<script type="application/ld+json"> { "@context": "https://schema.org", "@type": "FAQPage", "mainEntity": [ { "@type": "Question", "name": "Qu’est-ce que la fraude documentaire exactement ?", "acceptedAnswer": { "@type": "Answer", "text": "La fraude documentaire correspond à toute falsification ou fabrication de documents (relevés bancaires, fiches de paie, avis d’imposition, pièces d’identité, etc.) destinée à obtenir un avantage indu, par exemple un crédit, une location ou une prestation." } }, { "@type": "Question", "name": "Quels sont les documents les plus souvent falsifiés ?", "acceptedAnswer": { "@type": "Answer", "text": "Les documents le plus souvent falsifiés sont les relevés bancaires, fiches de paie, avis d’imposition, pièces d’identité, justificatifs de domicile et factures, car ils servent de base aux décisions financières et réglementaires." } }, { "@type": "Question", "name": "Les packs Python de détection visuelle suffisent-ils pour lutter contre la fraude documentaire ?", "acceptedAnswer": { "@type": "Answer", "text": "Non. Les packs Python de détection visuelle sont utiles pour repérer des manipulations d’images, mais ils n’évaluent ni le contenu ni la cohérence métier des documents. Ils doivent être combinés avec d’autres méthodes de contrôle." } }, { "@type": "Question", "name": "A quoi sert l’analyse des métadonnées dans la détection de fraude ?", "acceptedAnswer": { "@type": "Answer", "text": "L’analyse des métadonnées permet de détecter des incohérences dans l’histoire technique du fichier, comme des dates de modification suspectes ou l’utilisation de logiciels inattendus. C’est un complément efficace à la détection visuelle et aux tests d’incohérences." } }, { "@type": "Question", "name": "En quoi Koncile va plus loin qu’un simple OCR ?", "acceptedAnswer": { "@type": "Answer", "text": "Koncile combine OCR spécialisé, structuration des données, règles métiers et IA pour détecter les incohérences entre documents d’un même dossier. La solution permet d’identifier les suspicions de fraude documentaire au-delà de la simple lecture des documents." } } ] } </script>
Menu
Détection de fraude documentaire : 3 méthodes pour repérer les faux documents
La fraude documentaire explose. Voici trois méthodes concrètes pour détecter les faux documents, de la plus simple à la plus avancée.
Trois approches complémentaires pour détecter la fraude documentaire et sécuriser vos décisions à partir de documents.
Qu’est-ce que la détection de fraude ?
La fraude documentaire consiste à falsifier des pièces justificatives pour obtenir un avantage qui ne devrait pas être accordé : crédit, location, prestation sociale, contrat, emploi, etc. Détecter la fraude documentaire, c’est vérifier que les documents fournis sont authentiques et cohérents avant de déclencher une décision métier.
Dans la pratique, cela concerne surtout des documents financiers et d’identité : relevés bancaires, fiches de paie, avis d’imposition, pièces d’identité, justificatifs de domicile, factures, déclarations fiscales… Si ces documents sont manipulés, toute la chaîne de décision est faussée : scoring de crédit, validation de dossier locatif, KYC, onboarding client, lutte anti-fraude.
Historiquement, la détection de fraude documentaire reposait sur la relecture humaine : un analyste compare plusieurs documents, vérifie les montants, les dates, les logos, les signatures, les tampons. Cette approche reste utile, mais devient ingérable dès que les volumes augmentent.
On voit aujourd’hui se structurer trois grandes familles de méthodes :
la détection visuelle, basée sur l’analyse de l’image du document ;
l’analyse des métadonnées des fichiers ;
la recherche d’incohérences métiers, propulsée par l’IA dans des logiciels comme Koncile.
L’objectif n’est pas de choisir “la meilleure” méthode, mais de comprendre ce que chacune couvre, ses limites et comment les combiner dans un workflow industriel.
Falsification de documents : le cœur de la fraude documentaire
La falsification de documents est la forme la plus courante de fraude documentaire. Elle consiste à modifier, recomposer ou fabriquer des pièces pour qu’elles paraissent authentiques tout en racontant une histoire fausse. Cela peut aller de retouches grossières à des manipulations très subtiles, invisibles à l’œil nu.
Pour y répondre efficacement, il n’existe pas une seule technique miracle, mais plusieurs approches complémentaires, chacune ciblant un type de falsification différent.
💡Astuce
Ne cherchez pas à tout détecter avec un seul outil. Combinez détection visuelle, analyse de métadonnées et tests de cohérence pour réduire la fraude documentaire sans bloquer tous les dossiers.
Méthode 1 : les packs Python pour la détection visuelle
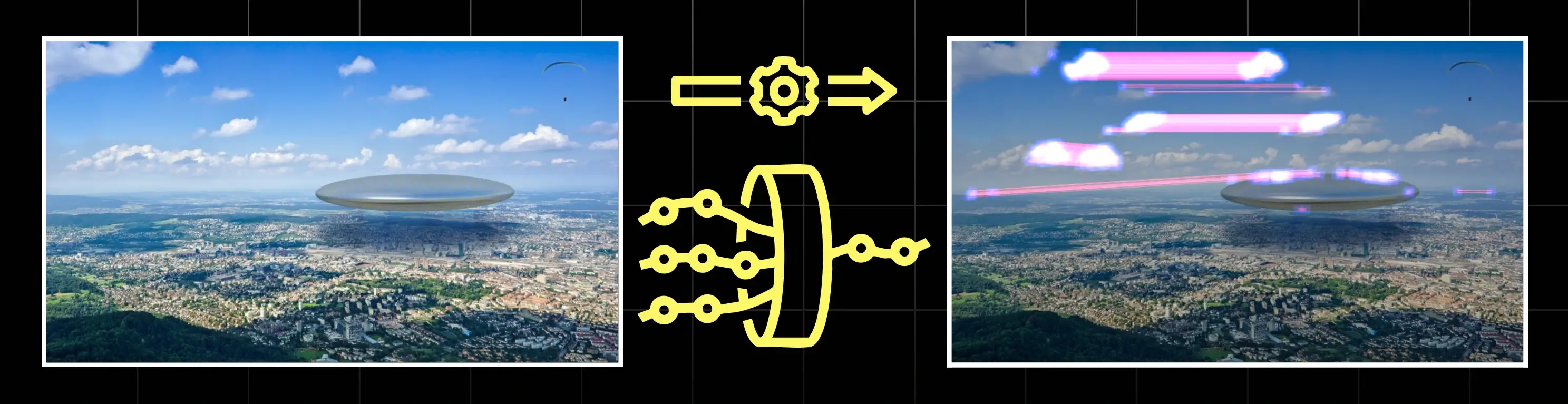
La première approche consiste à traiter le document comme une image, sans se soucier encore du contenu métier. On cherche à savoir si l’image a été retouchée : zones clonées, collages, retouches locales, artefacts de compression.
Cette méthode repose sur des librairies Python d’analyse d’images (forensique). Elles sont intéressantes pour repérer des falsifications grossières ou des bricolages rapides : logo recollé, tampon ajouté, signature déplacée, champs modifiés à la va-vite.
En revanche, elles restent limitées dès que la qualité du fichier est mauvaise (photo floue, document de travers, scan compressé) ou lorsque la falsification est soignée à partir d’un modèle original.
Explication de la méthode
Dans cette approche, un document (carte d’identité, facture, avis d’imposition, bulletin de salaire) est considéré comme une simple image numérique. Les algorithmes vont notamment :
découper l’image en blocs pour repérer des zones qui se répètent (clone detection) ;
analyser le niveau de compression, le bruit et la texture pour identifier des zones retouchées ;
mettre en évidence des incohérences visuelles : contours anormaux, différences de grain, éléments ajoutés.
Quelques signaux typiques :
une photo de profil sur une carte d’identité dont le fond ou la découpe ne correspond pas au reste du document ;
un tampon ou une signature ajoutés après coup, avec une texture différente ;
un logo administratif copié depuis un autre document, avec une résolution ou une netteté qui ne colle pas.
On reste sur une logique de suspicion visuelle : l’outil ne sait pas si le montant ou l’identité sont crédibles, mais il peut dire “ce document a vraisemblablement été retouché”.
Exemple de clone detection
Les packs Python
Les packs Python de détection visuelle sont souvent utilisés comme briques R&D ou comme base de proof of concept. Ils montrent ce qu’il est possible de faire, mais ne sont pas des solutions prêtes à l’emploi pour des équipes opérationnelles.
Ils sont particulièrement adaptés pour :
explorer le potentiel de la détection visuelle sur un type de document donné ;
former les équipes fraude aux signaux visuels de falsification ;
construire une première couche de filtre avant des analyses plus avancées.
Pack Python DocAuth (Github)
DocAuth est un projet en Python de “document authentication” qui vise à détecter les falsifications sur des images, des signatures, des documents d’identité ou des certificats gouvernementaux.
À noter : le projet est assez basique et peu maintenu, mais il peut servir de point de départ ou de proof of concept.
Fonctionnalités typiques :
détection de zones modifiées sur des images de cartes d’identité, certificats, documents officiels ;
scripts d’exemple pour mettre en évidence des retouches sur certaines zones sensibles (photo, signature, tampon) ;
génération de cartes de chaleur ou de scores de suspicion par région de l’image ;
intégration possible dans des pipelines Python d’analyse d’images.
Pack Python PhotosHolmes
PhotosHolmes est une librairie Python pour la détection de forgeries d’images digitales. Elle n’est pas spécialisée “documents d’identité”, mais l’approche est réutilisable.
Utilité : certaines techniques d’analyse d’image (copie/move, altération de champs) peuvent être adaptées pour repérer des modifications sur des cartes d’identité, factures, avis d’impôts, etc.
Fonctionnalités typiques :
détection de zones copiées-collées à l’intérieur d’une même image ;
mise en évidence de retouches locales via des algorithmes dédiés ;
indicateurs visuels pour guider un analyste humain (zones surlignées, masques) ;
possibilité de combiner plusieurs algorithmes de forensique dans un seul pipeline.
Pack Python pyIFD
pyIFD (Python Image Forgery Detection toolkit) est un toolkit qui regroupe plusieurs techniques de détection de retouches d’images dans un contexte de forensique.
Utilité : il peut être utilisé pour des expérimentations rapides ou comme base d’intégration, mais il faut vérifier la maintenance actuelle et la compatibilité avec vos formats d’image/documents.
Fonctionnalités typiques :
implémentation de plusieurs algorithmes de détection de forgeries ;
support de différents formats d’images courants (JPEG, PNG, TIFF) ;
scripts de démonstration pour tester les algorithmes sur un jeu d’images ;
possibilité de produire des cartes de suspicion par zone.
Pack Python Forensically
Forensically est à l’origine un outil web gratuit pour l’analyse d’images (clone detection, error-level analysis, etc.), mais il est souvent intégré dans des workflows techniques ou utilisé comme référence.
Utilité : très pratique pour des vérifications manuelles ou semi-automatisées, moins adapté tel quel pour une intégration automatisée à grande échelle sans adaptation.
Fonctionnalités typiques :
détection de clones (zones dupliquées dans l’image) ;
analyse du niveau d’erreur (ELA) pour repérer des retouches locales ;
outils d’inspection visuelle pour des expertises ponctuelles ;
support de différents formats d’images utilisés pour les documents scannés.
Comparatifs des packs
En résumé, ces packs Python de détection visuelle permettent d’identifier des manipulations évidentes ou grossières sur des documents scannés ou photographiés. Ils constituent une bonne base pour l’expérimentation, mais ne suffisent pas à eux seuls pour sécuriser un flux de fraude documentaire à grande échelle.
Outil
Type
Cas d’usage
Points forts
Limites
DocAuth
Pack Python authentification de documents
Tests sur cartes d’identité, certificats ou documents officiels pour POC et démonstrations.
Simple à prendre en main, bonne base pour explorer la détection visuelle.
Projet peu maintenu, périmètre limité, pas prêt pour la production tel quel.
PhotosHolmes
Librairie Python forensique d’images
Analyse de copies internes et retouches locales sur des images de documents.
Algorithmes solides de clone detection, bon complément dans un pipeline visuel.
Non spécialisée “documents”, nécessite du tuning pour des cas métier précis.
pyIFD
Toolkit Python Image Forgery Detection
Expérimentations rapides sur la détection de retouches d’images scannées.
Plusieurs techniques regroupées dans un même toolkit, pratique pour comparer.
Outil ancien, maintenance et compatibilité à vérifier selon les formats.
Forensically
Outil web forensique d’images
Vérifications manuelles ou semi-auto sur CI, factures, avis d’imposition.
Interface très pédagogique, idéale pour l’analyse de cas sensibles.
Pas pensé pour une intégration massive automatisée sans gros travail d’adaptation.
Les avantages de la détection visuelle
Utile pour repérer des falsifications grossières sur des documents numériques standardisés.
Permet de mettre en évidence des manipulations invisibles à l’œil nu sur la compression et la texture.
Intéressant pour des POC ou des cas à faible volume où l’on peut combiner détection automatique et revue humaine.
Les limites de la détection visuelle
Très dépendante de la qualité de l’image (photos floues, scans de mauvaise résolution, documents de travers).
Ne dit rien sur la cohérence métier : un document “propre” visuellement peut contenir des informations totalement inventées.
Difficile à maintenir et à industrialiser sans une équipe technique dédiée.
Méthode 2 : l’analyse des métadonnées des fichiers par outils open source et packs Python
La deuxième méthode ne s’intéresse plus à l’apparence visuelle du document, mais à son “histoire technique”. Chaque fichier numérique (image, PDF, parfois document Office) emporte des métadonnées : dates de création et de modification, logiciel utilisé, type de périphérique, informations de prise de vue, etc.
L’analyse de ces métadonnées permet de détecter des comportements suspects, par exemple :
un avis d’imposition censé être téléchargé depuis un portail officiel, mais modifié avec un éditeur PDF grand public juste avant l’envoi ;
une carte d’identité supposément scannée en agence, mais créée avec une application de retouche photo ;
une série de documents d’un même dossier qui partagent exactement la même “signature technique”.
Cette méthode ne prouve pas la fraude documentaire à elle seule, mais elle fournit des signaux faibles précieux.
Explication de la méthode
L’idée est d’extraire les métadonnées des fichiers et de les comparer à ce qui est attendu dans votre process. On va notamment regarder :
la date de création du fichier ;
la date de dernière modification ;
le logiciel utilisé pour générer ou modifier le document ;
le type d’appareil (smartphone, scanner, appareil photo) ;
certains champs EXIF ou XMP ajoutés automatiquement.
Quelques exemples parlants :
un faux avis d’imposition créé en réalité à partir d’un PDF modifié trois jours avant la demande de crédit ;
une fiche de paie qui prétend provenir d’un logiciel de paie, mais dont les métadonnées révèlent un passage par un éditeur d’images ;
des documents qui devraient être homogènes (série d’avis d’imposition sur plusieurs années) mais qui présentent des métadonnées incohérentes.
L’analyse de metadata ne détecte pas le contenu frauduleux en lui-même, mais met en lumière des anomalies techniques incompatibles avec un scénario “normal”.
Avantages de l’analyse des métadonnées
Cette méthode est appréciée pour plusieurs raisons :
elle est rapide à mettre en œuvre et s’adapte bien au passage à l’échelle ;
elle reste efficace même lorsque les documents sont visuellement propres ;
elle permet de révéler des incohérences techniques invisibles à l’œil nu.
Limites de l’analyse des métadonnées
Comme toute approche technique, elle présente aussi des limites :
les métadonnées peuvent être absentes, incomplètes ou volontairement modifiées ;
des opérations légitimes comme l’OCR, la signature électronique ou la fusion de PDF peuvent modifier ces informations ;
aucune métadonnée ne constitue, à elle seule, une preuve de fraude.
Pourquoi cette méthode reste complémentaire
Utilisée seule, l’analyse des métadonnées fournit surtout des signaux faibles. Elle prend tout son sens lorsqu’elle est combinée à d’autres méthodes, notamment l’analyse des incohérences entre documents et l’intégration de règles métier dans une logique de scoring global.
Les solutions (open source et packs Python)
Cette méthode repose principalement sur des outils open source et des bibliothèques pouvant être intégrés dans des scripts ou des pipelines de traitement.
ExifTool (open source)
ExifTool est l’outil open source de référence pour extraire les métadonnées techniques des fichiers images (EXIF, XMP, IPTC, etc.) et, dans certains cas, de PDF.
Utilité pour la fraude documentaire :
récupérer les dates de création et de modification ;
identifier le logiciel ou le périphérique qui a généré le fichier ;
repérer des incohérences entre l’origine déclarée du document et ses métadonnées.
Fonctionnalités typiques :
support de nombreux formats d’images et de certains formats documents ;
extraction en ligne de commande ou via des scripts ;
possibilité de modifier ou de supprimer certaines métadonnées (utile aussi pour la protection de la vie privée) ;
génération de rapports structurés intégrables dans un pipeline.
Exiv2 (open source)
Exiv2 est une bibliothèque C++ accompagnée d’un outil en ligne de commande, très utilisée pour lire et modifier les métadonnées d’images.
Utilité pour la fraude documentaire :
alternative à ExifTool pour les environnements C++ ou les projets qui utilisent déjà Exiv2 ;
brique d’intégration pour les applications qui doivent inspecter ou manipuler les métadonnées à la volée.
Fonctionnalités typiques :
lecture et écriture des métadonnées EXIF, IPTC, XMP ;
support de nombreux formats d’images (JPEG, PNG, TIFF, etc.) ;
intégration possible dans des applications de traitement d’images existantes ;
outil CLI pour des traitements batch simples.
hachoir-metadata (pack Python)
hachoir-metadata fait partie de l’écosystème Hachoir, une librairie Python qui permet de parser des fichiers au niveau binaire et d’en extraire des métadonnées.
Utilité pour la fraude documentaire :
analyser automatiquement des lots de fichiers dans un environnement Python ;
remonter des informations techniques (structure, entêtes, champs spécifiques) à intégrer dans un score de fraude documentaire ;
combiner métadonnées techniques et autres signaux (résultats OCR, détection visuelle) dans un même pipeline.
Fonctionnalités typiques :
extraction de métadonnées sur de nombreux formats (images, vidéos, archives, etc.) ;
API Python pour intégrer les analyses dans des scripts ou des services ;
possibilité de créer des règles de détection spécifiques à votre contexte.
Comparatifs des solutions
Les outils d’analyse de métadonnées offrent une couche complémentaire à la détection visuelle. Ils ne regardent pas le contenu métier du document, mais son cycle de vie technique.
Outil
Intégration
Ce qu’il analyse
Points forts
Limites
ExifTool
CLI + scripts
Métadonnées EXIF, XMP, IPTC et champs techniques sur images et certains PDF.
Référence historique, très complet, idéal pour des traitements batch.
Interface surtout en ligne de commande, moins accessible aux profils non techniques.
Exiv2
Librairie C++ + CLI
Métadonnées EXIF, IPTC, XMP sur la plupart des formats d’images.
Bien intégré dans l’écosystème open source, bon choix pour apps C++.
Focalisé images, moins polyvalent qu’ExifTool, demande des compétences C++.
hachoir-metadata
Librairie Python
Métadonnées techniques de nombreux fichiers via parsing binaire.
Facile à intégrer dans des pipelines Python, adapté à l’analyse de gros volumes.
Nécessite de définir ses propres règles de détection pour la fraude documentaire.
Les avantages de l’analyse des métadonnées
Permet de repérer des incohérences temporelles ou logicielles difficilement visibles à l’œil nu.
S’automatise relativement facilement sur de grands volumes de fichiers.
Aide à identifier des schémas de fraude récurrents (mêmes outils, mêmes patterns de modification).
Les limites de l’analyse des métadonnées
Les métadonnées n’analysent pas le contenu : des montants, identités ou adresses falsifiés mais “proprement” régénérés peuvent passer.
Certains champs peuvent être absents, nettoyés ou manipulés par des fraudeurs avancés.
Cette méthode doit être combinée à d’autres (visuelle, cohérence métier) pour être vraiment efficace.
Méthode 3 : tests des incohérences par logiciels comme Koncile (AI powered)
La troisième méthode est la plus proche de la réalité métier : elle consiste à vérifier si les informations contenues dans les documents “tiennent la route” lorsqu’on les croise entre elles.
Ici, on ne se limite plus à l’image ni aux métadonnées. On extrait les données, on les structure, puis on applique des règles métiers et de l’IA pour repérer des incohérences. C’est exactement ce que font des logiciels comme Koncile, Inscribe ou Resistant AI.
Cette approche est particulièrement adaptée aux documents financiers et administratifs standardisés :
La détection de fraude documentaire par tests d’incohérences suit généralement plusieurs étapes :
Extraction OCR Extraction des champs clés : montants, dates, IBAN, identifiants fiscaux, employeur, adresse, soldes, périodes, etc.
Structuration des données Normalisation des formats de date, des montants, des libellés, regroupement des lignes en catégories (revenus, charges, soldes, transactions récurrentes…).
Règles métiers de cohérence Application de contrôles de cohérence, par exemple :
brut / net / charges sur une fiche de paie ;
cohérence entre revenus déclarés et flux visibles sur les relevés ;
alignement entre avis d’imposition et déclarations fiscales ;
continuité des périodes d’emploi ou de revenus.
IA et détection d’anomalies Utilisation de modèles statistiques et de modèles IA pour repérer :
des profils de revenus impossibles pour un type de poste ou de secteur ;
des combinaisons de documents rarement observées sur des dossiers sains ;
des patterns caractéristiques de fraude documentaire.
On ne demande plus “ce document a-t-il été retouché ?” mais “l’histoire que raconte ce dossier est-elle cohérente ?”.
Les différentes solutions (AI powered)
Plusieurs solutions du marché adoptent cette approche “cohérence + IA” pour la fraude documentaire.
Koncile (AI powered)
Koncile se concentre sur l’automatisation de la lecture et du contrôle de documents financiers et administratifs dans des parcours de crédit, de location ou d’onboarding.
Fonctionnalités clés :
extraction spécialisée dans l'OCR facture, relevés bancaires, fiches de paie, avis d’imposition, factures, tax returns, etc. ;
structuration des données extraites dans des schémas adaptés (dossier crédit, dossier locatif, dossier KYC) ;
mise en place de règles métiers de cohérence (revenus, charges, soldes, périodes, identités) ;
analyse par IA pour repérer des comportements atypiques ou des incohérences subtiles entre documents ;
exposition via API pour intégrer la détection de fraude documentaire directement dans vos workflows.
Inscribe (AI powered)
Inscribe est une solution orientée banques, fintechs et prêteurs. Elle se focalise sur la détection de faux documents et de dossiers frauduleux à partir de pièces financières et d’identité.
Fonctionnalités clés :
ingestion de relevés bancaires, pay stubs, tax documents, ID, etc. ;
combinaison de forensique documentaire, métadonnées et analyse de données ;
détection de “hidden inconsistencies” dans les champs : dates, montants, adresses, structures de documents ;
scoring de risque de fraude et intégration dans les systèmes de décision.
Resistant AI (AI powered)
Resistant AI propose une approche de “document forensics” multi-couches pour les acteurs financiers qui traitent de gros volumes de documents.
Fonctionnalités clés :
analyse de bank statements, payslips, utility bills, tax forms et autres justificatifs ;
utilisation de centaines de signaux (structure de fichier, contenu, patterns de manipulation) pour évaluer le risque ;
calcul d’un profil de risque par document et par dossier ;
intégration dans les chaînes KYC, underwriting et monitoring.
Comparatifs des solutions
Les solutions AI powered de détection d’incohérences se situent à un niveau d’abstraction plus élevé que les packs Python ou les outils de métadonnées. Elles cherchent à reproduire le raisonnement d’un analyste, mais à grande échelle.
Solution
Positionnement
Types de documents
Type d’analyse
Idéal pour
Koncile
OCR + IA pour documents financiers et administratifs.
Relevés bancaires, fiches de paie, avis d’impôt, factures, tax returns.
Extraction structurée, règles métier et tests d’incohérences entre champs et documents.
Crédit, gestion locative, KYC/Onboarding qui veulent automatiser tout en ciblant la fraude.
Inscribe
Fraude documentaire pour banques / fintechs.
Bank statements, pay stubs, tax docs, pièces d’identité.
Forensique, métadonnées et data checks pour trouver les “hidden inconsistencies”.
Prêteurs et fintechs qui veulent réduire la fraude sans dégrader l’expérience client.
Resistant AI
Plateforme de “document forensics” multi-couches.
Bank statements, payslips, utility bills, tax forms…
Profil de risque basé sur structure du fichier, contenu et patterns de manipulation.
Banques, assureurs, BNPL, lending à très gros volumes de documents.
Les avantages de la recherche d’incohérences
Méthode la plus proche du besoin réel : vérifier qu’un dossier est cohérent et crédible.
Permet de détecter des fraudes invisibles à l’œil nu ou dans les métadonnées (montants légèrement ajustés, combinaisons de documents improbables, trajectoires de revenus incohérentes).
S’intègre directement dans les workflows via API, ce qui permet de prioriser les dossiers à risque et d’automatiser les cas simples.
Les limites de la recherche d’incohérences
Nécessite un travail initial de modélisation des documents et des règles métiers.
Demande une certaine maturité data et process pour tirer tout le potentiel de la solution.
Ne remplace pas complètement la revue humaine sur les dossiers à très fort enjeu, mais permet de la concentrer sur les cas réellement suspects.
À noter
Aucune de ces méthodes ne suffit isolément pour éradiquer la fraude documentaire. En revanche, combinées de manière intelligente, elles permettent de réduire fortement le risque tout en préservant l’expérience utilisateur.
Une stratégie réaliste ressemble souvent à ceci :
packs Python et forensique visuelle pour filtrer les manipulations grossières ;
analyse de métadonnées pour identifier des fichiers techniquement suspects ;
logiciels AI powered comme Koncile pour vérifier la cohérence métier de l’ensemble du dossier.
L’enjeu n’est pas de remplacer totalement les équipes humaines, mais de leur permettre de se concentrer sur les dossiers qui en valent vraiment la peine. Pour aller plus loin dans le choix d’un outil, consultez notre comparatif des solutions de détection de fraude documentaire.
FAQ
Qu’est-ce que la fraude documentaire exactement ?
La fraude documentaire correspond à toute falsification ou fabrication de documents (relevés bancaires, fiches de paie, avis d’imposition, pièces d’identité, etc.) destinée à obtenir un avantage indu (crédit, location, contrat, prestation...).
Quels sont les documents les plus souvent falsifiés ?
Les documents les plus ciblés sont les relevés bancaires, fiches de paie, avis d’imposition, pièces d’identité, justificatifs de domicile et factures, car ils servent de base aux décisions financières et réglementaires.
Les packs Python de détection visuelle suffisent-ils contre la fraude ?
Non. Ils sont utiles pour repérer des manipulations d’images, mais ils n’évaluent ni le contenu ni la cohérence métier. Ils doivent être combinés à d’autres méthodes comme l’analyse des métadonnées et les tests d’incohérences.
À quoi sert l’analyse des métadonnées pour la fraude documentaire ?
L’analyse des métadonnées permet de détecter des incohérences dans l’“histoire technique” du fichier : dates de création et de modification, logiciels utilisés, type de device. Cela aide à identifier des documents suspects même s’ils paraissent visuellement propres.
En quoi Koncile va plus loin qu’un simple OCR ?
Koncile ne fait pas qu’extraire du texte : la solution structure les données des documents, applique des règles métiers et utilise l’IA pour détecter des incohérences entre champs et entre documents d’un même dossier, afin de mettre en avant les suspicions de fraude documentaire.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.



.webp)










.png)


