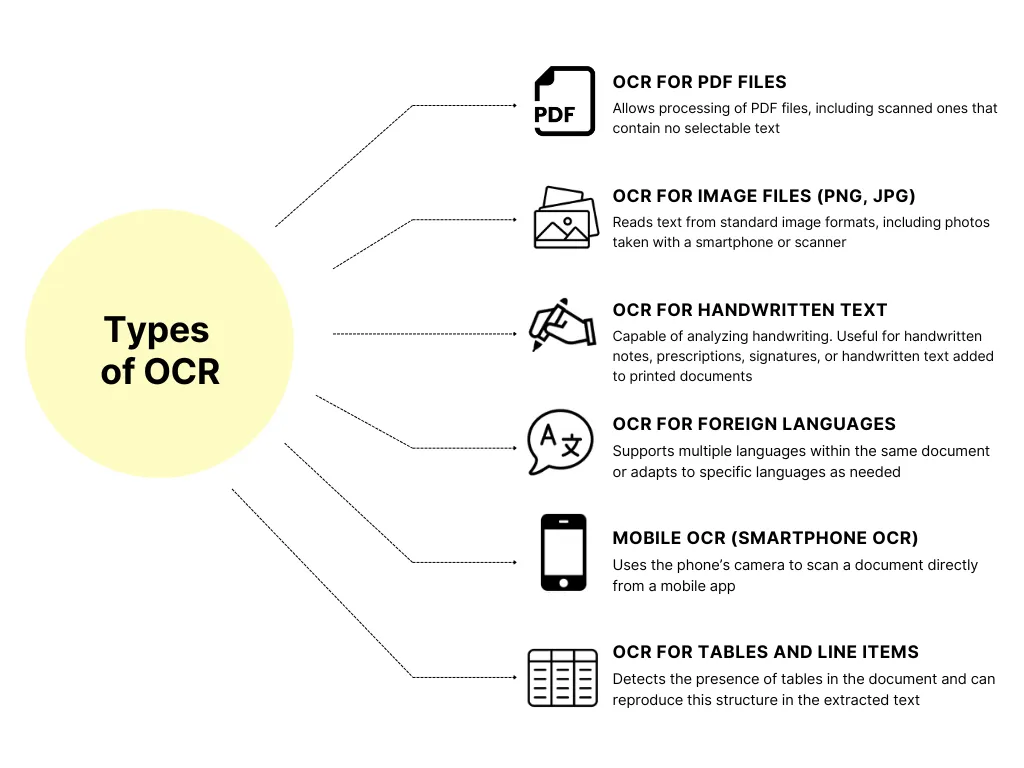
💡 Thanks to the modularity of modern OCR tools, you can also process documents outside this list by defining the fields you want to extract. OCR adapts to your specific use cases.
OCR is often a key element in document automation within your company. Some of the identified benefits include:
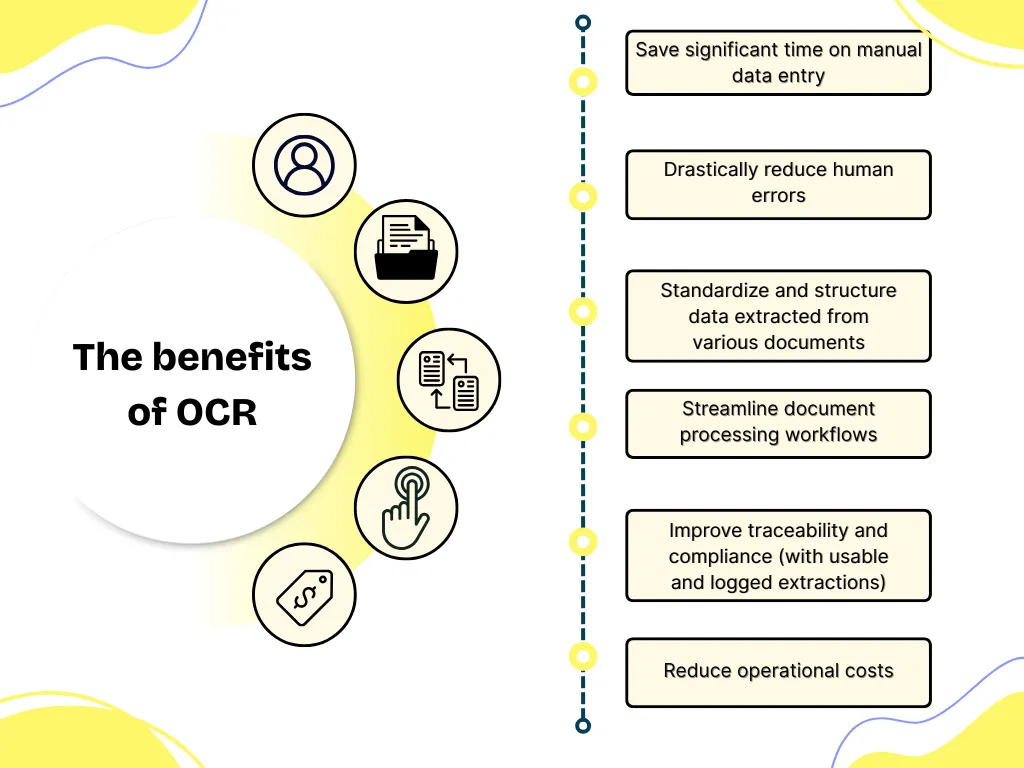
In a professional context, an OCR makes it possible to transform an administrative burden into a lever for efficiency.
Classic OCR is limited to detecting and converting plain text. It makes no contextual distinction, does not understand the extracted data, and cannot structure it accurately.
Conversely, an OCR powered by artificial intelligence (AI), like Koncile, is capable of:
AI OCR doesn't just extract: it interprets, controls, and values data.
Before choosing OCR technology, ask yourself the right questions:
There’s no such thing as a one-size-fits-all “best” OCR tool, instead, different solutions are suited to different use cases:

An open-source OCR engine recommended for developers who want to integrate OCR into their own applications. Powerful, but requires solid technical knowledge.

Useful for occasional use, such as extracting text from scanned PDFs or converting documents to Word. Easy to use, but lacks flexibility for bulk or complex processing.
Ultimately, the best tool depends on your technical expertise, the volume of documents to process, and the specific needs of your organization.

Ideal for businesses that need to process large volumes of documents (invoices, contracts, supporting documents, etc.). A turnkey solution, customizable and integrable via API.
There are many free OCR tools available online, ideal for occasional needs or testing purposes. These solutions typically allow you to convert an image or PDF into text within a few clicks,no installation or sign-up required. Some of the most popular options include Online OCR, i2OCR, and Google Docs, which offers a basic built-in OCR feature.
Online OCR tools are accessible via a web browser and are well-suited for simple documents. They are easy to use but may have limitations in terms of volume, supported languages, or data privacy—especially when handling sensitive information.
👉 For professional or large-scale use, it's recommended to choose a more robust and secure OCR solution, one that can integrate with your existing tools via API.
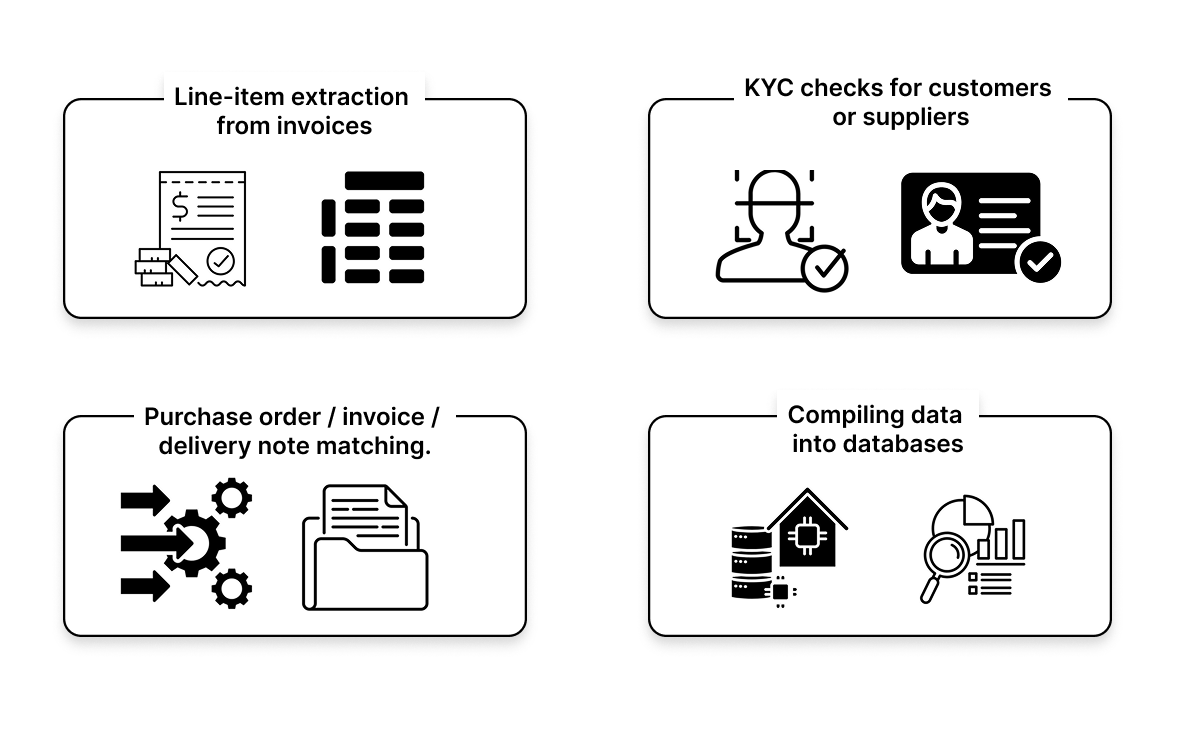
OCR extracts every line from an invoice and converts it into a structured table, capturing each column such as item name, unit price, quantity, and packaging. This table can then be used to cross-check prices against a pricing grid for automated verification.
OCR extracts key information from ID cards, passports, business registration documents (like Kbis), or forms submitted by clients or vendors. Extracted fields (such as name or date of birth) can serve as anchors to match records in your CRM, helping detect duplicates or potential fraud through anomaly checks (e.g., mismatched birthdates or suspicious addresses).
OCR can automatically extract data from purchase orders, invoices, and delivery slips to cross-reference them. This allows you to detect discrepancies between what was ordered, delivered, and billed, automating compliance checks and validation workflows, especially useful in complex or multi-supplier logistics setups.
OCR converts paper or scanned documents into structured, usable data that can populate databases like Excel, SQL, or your CRM. Whether it's contracts, product sheets, technical reports, or HR documents, OCR eliminates manual entry and ensures your tools are updated with reliable, organized information.
To convert an image (JPEG, PNG, TIFF, etc.) into text, you need to use OCR software. The tool detects the characters in the image and transforms them into digital text. The output can be exported to a Word file, Excel sheet, editable PDF, or directly to a database.
Start by scanning your document with a scanner or smartphone. Once you have the file (usually a PDF or image), you upload it into OCR software, which automatically extracts the text. Some professional scanners have built-in OCR engines and produce directly editable documents.
Yes, Google Drive includes a basic OCR feature. If you upload an image or PDF and open it with Google Docs, the system automatically converts it into editable text. This feature is free but limited when handling complex documents, tables, or low-quality scans.
Scanning creates a digital image of a document, but the content remains fixed and non-editable.OCR goes further by analyzing that image to extract text, allowing it to be copied, edited, or integrated into business tools. In short: scanning captures, OCR interprets.
It depends on the document quality and the OCR engine used. On clean, printed text with a proper scan, OCR can reach 98–99% accuracy. However, the rate decreases with blurry, misaligned, or handwritten content. AI-powered OCR engines deliver the best results across a variety of real-world documents.
Yes, but only with advanced OCR engines capable of handwriting recognition — also known as ICR (Intelligent Character Recognition). These tools can recognize handwritten forms, signatures, or notes with a certain level of reliability, depending on legibility.
Yes. The best OCR engines support multiple languages, even within a single document. You can either specify the languages in the settings or let the system detect them automatically.
Yes. Many OCR solutions are available as local (on-premise) software installed on your servers or computers. This allows offline processing, ideal for sensitive sectors like healthcare, legal, or defense, or to comply with data privacy and sovereignty regulations.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


