


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature
.webp)
Dernière mise à jour :
June 20, 2026
5 minutes
ETL solutions play a central role in simplifying the management, cleaning, enrichment, and consolidation of data from a variety of sources. In this blog post, we will clearly explain what ETL is, its process, what benefits it brings to organizations, concrete examples of use, as well as an overview of some popular ETL tools with their respective advantages. ETL pipelines help companies turn scattered raw data into reliable, usable information. This guide breaks down how they work, where they shine, and how modern tools enhance them.
A clear guide to ETL pipelines, their steps, challenges, and modern applications across data and document workflows.

ETL, short for Extract, Transform, Load, refers to a data integration pipeline designed to gather information from multiple systems, clean and standardize it, and centralize it in a target environment such as a data warehouse or a data lake.
In practice, an ETL pipeline takes dispersed, inconsistent, or unstructured datasets and turns them into unified, reliable information ready for analytics, reporting, machine learning, or operational tools.
.png)
Traditionally used in business intelligence and analytics, ETL pipelines are increasingly applied to document-heavy workflows as companies work with PDFs, invoices, contracts, and identity documents. In these cases, upstream extraction using open source OCR models or intelligent document processing becomes essential for turning unstructured content into structured, usable data.
ETL pipelines are usually automated, orchestrated workflows that run on schedules, event triggers, or real-time streams depending on operational needs.
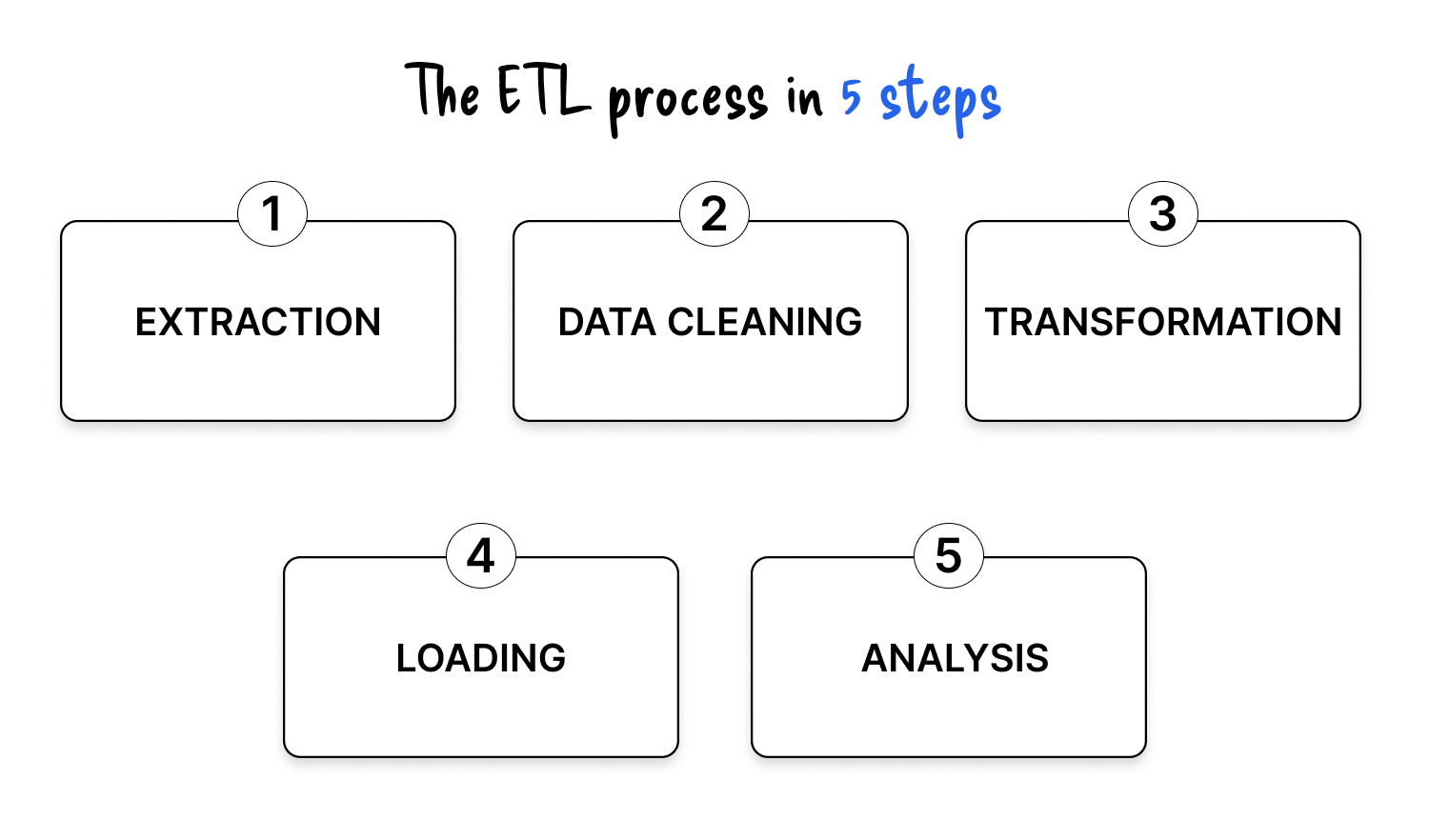
Extraction is the process of gathering data from one or more input systems. These sources can be:
Extracted data is temporarily stored in a staging or transit area before any heavy processing.
Several extraction methods exist:
When documents enter the picture, extraction may involve OCR, layout analysis, or file parsing even before the ETL pipeline starts its traditional work.
Once the data is collected, the first processing phase focuses on data quality. Data cleaning includes:
For document-based workflows, this step also includes initial OCR validation, page separation, basic field sanity checks, and filtering out unreadable documents.
Good data cleaning reduces friction in downstream transformation and prevents bad records from polluting analytics.
Transformation is where data becomes truly useful. It goes beyond basic cleaning and focuses on business and technical requirements of the target system:
In document workflows, this is where OCR results are post-processed: table extraction, field mapping, classification, and entity detection. For instance, companies processing vendor invoices often combine ETL with Invoice OCR to turn unstructured PDFs into standardized, analysis-ready records.
Once transformed, cleaned, and enriched, the data is loaded into a target environment where it can be consumed by downstream tools:
Common loading strategies include:
A well-designed loading strategy ensures both performance and consistency, especially when multiple teams depend on the same datasets.
The final step focuses on how data is used:
This is where the value of the entire ETL pipeline becomes visible to the business.
For document-heavy processes, this stage might include dashboards on invoice cycle time, KYC validation rates, or risk scoring based on structured outputs from OCR and intelligent document processing.
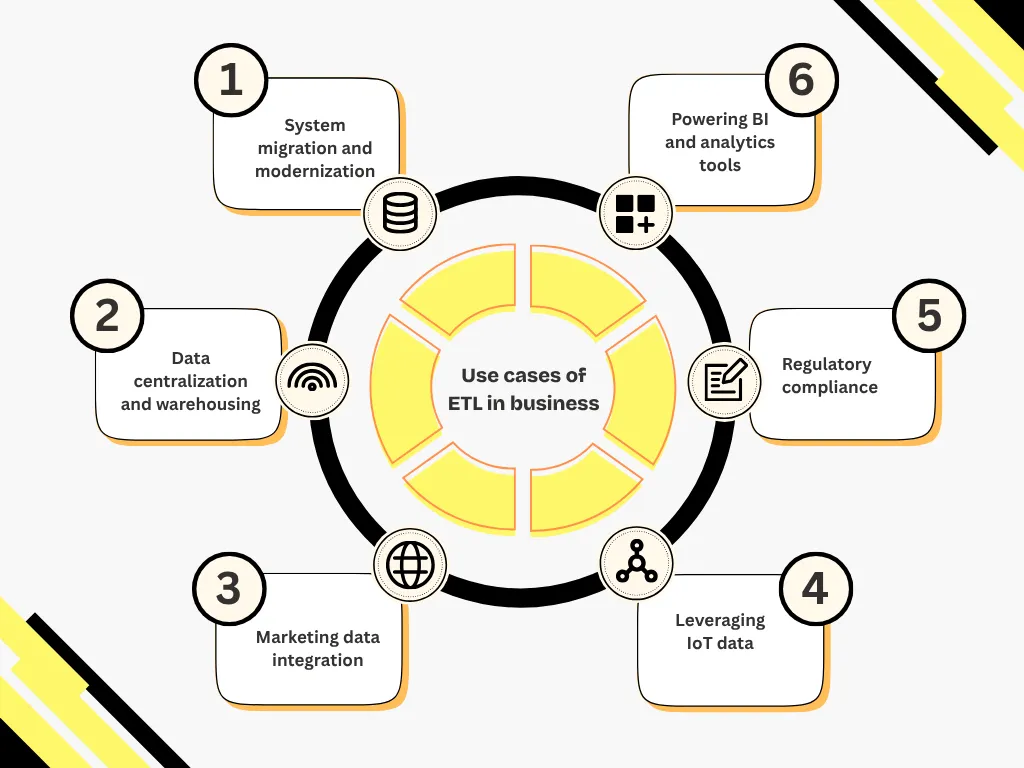
ETL pipelines power a wide range of business and technical use cases.
ETL consolidates and restructures data when migrating from legacy systems to cloud architectures or when synchronizing multiple operational databases.
ETL connects ERP, CRM, spreadsheets, and APIs, consolidating them into a unified data warehouse for cross-analysis and reporting.
ETL aggregates multichannel information (e-commerce, social media, email, CRM) to build a unified customer view and drive segmentation or personalization.
Connected devices and sensors generate large volumes of telemetry. ETL cleans, enriches, and standardizes this data for predictive maintenance or operations optimization.
ETL supports GDPR, HIPAA, and CCPA requirements by filtering, anonymizing, and ensuring traceability of sensitive data during transfers.
ETL pipelines power dashboards, BI platforms, and predictive models by automating upstream preparation and ensuring reliable data freshness.
When companies process invoices, bank statements, contracts, or identification documents, ETL pipelines integrate OCR, table extraction, and field mapping. Intelligent document processing plays a key role in structuring unstructured content before it enters the warehouse.
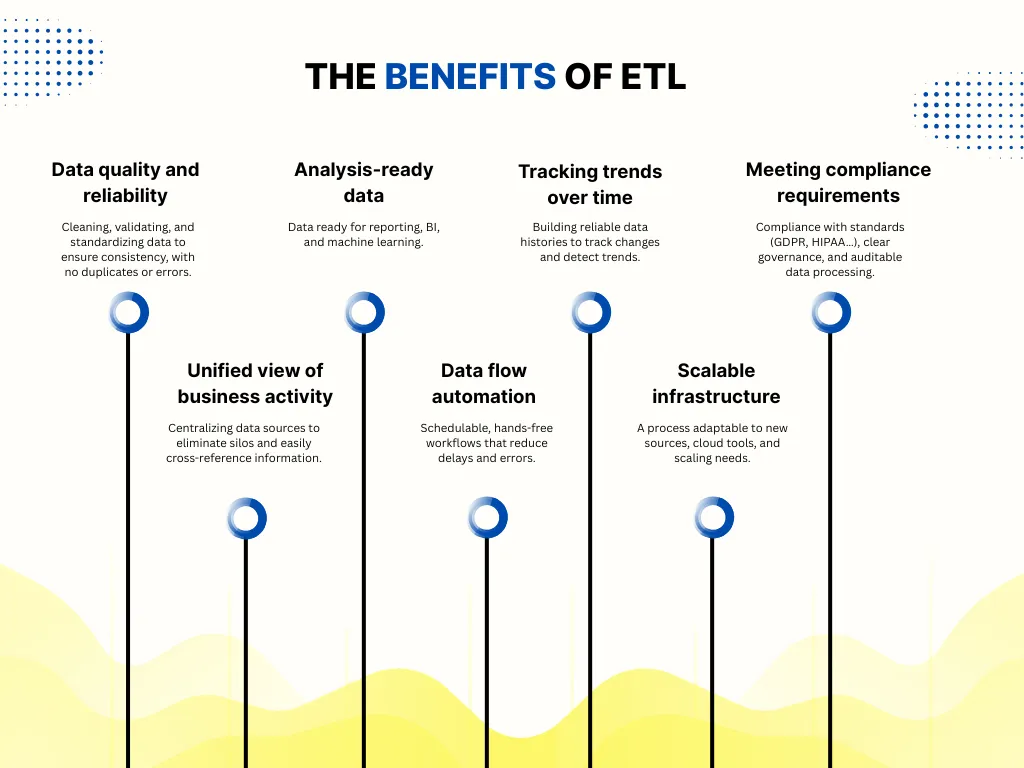
ETL pipelines bring multiple advantages:
Systems differ in formats, schemas, update frequencies, and quality. Pattern changes in sources can break pipelines if not monitored.
Business rules evolve; some data is incomplete or poorly structured. Handling ambiguity requires clear documentation and ongoing testing.
As data volume grows, transformations become more resource-intensive. Solutions include incremental processing, parallel execution, or shifting to ELT or streaming architectures.
Pipelines degrade if new sources are added or rules change. A modular, testable architecture ensures long-term maintainability.
Pipelines must integrate validation checks, profiling tools, and lineage tracking to ensure accuracy and transparency.
Traditional ETL may be too slow for real-time dashboards, anomaly detection, or event-driven workflows. Streaming ETL or ELT architectures remove bottlenecks.
When documents are involved, additional complexity emerges: table detection, multi-page variability, field extraction, or handwriting recognition. Advanced table detection often improves downstream reliability.
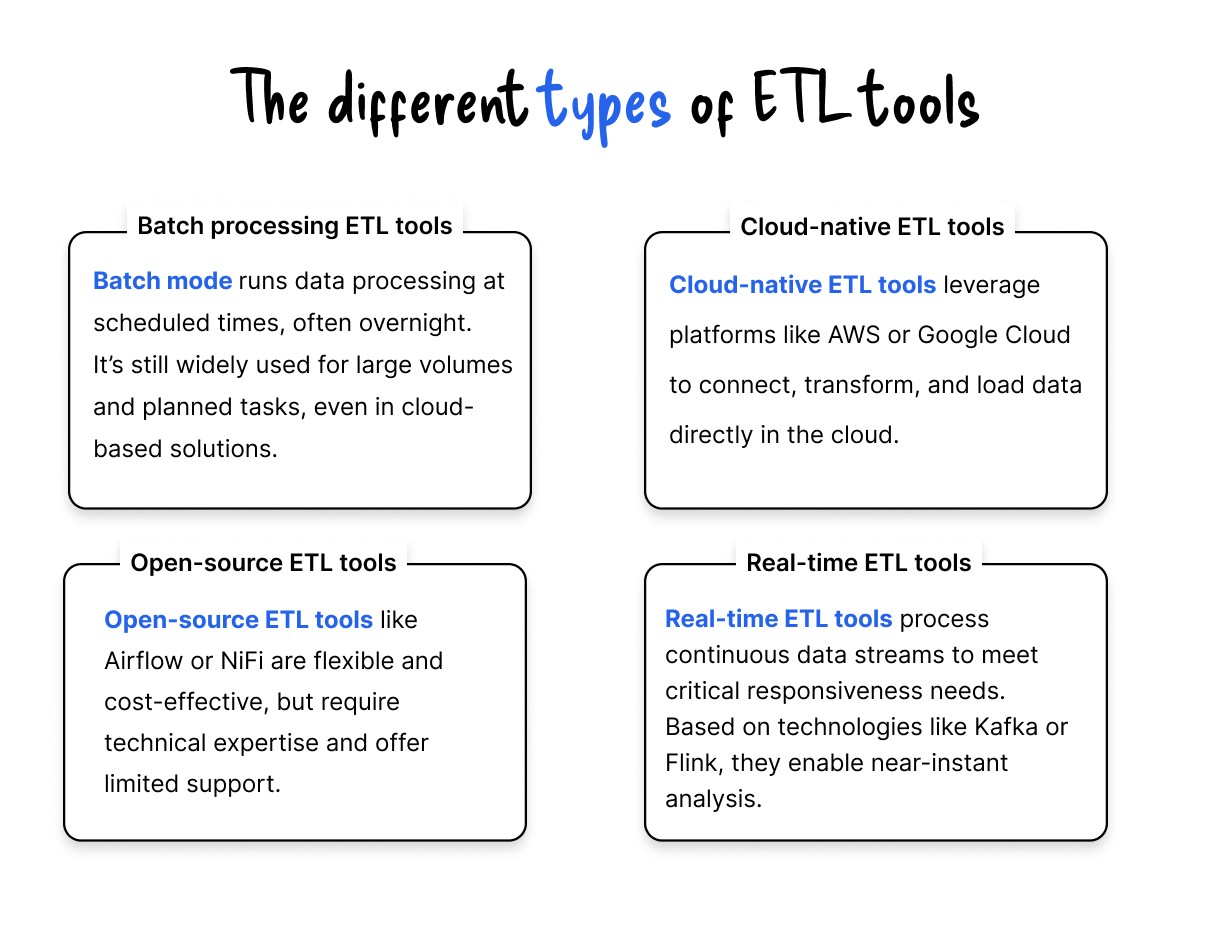
The ETL market offers several categories of tools depending on environment, volume, real-time needs, and budget:
Each category addresses different business constraints. Choosing the right solution requires analyzing context, volumes, and operational maturity.
The market now offers numerous ETL tools, ranging from open-source solutions to comprehensive business platforms.
Here are three representative tools with complementary positions: Talend, Apache NiFi and Informatica.
.webp)
Talend is a widely used solution for data integration, available in an open-source version (Talend Open Studio) and a commercial version (Talend Data Fabric).
Talend is appreciated for its versatility and its ability to adapt to hybrid architectures, including with data science tools.
.webp)
Apache NiFi is an open-source tool that focuses on processing data in a continuous flow. It allows pipelines to be designed visually via an intuitive web interface without coding.
NiFi is particularly suited to environments requiring immediate responsiveness, while offering great modularity.
.webp)
Informatica PowerCenter is a commercial solution recognized for its performance in a production environment. It is based on an engine metadata-driven, facilitating the documentation and governance of flows
Informatica is preferred by large organizations for critical projects where robustness and support are essential.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Tristan Thommen designs and deploys the core technologies that transform unstructured documents into actionable data. He combines AI, OCR, and business logic to make life easier for operational teams.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


