


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
June 19, 2026
5 minutes
OpenCV est l’une des bibliothèques de computer vision les plus utilisées en Python. Mais peut-elle réellement détecter une fraude documentaire ? Dans cet article, nous testons OpenCV sur différents scénarios concrets de falsification : modification de montant, copier-coller de signature, effacement par inpainting et analyse de compression (ELA). L’objectif est simple : comprendre ce que la détection visuelle permet réellement d’identifier et où se situent ses limites.
Détection de fraude documentaire avec OpenCV en Python : tests réels et limites.

La numérisation des documents apporte plein d’avantages. Tant sur la rapidité d’exécution que sur la logistique, et aujourd’hui plein de solutions proposent de l’automatisation de documents pour accroître cette productivité. Cependant celle-ci n’est rien sans le contrôle.
À cette heure de l’automatisation, la vérification et l’authentification des données deviennent une problématique centrale. Une très grande quantité de documents est traitée et dans le lot il y a un nombre significatif de fraudes par falsification. Je vais donc vous présenter aujourd’hui une solution open source de détection visuelle de falsification : OpenCV
La librairie OpenCV est une solution open source qui s’appuie sur la détection visuelle pour analyser les documents. Plus précisément, il s’agit ici de Computer Vision, détection par ordinateur. C’est une sous-branche de l’intelligence artificielle qui est spécialisée dans l’analyse d’images numériques. Elle permet de détecter des modifications invisibles pour les humains et ainsi d'éviter des cas de falsification de documents.
Cette problématique ne se joue pas uniquement sur le visuel des documents, c’est donc une partie des enjeux de la détection de fraude documentaire.
OpenCV analyse exclusivement le rendu visuel d’un document, c’est-à-dire les pixels qui composent l’image finale.
Cela signifie qu’une modification structurelle effectuée directement dans un PDF natif, par exemple via un éditeur comme Adobe Acrobat, ne sera pas nécessairement détectée si le rendu visuel reste parfaitement cohérent.
Autrement dit :
OpenCv se prête à de nombreux cas d’usages concernant la détection de fraude dans les documents. Étant cloisonné sur le visuel du document, il sera capable de détecter les falsifications visuelles de ces derniers. On parlera alors ici d’anomalies visuelles, d’incohérences de pixels et de rupture de textures. OpenCV est utile uniquement pour détecter les modifications visuelles d’un document inchangé.
En clair, le test que je vous propose aujourd’hui a été réalisé sur ses principales utilisations :
La falsification de facture est l'un des cas les plus fréquents. Les documents peuvent être modifiés par différentes méthodes et différents logiciels plus ou moins poussés. Pour ce qui est des modifications visuelles, celles-ci peuvent être effectuées sur différents logiciels comme : Adobe Photoshop, GIMP, Canva, Paint..

Pour mon document de test, j’ai choisi une facture format US. J’ai changé le montant unitaire du réel pour les réseaux sociaux de 1000$ à 1200$ ainsi que les autres montants liés (total pour la ligne et le total global).
Je vais effectuer 2 tests différents pour répondre à une double question :
1er test : Modification directe d’un template Canva depuis Photoshop en export JPG. (document propre).

2e test : Modification d’un scan avec un texte numérique en export JPG.

Pour le document modifié depuis un template propre, on voit qu’OpenCV ne détecte pas de zones incohérentes sur la heatmap. La modification est trop propre, le document est homogène.

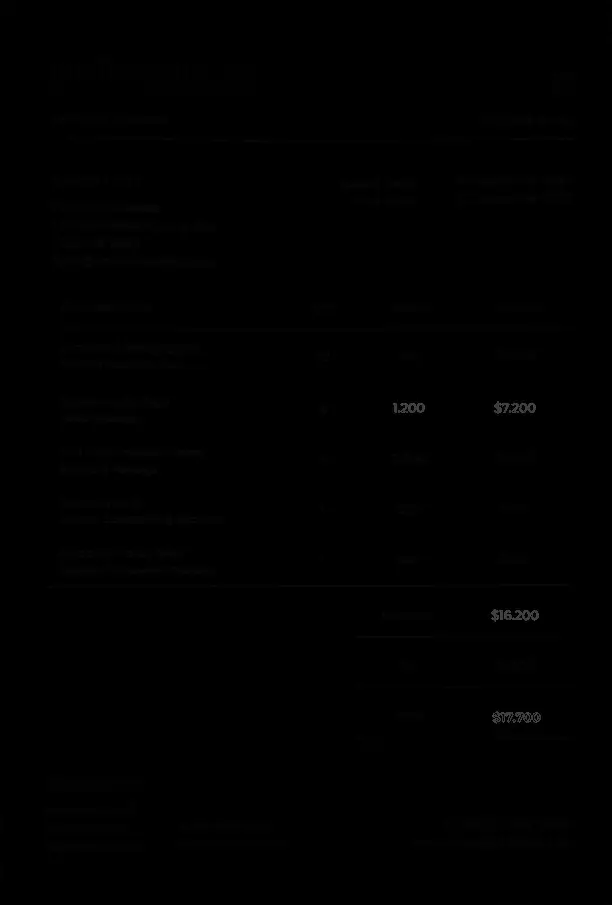
Ce test n°2 est largement plus concluant. Sur un scan, la modification a été détectée. On voit clairement apparaître les champs modifiés sur le document de sortie.
En théorie, il serait possible de tester la détection par simple duplication interne, par exemple en copiant un logo ou une signature déjà présente dans le document afin qu’OpenCV identifie une zone répétée. Mais il est plus intéressant de tester cela avec un cas concret de falsification de document.
Pour ce test, j’ai donc utilisé une facture sur laquelle j’ai ajouté une signature provenant d’un autre document. Pour le second test, ce même document sera recompressé de manière homogène afin d’observer si la détection visuelle reste possible lorsque les différences de pixels et de zone sont atténuées.

Après un simple test comme sur les documents précédents, le format du rendu ne permettait pas de voir les modifications alors, j’ai modifié les caractéristiques du rendu. Chaque zone considérée comme anormale ressort en blanc. Avec cela on obtient un meilleur contraste et un résultat concluant. La différence de bruit est détectée et la signature ressort comme un élément importé.

Pour ce test, les différences ont été atténuées par la compression globale du document à l’export JPG pour le test. On voit bien cette compression sur le rendu de l’analyse, il devient impossible de repérer l’ajout. Cela démontre quelque chose d’important à comprendre dans la falsification documentaire. Cette modification de document plus avancée met OpenCV sur la touche. La seule analyse d’incohérences visuelles ne suffira pas à détecter cette fraude. Il faudra passer par une analyse plus poussée du document, par ses métadonnées par exemple.

Pour ce test, je vais comparer deux méthodes de falsification appliquées au même document : ma fausse facture au format scan sur laquelle j’ai retiré la dernière ligne produit.
Dans un premier cas, j’effectue un effacement discret, difficilement perceptible à l’œil humain, mais susceptible de générer une rupture statistique détectable par OpenCV.
Dans un second cas, j’utilise des outils d’édition plus avancés afin d’intégrer l’effacement de manière plus homogène. L’objectif est d’évaluer si la détection visuelle reste possible ou si le signal devient trop faible.

Au final, le résultat est sans appel. L’effacement avec un outil simple a été très largement détecté par OpenCV. On voit bien sur le document la ligne effacée.

Avec un outil plus avancé sur Photoshop, le résultat est différent, ici on ne voit clairement pas la zone modifiée et pourtant elle l’est. On en revient à la solution de tester l’analyse des métadonnées pour ce document. Cela permettrait de détecter que ce document a été exporté depuis Photoshop, or ce genre de document est normalement attendu sous un export provenant d’un logiciel connoté « plus administratif ».

On pourrait croire que l’analyse de la compression ELA (Error Level Analysis), c’est exactement ce que nous avons utilisé pour détecter l’importation frauduleuse d’une signature et l’effacement. Cependant, il y a une nuance à comprendre. La méthode utilisée plus tôt était de la détection localisée sur le document. Une zone avec un bruit différent qui dénote du reste du document.
Ici, la méthode ELA ne cherche pas la cohérence globale du document, mais plutôt les incohérences locales qui apparaissent lorsqu’on soumet l’image à une recompression contrôlée.
Le principe est simple. On prend l’image suspecte, on la recompresse en JPEG avec un niveau de qualité choisi, puis on compare cette nouvelle version avec l’image initiale. On mesure ensuite la différence entre les deux. Si le document a été modifié localement (ajout, effacement, collage), certaines zones peuvent ne pas réagir exactement de la même manière à cette recompression. Ces écarts peuvent alors apparaître plus visibles dans la carte ELA.
Pour cette méthode, j’ai envie de réessayer le document qui a fait échouer OpenCV avec une recompression globale sur l’import de la signature, pour voir si cette méthode permet une meilleure détection. Ensuite je vais essayer avec le même document mais sans la recompression globale.
Sur ce test, on voit clairement qu’OpenCV n’a rien détecté de pertinent. L’image initiale étant déjà homogène en compression, la surcompression n’a rien donné de plus, en tout cas au premier abord. J'ai fait un deuxième test sur ce document en amplifiant le contraste du rendu. Le résultat est encourageant. On arrive à détecter une légère différence de bruit sur la zone importée. La méthode ELA peut être efficace sur les documents avec des compressions homogènes, ce qui n’est pas le cas pour les méthodes précédentes.

Ici, le test a fonctionné mais pas comme je l’attendais. On peut facilement voir la différence de compression sur la zone de la signature, mais le rendu est très hétérogène. Le fait que ce dernier n’ait pas été préalablement compressé fait apparaître des artefacts parasites qui, au final, font perdre de vue la zone importée de la signature. D’autant plus que la méthode ELA accentue globalement ces artefacts avec la recompression.
Au final, la méthode ELA aura été plus efficace sur un document avec des modifications avancées. Ces deux tests d’analyse de compression permettent de conclure que cette méthode est une couche supplémentaire de vérification, mais elle ne passe pas au-dessus des limites techniques du logiciel et garde les mêmes faiblesses. Cependant, avec une bonne optimisation du rendu, l’ELA peut se révéler efficace sur des documents plus complexes.

Les tests montrent une chose simple : l’efficacité dépend fortement du type de document et du niveau d’intégration de la modification.
Modification de montant : détectable sur un scan (présence de bruit), indétectable sur un document numérique natif propre.
Copier-coller de signature : détecté lorsque la différence de texture est conservée, mais fortement atténué après recompression homogène.
Effacement / Inpainting : très visible avec un outil basique, beaucoup plus difficile à repérer après une retouche avancée.
ELA (analyse de compression) : apporte une couche supplémentaire, mais reste sensible au niveau de compression initial et peut produire un signal difficile à interpréter.
En clair, les méthodes visuelles fonctionnent bien sur des modifications simples ou mal intégrées, mais perdent en efficacité face à des modifications homogénéisées.
Si l’on reste uniquement sur l’analyse d’images :
OpenCV reste néanmoins l’une des solutions les plus flexibles pour intégrer ce type d’analyse dans un pipeline automatisé.
Ce qu’il y a à retenir de cet article, c’est qu’OpenCV fonctionne plutôt bien sur son champ d’action avec de bons paramètres. Les changements visuels grossiers ou certains plus avancés peuvent être repérés et ainsi éviter quelques fraudes.
Plus largement, la fraude documentaire est un problème que l’on ne résout pas avec une seule couche de solution. Chaque document doit être croisé par plusieurs méthodes de détection de fraude : visuelles, sémantiques, analyse des métadonnées). C’est cet ensemble de couches de vérification qui vous donnera une vraie idée de l’authenticité d’un document.
Alors oui, OpenCV est une bonne solution en tant que brique dans un ensemble. Pour les autres couches de vérification, il existe des solutions anti-fraude documentaire dédiées qui automatisent la chaîne complète.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


