


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
June 15, 2026
5 minutes
OpenCV is one of the most widely used computer vision libraries in Python. But can it really detect document fraud? In this article, we test OpenCV on several real-world falsification scenarios: amount modification, signature copy-paste, inpainting removal, and compression analysis (ELA). The objective is simple: understand what visual detection can actually identify and where its limits are.
Document fraud detection with OpenCV in Python: real tests and limitations.

Document digitization brings many advantages. Both in terms of execution speed and logistics, and today many solutions offer document automation to increase productivity. However, automation is nothing without control. At this stage of automation, data verification and authentication are becoming central issues. A very large volume of documents is processed daily, and within that flow there is a significant number of falsified documents. Today, I’m going to present an open-source visual fraud detection solution: OpenCV.
OpenCV is an open-source library that relies on visual detection to analyze documents. More precisely, we are talking about computer vision. It is a branch of artificial intelligence specialized in analyzing digital images. It allows us to detect modifications that are invisible to humans and therefore avoid certain cases of document falsification.
This issue is not limited to the visual aspect of documents, but visual analysis is clearly one part of document fraud detection.
OpenCV analyzes only the visual rendering of a document, meaning the pixels that compose the final image. This means that a structural modification made directly inside a native PDF, for example through an editor like Adobe Acrobat, will not necessarily be detected if the visual rendering remains perfectly consistent.
In other words:
If an amount is modified inside a vector-based PDF and cleanly rewritten by the software, OpenCV will see nothing. On the other hand, if a visual modification is applied to a scan or image, such as copy-paste, digital text insertion, removal, or local retouching, OpenCV can in many cases detect pixel anomalies or texture inconsistencies.
OpenCV can be used in many document fraud detection scenarios. Because it is limited to the visual layer of a document, it will detect visual falsifications only. We are talking here about visual anomalies, pixel inconsistencies, and texture ruptures. OpenCV is useful only when detecting visual modifications made to a document image.
The tests I’m presenting today were conducted around the following cases:
Documents can be modified in different ways using various tools, from simple to advanced. When it comes to visual manipulation, these changes are usually performed using software such as Adobe Photoshop, GIMP, Canva, Paint, and similar tools.

For the test document, I chose a US-format invoice. I changed the original unit price from $1000 to $1200 and adjusted the related totals, including the line total and global total. I performed two different tests to answer a double question.
Test 1: Direct modification of a clean Canva template using Photoshop and exporting as JPG (native digital document).

Test 2: Modification of a scanned document with added digital text, exported as JPG.

For the document modified from a clean digital template, OpenCV did not detect any incoherent zones in the heatmap. The modification is too clean. The document remains visually homogeneous.

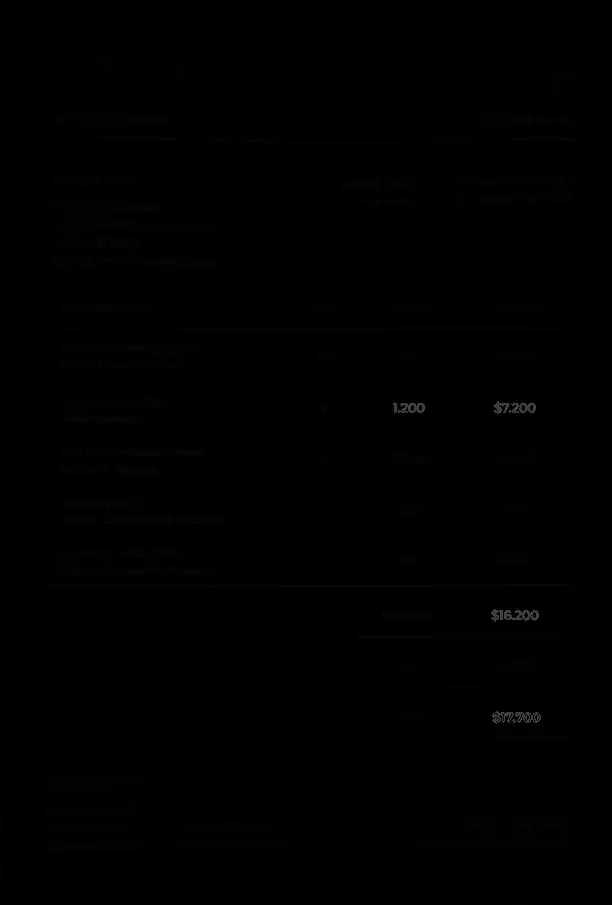
This second test is much more conclusive. On a scanned document, the modification was detected. The altered fields clearly appear in the output analysis.
In theory, it would be possible to test detection through simple internal duplication, such as copying a logo or signature already present in the document so that OpenCV identifies a repeated zone. However, it is more interesting to test this using a concrete fraud scenario. For this test, I used an invoice to which I added a signature imported from another document. For the second test, the same document was globally recompressed to observe whether visual detection would still be possible when pixel differences were attenuated.

After a simple analysis like the previous documents, the rendering did not clearly show the modification. I therefore adjusted the output settings. Each anomalous zone appears in white. This improved the contrast and produced a conclusive result. The noise difference is detected and the imported signature clearly stands out.

In this case, the differences were attenuated through global compression during JPG export. The compression is visible in the analysis rendering, and it becomes impossible to identify the added signature. This demonstrates something important about document falsification. A more advanced modification can neutralize OpenCV. Pure visual inconsistency detection is no longer sufficient. A deeper analysis of the document would be required, for example through metadata inspection.

For this test, I compared two falsification methods applied to the same document: my scanned US-format invoice where I removed the last product line. In the first case, I performed a subtle removal that is difficult to notice with the naked eye but likely to generate a statistical rupture detectable by OpenCV. In the second case, I used more advanced editing tools to integrate the removal more homogeneously. The goal was to evaluate whether visual detection remains possible or if the signal becomes too weak.

The result is clear. The removal performed with a simple tool was strongly detected by OpenCV. The erased line is clearly visible in the output.

With more advanced editing in Photoshop, the result is different. The modified area is not visually detected even though it has been altered. At this stage, we come back to metadata analysis as a complementary method. It would allow us to detect that the document was exported from Photoshop, whereas this type of document is normally expected to come from a more administrative software environment.

One might think that ELA (Error Level Analysis) is exactly what we used earlier to detect signature import or removal. However, there is a nuance. The previous method was localized detection. A zone with different noise characteristics compared to the rest of the document. Here, ELA does not analyze global coherence but rather reveals local inconsistencies that appear when the image is subjected to controlled recompression. The principle is simple. We take the suspicious image, recompress it in JPEG with a chosen quality level, then compare this recompressed version with the original. We measure the difference between the two.
If the document was modified locally through insertion, removal, or collage, certain areas may not react in the same way during recompression. These differences can then become visible in the ELA map.
For this method, I decided to retest the document that had previously failed under global recompression in the signature import scenario. I wanted to see whether ELA would allow better detection. Then I tested the same document without global recompression.
In this test, OpenCV did not detect anything obvious at first glance. Since the image was already homogeneous in compression, recompression did not add much information. I then amplified the contrast of the output. The result becomes more interesting. A slight noise difference appears in the imported zone. ELA can be effective on documents with homogeneous compression, which was not the case for previous methods.

In this case, the test worked but not as expected. The compression difference is visible, but the rendering is highly heterogeneous. Because the document had not been globally compressed beforehand, many artifacts appear and visually pollute the result. The imported signature does not clearly stand out. In the end, ELA proved more effective on a document with more advanced modification. These two compression analysis tests show that ELA is an additional verification layer, but it does not overcome the technical limitations of visual detection. With proper output optimization, however, it can be useful on more complex documents.

The tests show a simple reality: effectiveness depends heavily on document type and on how well the modification is integrated. Amount modification is detectable on a scanned document with natural noise but not on a clean digital file. Signature copy-paste is detectable when texture differences remain, but detection weakens significantly after homogeneous recompression. Basic removal is easily detected, while advanced blending becomes much harder to identify. ELA adds another verification layer but remains sensitive to initial compression levels and can produce noisy outputs.
In short, visual methods work well against simple or poorly integrated modifications, but they lose efficiency against fully homogenized edits.
If we focus strictly on visual image analysis, several alternatives exist.
scikit-image is a Python library oriented toward scientific image analysis, including texture and structural similarity studies.
ImageMagick is a command-line tool capable of image comparison and visual difference detection.
Forensically is a web-based forensic tool providing ELA, clone detection, and noise analysis.
The MATLAB Image Processing Toolbox offers more academic-level advanced image analysis.
OpenCV remains one of the most flexible solutions for integrating visual fraud detection into an automated pipeline.
What we should take away from this article is that OpenCV performs well within its visual scope when properly configured. Obvious visual alterations and even some more advanced edits can be detected, helping prevent certain types of fraud. More broadly, document fraud is not solved by a single detection layer. Each document should be analyzed through multiple methods, including visual inspection, semantic analysis, and metadata verification. It is this combination of layers that provides a reliable assessment of authenticity. Ultimately, organizations should implement a comprehensive fraud detection system that brings all these capabilities together.
So yes, OpenCV is a good solution as one building block within a larger system. For the other verification layers, there are dedicated document fraud detection tools that automate the full workflow.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


