


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité
.webp)
Dernière mise à jour :
December 4, 2025
5 minutes
Les solutions ETL jouent un rôle central en simplifiant la gestion, le nettoyage, l'enrichissement et la consolidation des données provenant de diverses sources. Dans cet article de blog, nous allons expliquer clairement ce qu’est l’ETL, son processus, quels bénéfices il apporte aux organisations, des exemples concrets d’utilisation, ainsi qu’un panorama de quelques outils ETL populaires avec leurs avantages respectifs.
L’ETL permet d’extraire, transformer et charger des données pour les rendre exploitables. Ce guide complet vous aide à en comprendre les enjeux, les étapes et les solutions du marché.

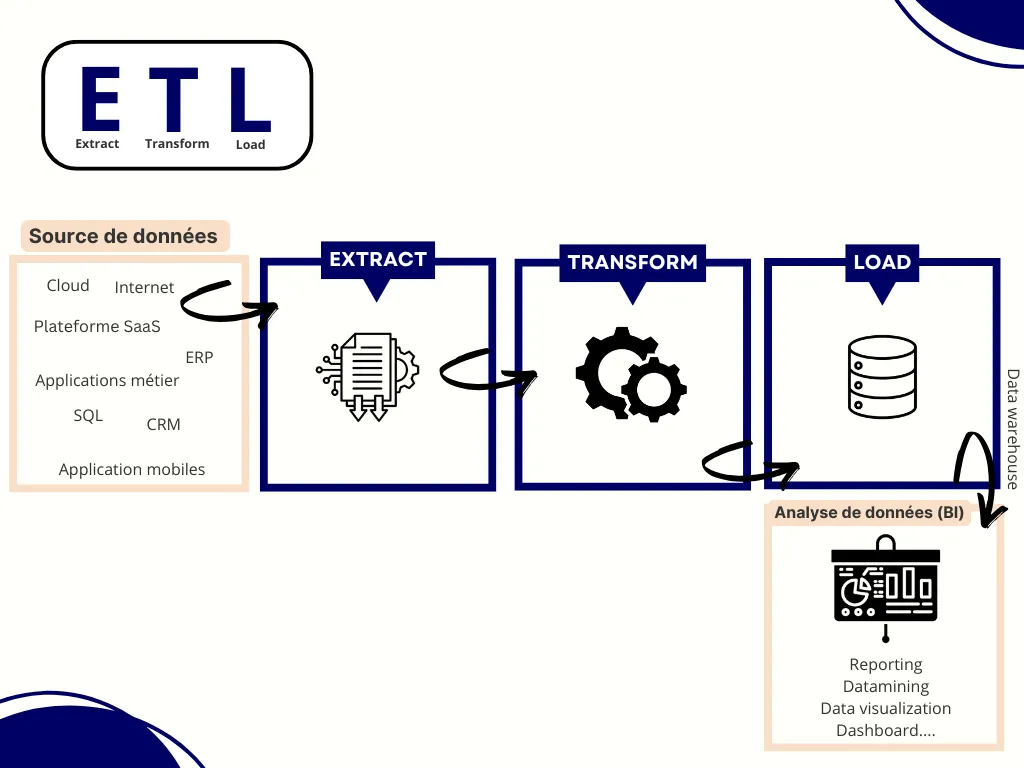
L’ETL, pour Extract, Transform, Load, désigne un processus d’intégration de données qui combine trois opérations essentielles : extraire la donnée depuis différentes sources, la transformer pour la rendre cohérente, puis la charger dans un système cible comme un entrepôt de données ou un data lake.
L’objectif est simple : prendre des données brutes dispersées, souvent hétérogènes, et les convertir en un ensemble structuré et exploitable pour les analyses, les tableaux de bord, la conformité, ou les applications métiers.
L’ETL constitue encore aujourd’hui un pilier de l’ingénierie des données, même s’il cohabite désormais avec des approches plus modernes comme l’ELT ou le streaming.
Le processus ETL classique repose sur trois grandes étapes :
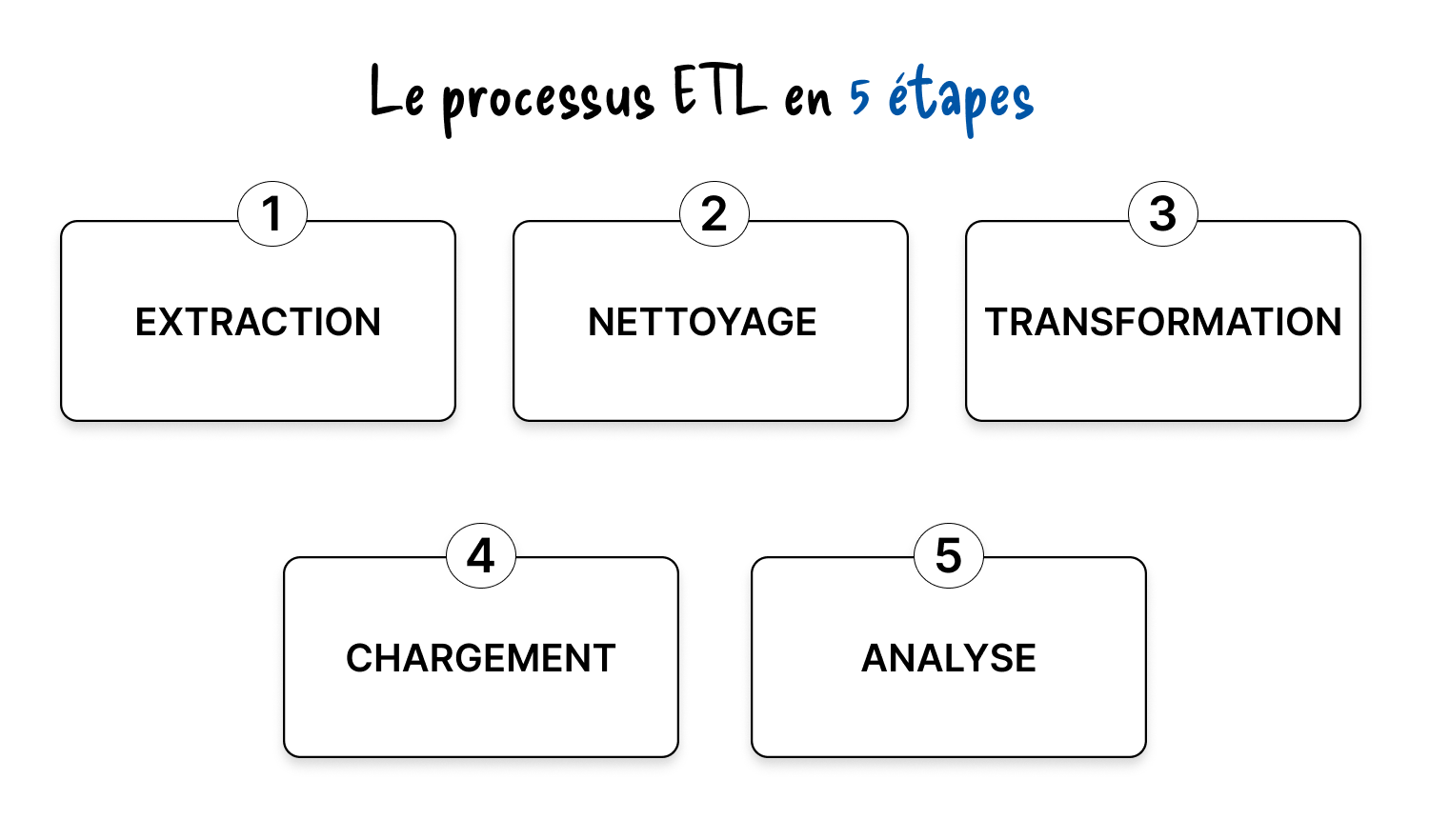
Mais dans la pratique opérationnelle, beaucoup d’équipes data travaillent en réalité selon un cycle en cinq étapes :
Ces étapes sont orchestrées au sein de pipelines automatisés, sur des cadences variables : batch, temps réel, streaming continu…
L’extraction consiste à récupérer des données issues de sources internes (ERP, CRM, bases SQL, fichiers Excel, API internes) ou externes (API publiques, services partenaires, open data…).
Ces données peuvent être structurées (SQL), semi-structurées (JSON), ou non structurées (PDF, logs, images, emails…).
Elles transitent généralement par une zone intermédiaire, avant transformation.
Trois grandes méthodes d’extraction existent :
• Extraction complète : tout extraire à chaque cycle. Pratique pour un premier chargement ou de petits volumes.
• Extraction incrémentale : ne prendre que les données nouvelles ou modifiées, indispensable pour les gros volumes.
• Notification de mise à jour : la source prévient lorsque la donnée change. C’est la base du near real time.
Avant toute transformation avancée, les données doivent être nettoyées. C’est l’une des étapes les plus critiques de l’ETL, car elle conditionne la qualité finale du pipeline.
Le nettoyage inclut :
• Suppression des doublons
• Correction des valeurs erronées
• Gestion des valeurs manquantes
• Normalisation (encodages, formats de dates, unités…)
• Détection d’anomalies simples
Une donnée mal nettoyée peut fausser un modèle, un reporting ou un calcul métier. Cette étape assure la cohérence et la qualité globale du pipeline.
La transformation adapte les données aux besoins métiers, aux contraintes techniques ou aux modèles d’analyse.
Elle inclut notamment :
• Conversions de formats (dates, devises, unités…)
• Jointures entre plusieurs sources
• Calculs métiers : marges, indicateurs globaux, regroupements…
• Création de champs dérivés utiles aux analyses
• Chiffrement ou masquage des données sensibles (RGPD, conformité)
• Normalisation ou dénormalisation des schémas selon la stratégie choisie
Le but est d’obtenir une donnée hautement qualitative, exploitable telle quelle dans un entrepôt ou un data lake.
Une fois transformées, les données sont envoyées vers un système cible : data warehouse, data lake, moteur d’analytique, outil de BI, ou encore applications métiers.
Plusieurs stratégies de chargement existent :
• Chargement complet : remplacement total à chaque cycle
• Chargement incrémental : ajout / mise à jour des données modifiées
• Chargement par lots (batch) : exécution planifiée
• Streaming : alimentation en flux continu
• Bulk load : transfert massif optimisé
À ce stade, les données deviennent accessibles pour les équipes métiers, la BI, ou les modèles de machine learning.
Une fois centralisées et nettoyées, les données servent à :
• Construire des dashboards fiables
• Alimenter les reporting automatisés
• Déclencher des alertes ou des workflows
• Entraîner des modèles prédictifs
• Croiser des volumes massifs de données métiers
L’ETL rend possible l’exploitation de données multi-sources au service de la performance opérationnelle.
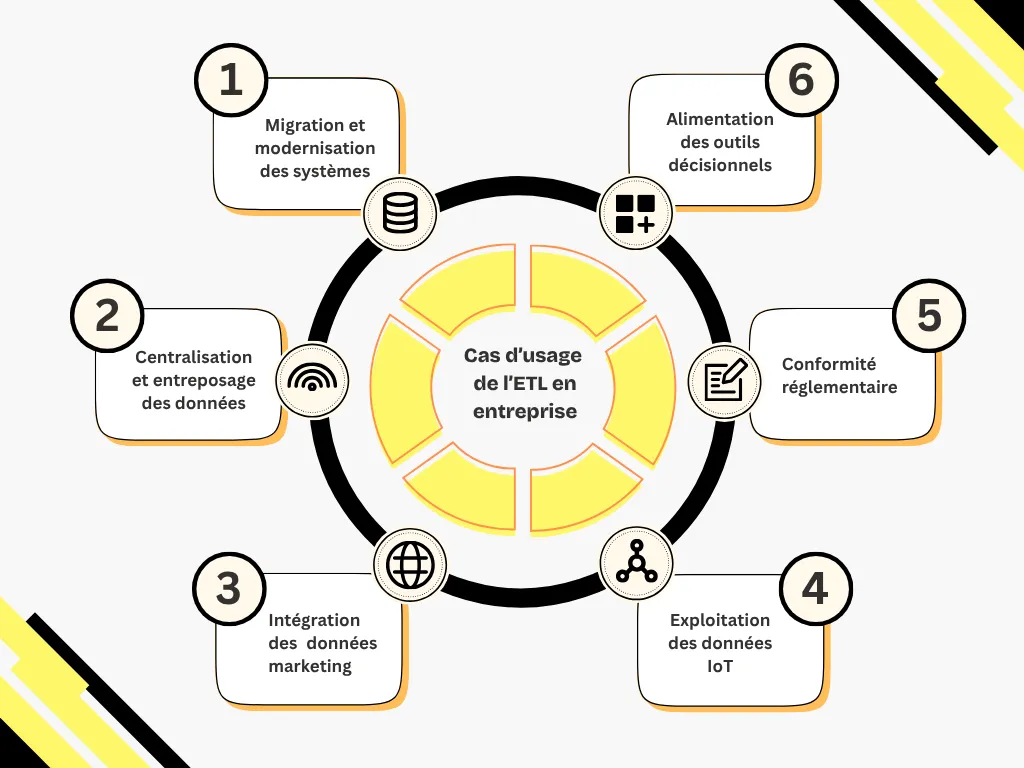
L’ETL intervient dans la majorité des projets où la donnée doit être synchronisée, nettoyée, consolidée ou gouvernée.
Lors d’un changement d’ERP, de CRM ou d’infrastructure, l’ETL gère la migration des données depuis les anciens systèmes. Il permet également de synchroniser plusieurs systèmes sans interrompre les opérations.
L’ETL collecte des données hétérogènes (ERP, CRM, fichiers, API…) et les transforme afin d’alimenter un entrepôt de données.
Cette centralisation permet des analyses transversales fiables.
L’ETL structure les données clients issues de sources variées : e-commerce, réseaux sociaux, campagnes, CRM…
Il ouvre la voie à :
• Une meilleure segmentation
• Des analyses du parcours client
• Des actions personnalisées
Dans l’industrie ou la logistique, les objets connectés produisent des volumes massifs de signaux.
L’ETL sert à :
• Collecter en continu
• Standardiser
• Enrichir
• Préparer les données pour la maintenance prédictive ou l’optimisation opérationnelle
L’ETL assure :
• Identification des données sensibles
• Transformation ou anonymisation
• Traçabilité complète
• Aide à la conformité (RGPD, HIPAA, CCPA…)
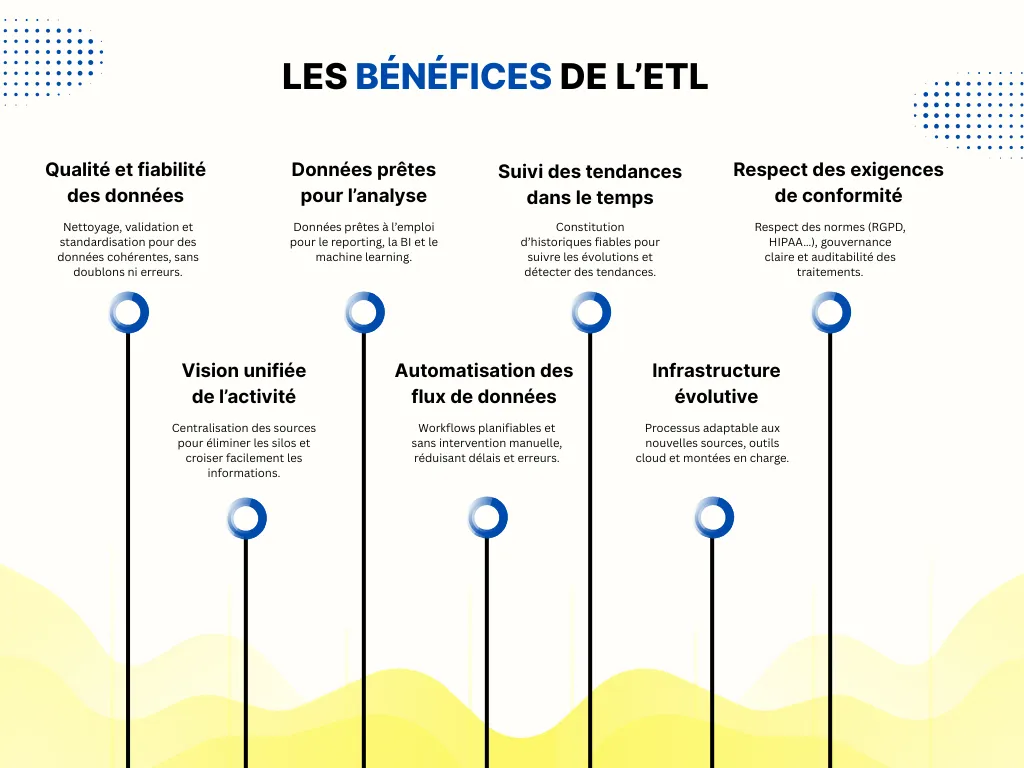
Les avantages concrets incluent :
• Amélioration de la qualité des données
• Automatisation des flux et réduction des tâches manuelles
• Vision consolidée de l’activité
• Accélération des analyses et de la prise de décision
• Réduction des erreurs humaines
• Meilleure gouvernance de la donnée
Même si l’ETL est puissant, plusieurs points d’attention doivent être anticipés.
Chaque source a son propre format et rythme de mise à jour.
Un pipeline peut devenir instable si un schéma change ou si une API devient intermittente.
Les données peuvent être :
• Incomplètes
• Mal formatées
• Soumises à des règles métiers changeantes
Une mauvaise transformation peut invalider des analyses.
D’où l’importance des tests, de la documentation et de la gouvernance.
Lorsque les volumes augmentent, les pipelines doivent rester rapides et fiables.
Cela implique :
• Traitement incrémental
• Parallélisation
• Optimisations techniques
• Éventuel passage à l’ELT ou au streaming
Les pipelines doivent être :
• Modulaires
• Testables
• Adaptés aux changements réguliers
• Faciles à faire évoluer
Sans cela, les coûts de maintenance explosent.
Il faut intégrer :
• Des contrôles automatiques
• Du data profiling
• De la data lineage pour suivre l’historique de chaque donnée
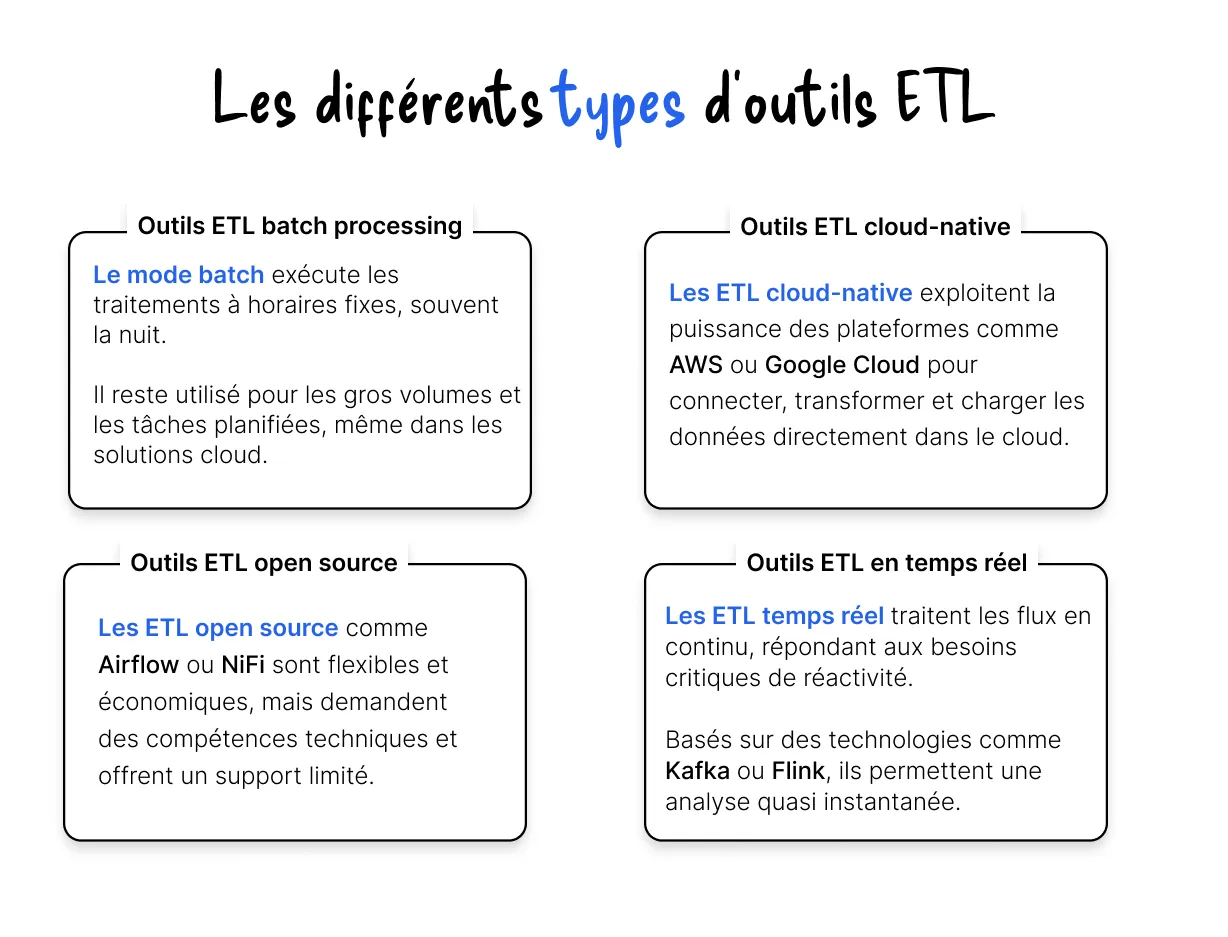
Quatre grandes familles existent :
• Outils ETL traditionnels (Talend, Informatica)
• Outils cloud natifs (AWS Glue, Azure Data Factory)
• Outils open source (Apache NiFi, Airbyte)
• Outils orientés streaming (Kafka Streams, Spark Streaming)
Chaque famille répond à des besoins techniques distincts.
Le marché propose aujourd’hui de nombreux outils ETL, allant des logiciels OCR open source aux plateformes commerciales complètes.
Voici trois outils représentatifs aux positionnements complémentaires : Talend, Apache NiFi et Informatica.
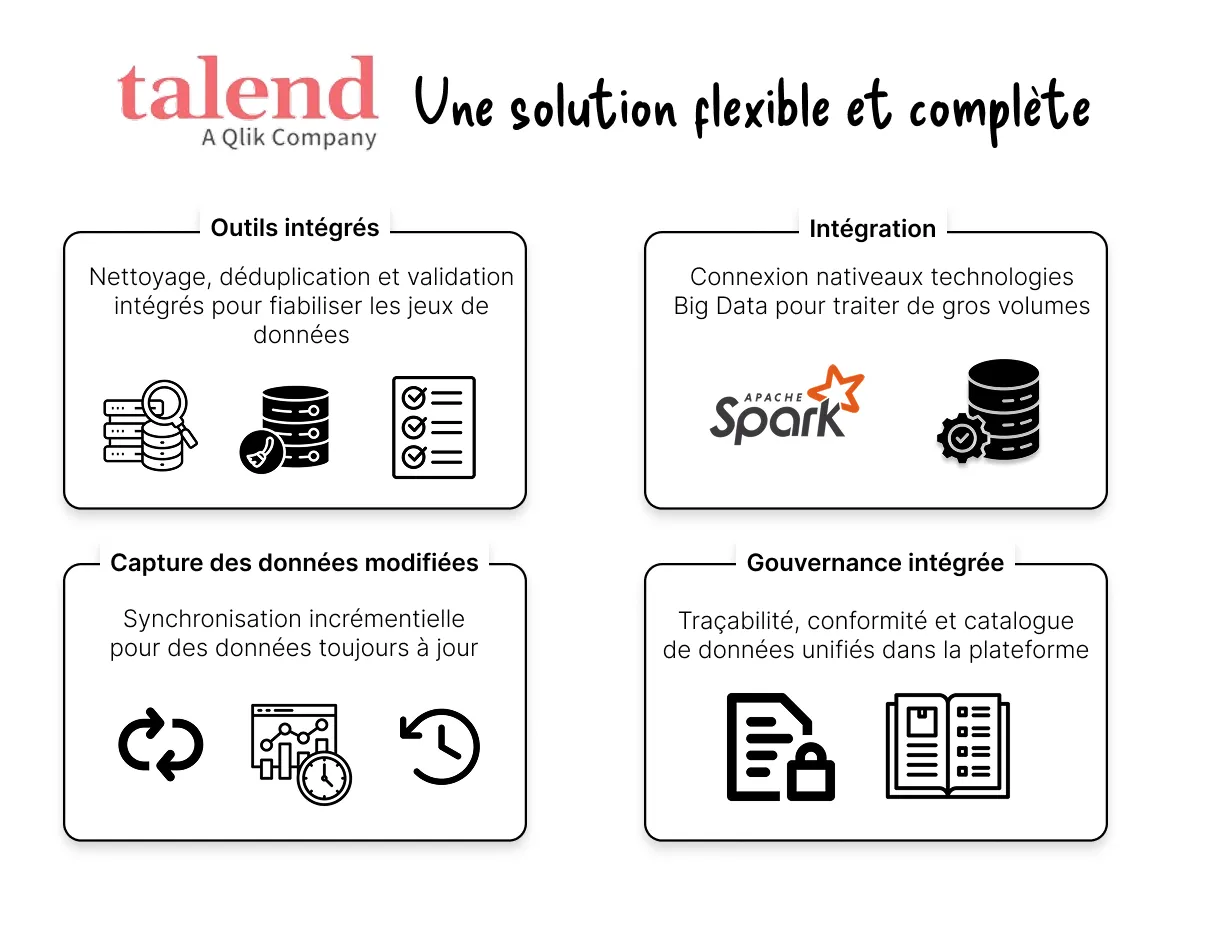
Talend est une solution largement utilisée pour l’intégration de données, disponible en version open source (Talend Open Studio) et commerciale (Talend Data Fabric).
Talend est apprécié pour sa polyvalence et sa capacité à s’adapter à des architectures hybrides, y compris avec des outils de data science.

Apache NiFi est un outil open source axé sur le traitement des données en flux continu. Il permet de concevoir visuellement des pipelines via une interface web intuitive, sans codage.
NiFi est particulièrement adapté aux environnements nécessitant une réactivité immédiate, tout en offrant une grande modularité.
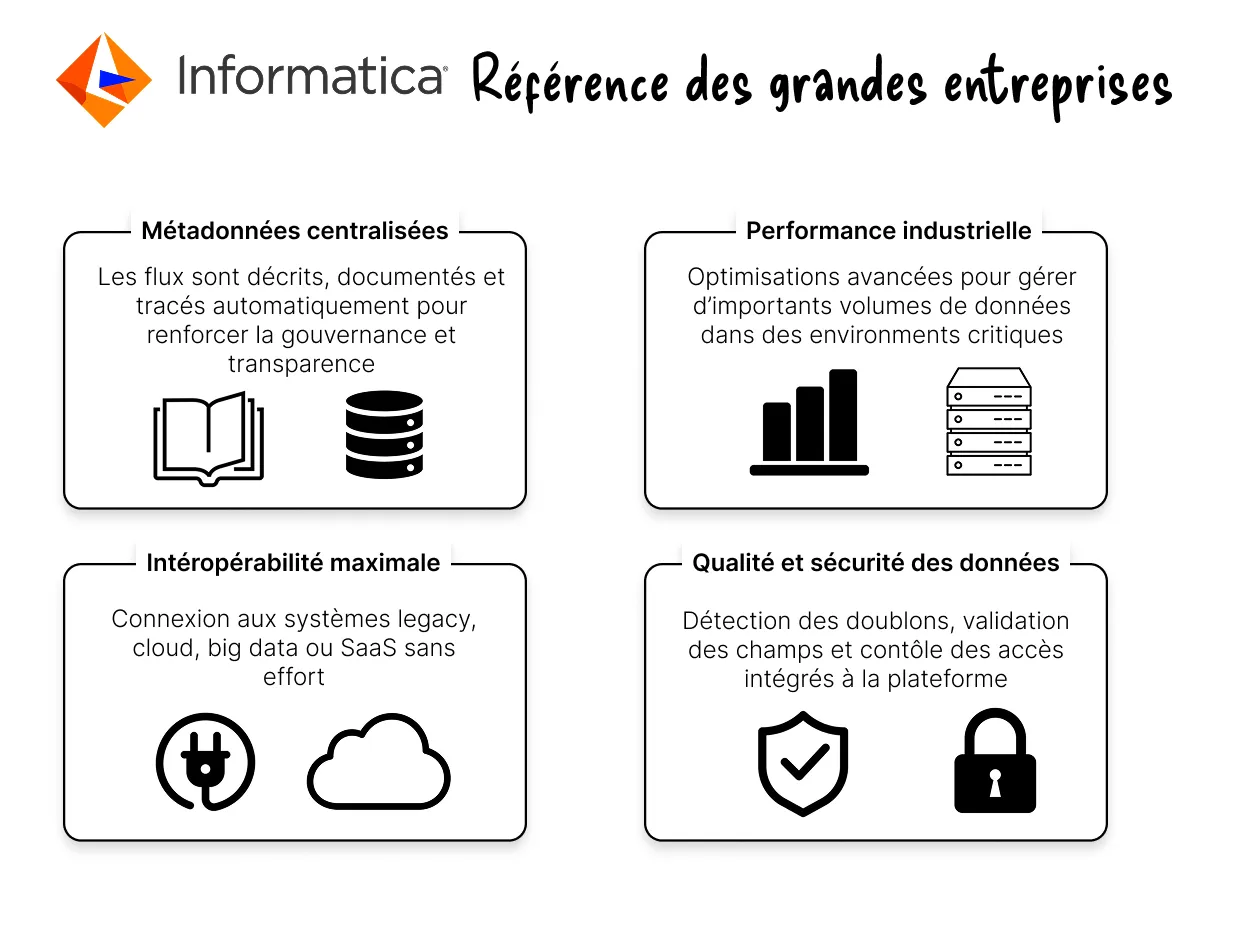
Informatica PowerCenter est une solution commerciale reconnue pour ses performances en environnement de production. Elle repose sur un moteur piloté par les métadonnées, facilitant la documentation et la gouvernance des flux
Informatica est privilégié par les grandes structures pour des projets critiques où la robustesse et le support sont essentiels.
L’ETL demeure un pilier de la gestion des données modernes.
Malgré l’essor du streaming ou de l’ELT, il reste indispensable pour garantir qualité, cohérence, centralisation et gouvernance.
Le choix d’un outil dépendra toujours du contexte métier, des volumes, des contraintes opérationnelles et du niveau d’automatisation souhaité.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Tristan Thommen conçoit et déploie les briques technologiques qui transforment des documents non structurés en données exploitables. Il allie IA, OCR et logique métier pour simplifier la vie des équipes.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


