



Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Dernière mise à jour :
September 8, 2025
5 minutes
With the Koncile API and its Swagger interface, you can transform any PDF file into a structured JSON file, ready to be used in accounting software, CRM, or ERP. Here is a step-by-step guide to doing this conversion simply, without having to code.
Discover how to transform these documents into structured JSON to automatically use them in your business tools (accounting, CRM, ERP...). Thanks to the Koncile API, convert your PDFs into ready-to-use data, without coding. This comprehensive step-by-step guide shows you how to automate this process, whether you're a developer or not.

Koncile offers a turnkey solution to transform your PDFs into structured JSON, even for complex or handwritten documents thanks to its OCR software new generation.
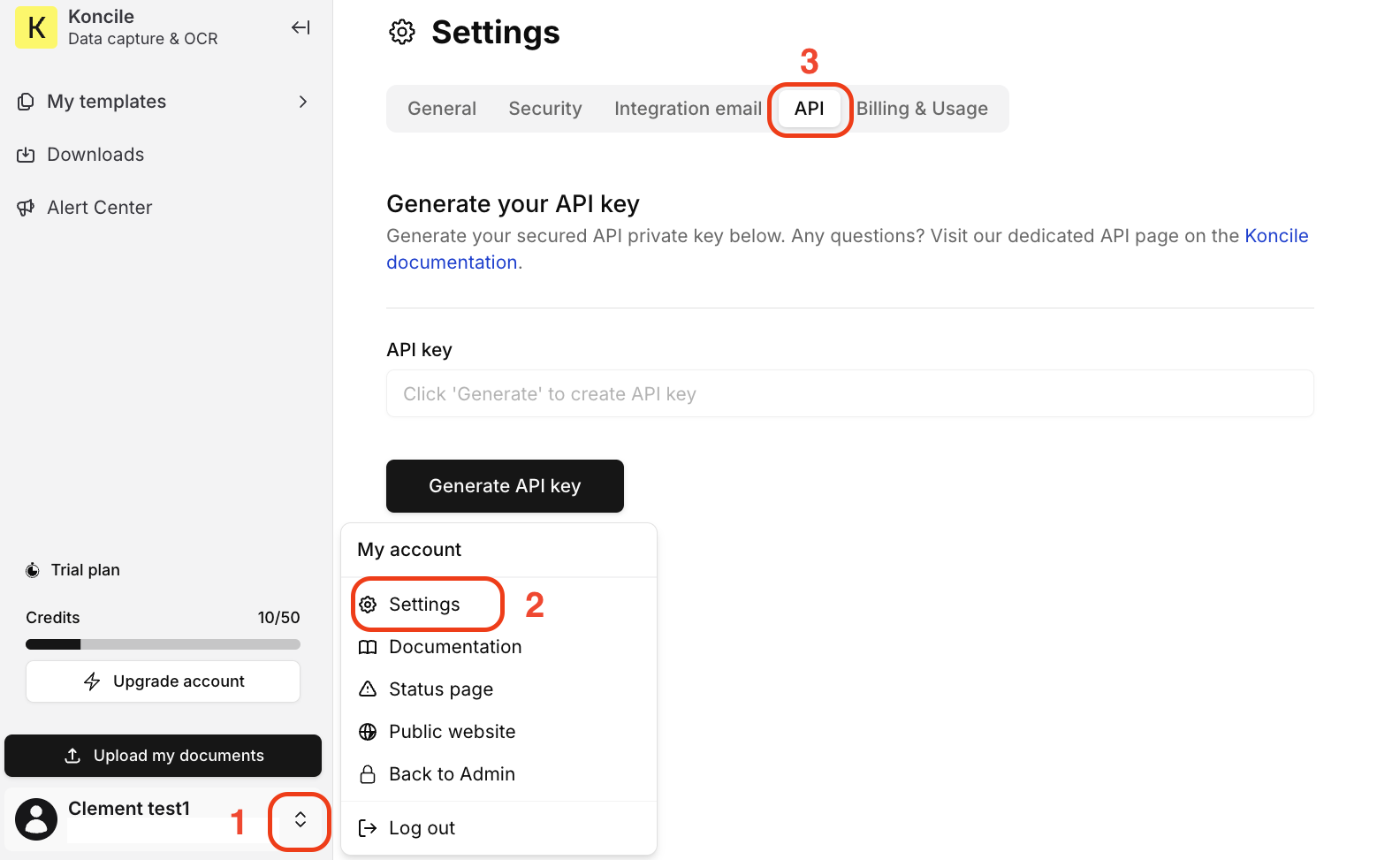
To establish a secure connection with the Koncile API, start by going to the your account settings (for administrators only).
Go to the tab API, then click “Generate an API key” to get your personal access key.
Go to Koncile's Swagger documentation at: https://api.koncile.ai/documentation
Then select the endpoint: POST /v1/upload_file/ — Upload file

This is where you can send a document once the connection is established.
This is where you can send a document once the connection is established.
Activate authentication
Value.
Once authenticated, you can prepare to send your file to be converted:
Fill in the optional parameters
You can add in the fields provided:

Add your file to the Request Body
Scroll down to the section “Request Body” and upload the PDF file you want to convert to JSON.

Start sending
Then click on “Execute” to start the request.
In the section “Responses”, a task_id will be returned to you: it will allow you to retrieve the file converted to JSON format in the next step.

Once the document is sent, you can retrieve the extracted data in JSON:
1. Go to the next endpoint, located just below in the Swagger documentation : GET /v1/fetch_tasks_results/ — Fetch Tasks Result
2. In the field provided, Paste it task_id obtained during the previous step.

3. Click on “Execute” to start the request.
The API then returns you a structured JSON file containing all the information automatically extracted from the sent document that you can then copy or download directly.

Koncile offers a turnkey solution to transform your PDFs into structured JSON even when they are complex or of average quality documents (scans, photos, manuscripts).
this data can be used to:
For developers on your team
Koncile provides:
Good news: you don't have to be a developer to harness the power of JSON. Thanks to the emergence of tools No-code and low-code, many businesses can now automate their document processing without writing a line of code.
Integrate your daily tools directly such as Slack, Google Drive, Drobox


Examples of simple no-code integration with platforms like:
What you can do without coding:
It is the assurance of increasing productivity, without systematically depending on the technical team

Thus, Make, for example, allows you to create an automated scenario: as soon as a PDF is added to Google Drive, it is sent to the Koncile API for analysis. Once the file is converted to JSON, the data can be automatically retrieved and stored or used in another tool, without writing code.

PDF is a universal format: it is used all over the world to transmit commercial, legal, accounting, administrative documents... But while it is ideal for Human reading, it is much less so for automated processing. In contrast, JSON is a structured format, designed so that machines can easily understand and reuse data.
Transforming a PDF into JSON is therefore rendering its content can be used automatically by your business software via an API. This is a key step in increasing efficiency, reducing human errors, and automating your internal processes.
Even when generated digitally, a PDF file remains difficult to exploit automatically. Some invoices or scanned documents have variations that complicate extraction:
Result: these documents, often semi-structured or even unstructured, still require a human intervention to be understood... unless we go through OCR processing with export in JSON.

For your business tools to understand a document, you need extract data in a structured format. That's where the JSON come into play.
This lightweight and universal format makes it possible to represent data in the form of key/value pairs. Concretely, this amounts to transforming a static PDF into an “intelligent” file: readable by a machine, usable by an API, integrable into your business software.
Today, there are several solutions to transform a PDF into JSON. The choice depends on the nature of the document (text or image) and automation level desired.
The conversion PDF → JSON Represents a fundamental work to transform static documents into dynamic data. Thanks to structuring and automating via API, you gain in reliability, speed and performance in document management.
Integrate this structured data directly into your business systems to ensure reliable, fast processing that is perfectly integrated into your accounting, analytical or operational processes.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives

Five French OCR solutions compared for extracting your document data with full GDPR compliance, hosted on servers in France.
Comparatives
.png)


