


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
September 8, 2025
5 minutes
Grâce à l’API Koncile et son interface Swagger, vous pouvez transformer n’importe quel fichier PDF en fichier JSON structuré, prêt à être utilisé dans un logiciel de comptabilité, un CRM ou un ERP. Voici un guide pas à pas pour effectuer cette conversion simplement, sans avoir à coder.
Découvrez comment transformer ces documents en JSON structuré pour les exploiter automatiquement dans vos outils métiers (compta, CRM, ERP…). Grâce à l’API Koncile, convertissez vos PDF en données prêtes à l’emploi, sans coder. Ce guide complet vous explique pas à pas comment automatiser ce processus, que vous soyez développeur ou non.

Koncile propose une solution clé-en-main pour transformer vos PDF en JSON structuré, même pour des documents complexes ou manuscrits grâce à son logiciel OCR de nouvelle génération.
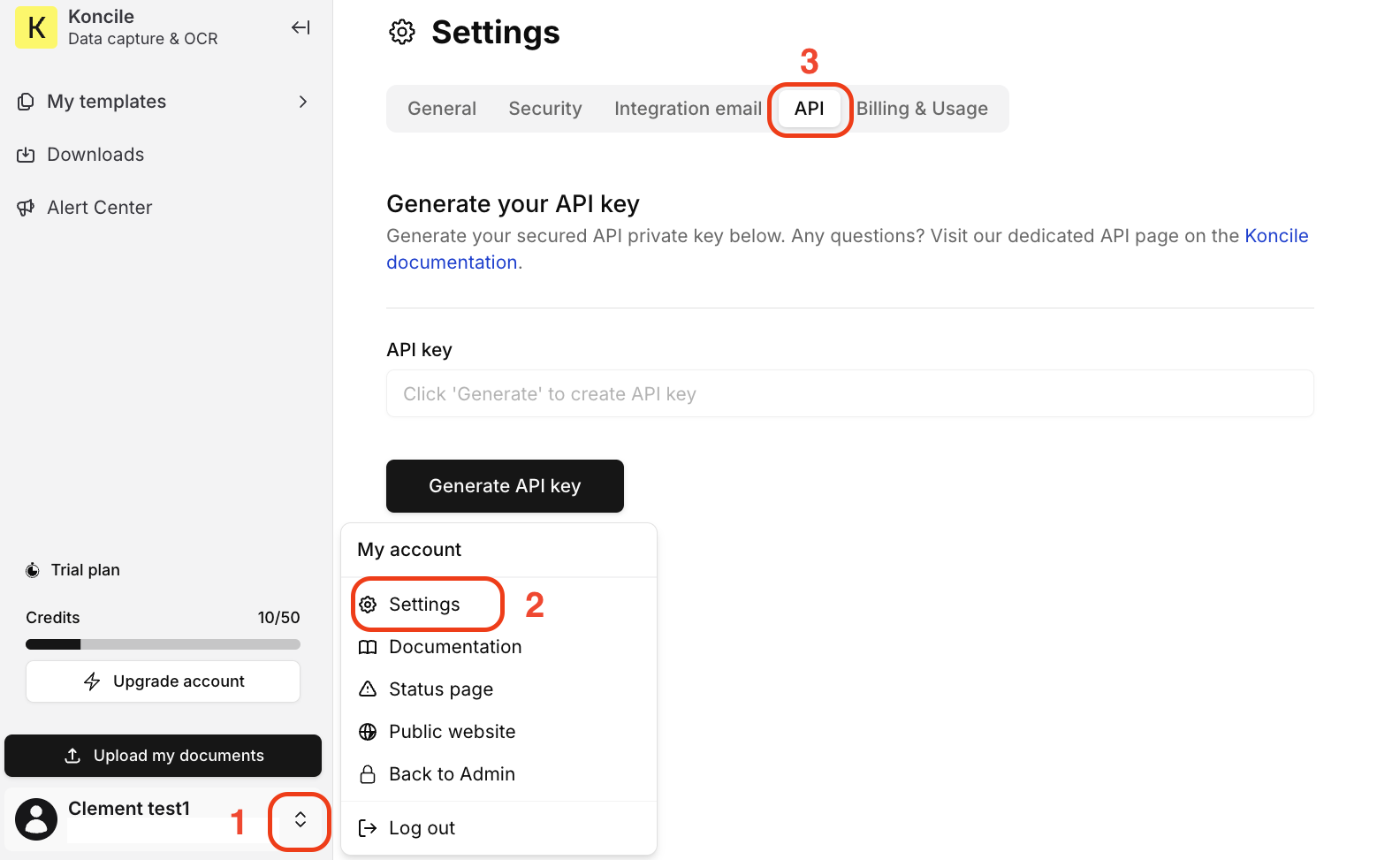
Pour établir une connexion sécurisée avec l’API Koncile, commencez par vous rendre dans les paramètres de votre compte (réservé aux administrateurs).
Accédez à l’onglet API, puis cliquez sur “Générer une clé API” pour obtenir votre clé d’accès personnelle.
Rendez-vous sur la documentation Swagger de Koncile à l’adresse suivante : https://api.koncile.ai/documentation
Puis sélectionnez l’endpoint : POST /v1/upload_file/ – Upload File

C’est ici que vous pourrez envoyer un document une fois la connexion établie.
C’est ici que vous pourrez envoyer un document une fois la connexion établie.
Activez l’authentification
value.
Une fois authentifié, vous pouvez préparer l’envoi de votre fichier à convertir :
Renseignez les paramètres optionnels
Vous avez la possibilité d’ajouter dans les champs prévus :

Ajoutez votre fichier dans le Request Body
Descendez dans la section "Request Body" et uploadez le fichier PDF que vous souhaitez convertir au format JSON.

Lancez l’envoi
Cliquez ensuite sur "Execute" pour lancer la requête.
Dans la section "Responses", un task_id vous sera retourné : il vous permettra de récupérer le fichier converti au format JSON à l’étape suivante.

Une fois le document envoyé, vous pouvez récupérer les données extraites en JSON :
1. Rendez-vous dans l’endpoint suivant, situé juste en dessous dans la documentation Swagger : GET /v1/fetch_tasks_results/ – Fetch Tasks Result
2. Dans le champ prévu, collez le task_id obtenu lors de l’étape précédente.

3. Cliquez sur "Execute" pour lancer la requête.
L’API vous retourne alors un fichier JSON structuré contenant toutes les informations extraites automatiquement du document envoyé que vous pouvez ensuite copier ou download directement.

Koncile propose une solution clé-en-main pour transformer vos PDF en en JSON structuré même lorsqu’il s’agit de documents complexes ou de qualité moyenne (scans, photos, manuscrits).
ces données peuvent être utilisées pour :
Pour les développeurs de votre équipe
Koncile fournit :
Bonne nouvelle : il n’est pas nécessaire d’être développeur pour exploiter la puissance du JSON. Grâce à l’émergence des outils no-code et low-code, de nombreuses entreprises peuvent aujourd’hui automatiser leur traitement documentaire sans écrire une ligne de code.
Intégrer directement vos outils du quotidien comme Slack, Google Drive, Drobox


Exemples d'intégration no-code simples avec des plateformes comme :
Ce que vous pouvez faire sans coder :
C’est l’assurance de gagner en productivité, sans dépendre systématiquement de l’équipe technique

Ainsi, Make par exemple, permet de créer un scénario automatisé : dès qu’un PDF est ajouté dans Google Drive, il est envoyé à l’API Koncile pour analyse. Une fois le fichier converti en JSON, les données peuvent être automatiquement récupérées et stockées ou utilisées dans un autre outil, sans écrire de code.

Le PDF est un format universel : il est utilisé partout dans le monde pour transmettre des documents commerciaux, juridiques, comptables, administratifs… Mais s’il est idéal pour la lecture humaine, il l’est beaucoup moins pour le traitement automatisé. À l’inverse, le JSON est un format structuré, conçu pour que les machines puissent comprendre et réutiliser facilement les données.
Transformer un PDF en JSON, c’est donc rendre son contenu exploitable automatiquement par vos logiciels métiers via une API. C’est une étape clé pour gagner en efficacité, réduire les erreurs humaines, et automatiser vos processus internes.
Même lorsqu’il est généré numériquement, un fichier PDF reste difficile à exploiter automatiquement. Certaines factures ou documents scannés présentent des variations qui compliquent l’extraction :
Résultat : ces documents, souvent semi-structurés voire non structurés, nécessitent encore une intervention humaine pour être compris… sauf si l’on passe par un traitement OCR avec export en JSON.

Pour que vos outils métier puissent comprendre un document, il faut en extraire les données sous un format structuré. C’est là que le JSON entre en jeu.
Ce format léger et universel permet de représenter les données sous forme de paires clé/valeur. Concrètement, cela revient à transformer un PDF statique en un fichier “intelligent” : lisible par une machine, exploitable par une API, intégrable dans vos logiciels métiers.
Il existe aujourd’hui plusieurs solutions pour transformer un PDF en JSON. Le choix dépend de la nature du document (texte ou image) et du niveau d’automatisation souhaité.
La conversion PDF → JSON représente un travail fondamental pour transformer des documents statiques en données dynamiques. Grâce à la structuration et l’automatisation via API, vous gagnez en fiabilité, rapidité et performance dans la gestion documentaire.
Intégrez ces données structurées directement dans vos systèmes métiers pour assurer un traitement fiable, rapide et parfaitement intégré à vos processus comptables, analytiques ou opérationnels.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


