


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
June 19, 2026
5 minutes
Jusqu’à récemment, connecter un moteur OCR à un assistant IA impliquait d’écrire du code spécifique, de gérer manuellement les appels API et de construire toute la couche intermédiaire entre votre modèle de langage et votre pipeline de traitement documentaire. Avec le Model Context Protocol (MCP), toute cette couche disparaît. Chez Koncile, nous avons développé un serveur MCP OCR permettant à Claude, Cursor ou tout autre agent IA compatible d’extraire, lire et gérer des documents sans écrire la moindre ligne de code d’intégration.
Le serveur MCP OCR de Koncile connecte les agents IA à l’extraction intelligente de documents. 24 outils, données structurées, mise en place en 15 minutes. Essayez gratuitement ou en self-host.

MCP (Model Context Protocol) est un standard ouvert introduit par Anthropic qui définit comment les assistants IA communiquent avec des outils externes. On peut le voir comme une prise universelle : au lieu que chaque outil nécessite son propre connecteur spécifique, MCP fournit un protocole unique que n’importe quel client IA peut utiliser.
Pour l’OCR en particulier, c’est un changement majeur. L’extraction de documents a toujours été dans une zone intermédiaire un peu étrange. C’est trop complexe pour être un simple appel API (on upload, on attend, on poll, on parse un output structuré), mais c’est aussi trop courant pour justifier de construire une intégration complète à chaque besoin.
MCP transforme tout cela en quelque chose que l’assistant IA comprend déjà nativement.
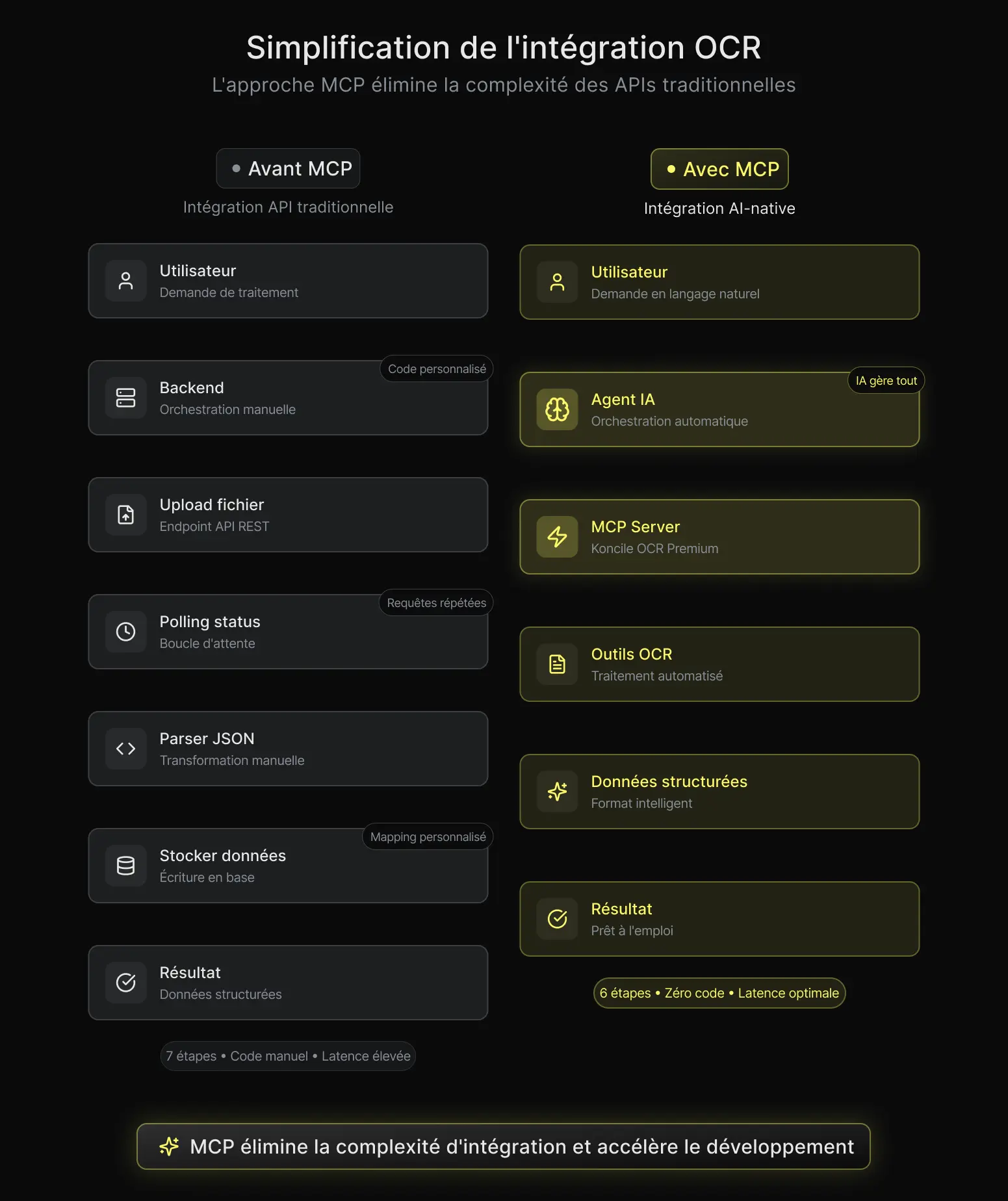
Lorsque vous connectez une API OCR de manière traditionnelle, vous êtes l’orchestrateur. Vous écrivez le code qui upload le fichier. Vous écrivez le code qui vérifie l’état de traitement. Vous écrivez le code qui parse la réponse JSON et la mappe à votre modèle de données, ce qui implique de gérer une logique complexe d’analyse de documents. Vous gérez les erreurs, les retries, le rafraîchissement de l’authentification.
Chaque intégration est spécifique, et chaque intégration spécifique devient une surface de maintenance.
Nous le savons bien chez Koncile puisque nous avons construit cette API nous-mêmes. Nous avons vu des équipes passer plusieurs jours, parfois des semaines, à mettre en place ce qui devrait être un simple workflow d’extraction de documents.
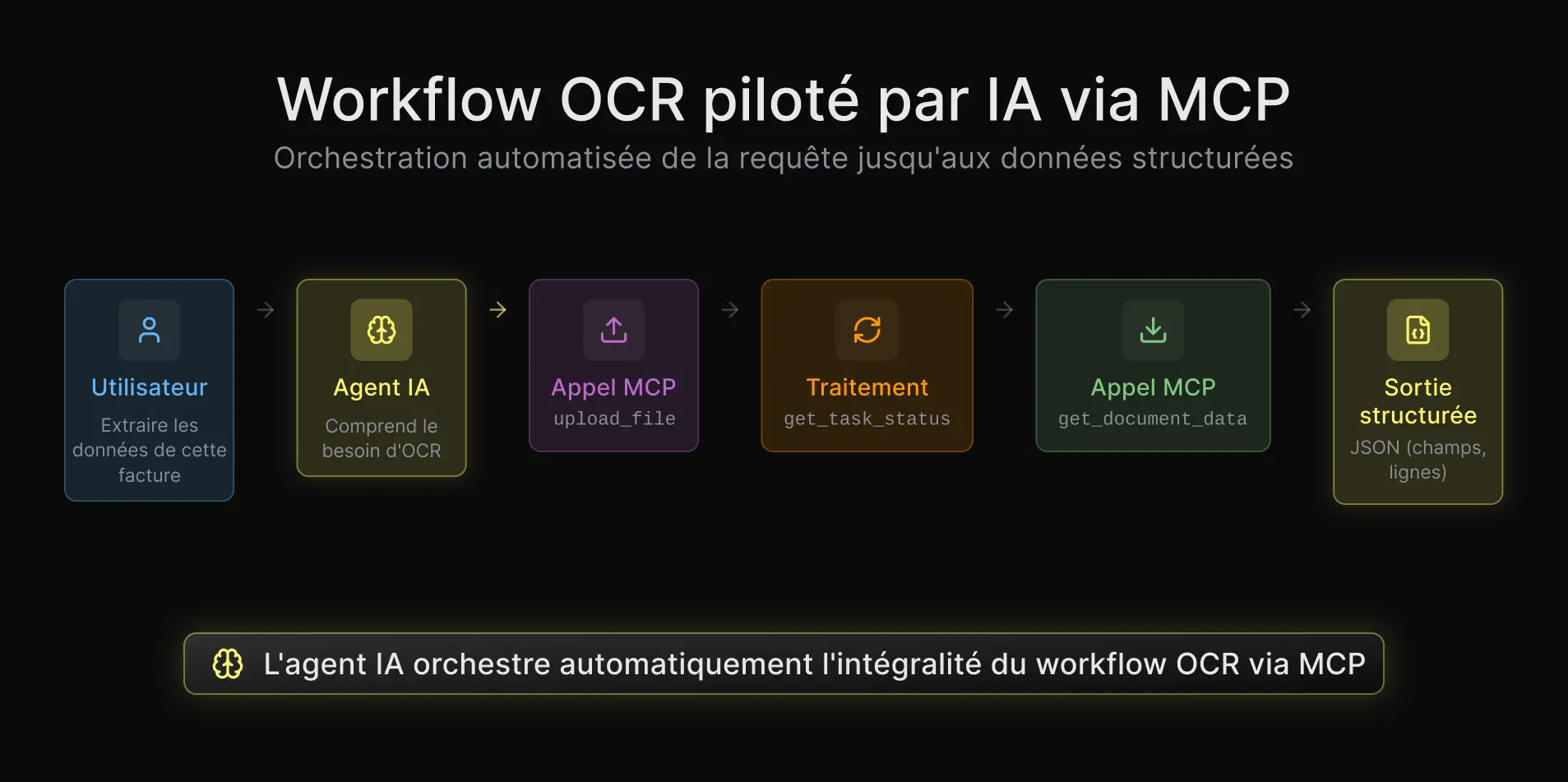
Lorsque vous exposez les mêmes capacités OCR via MCP, l’assistant IA prend en charge l’orchestration. Il sait appeler upload_file. Il sait vérifier get_task_status. Il sait récupérer les données extraites avec get_document_data.
Tout cela est décrit dans les définitions d’outils MCP, et l’assistant gère lui-même le workflow multi-étapes.
Du point de vue du développeur, il n’y a rien à écrire. Vous configurez le serveur MCP une seule fois, et l’assistant IA s’occupe du reste.
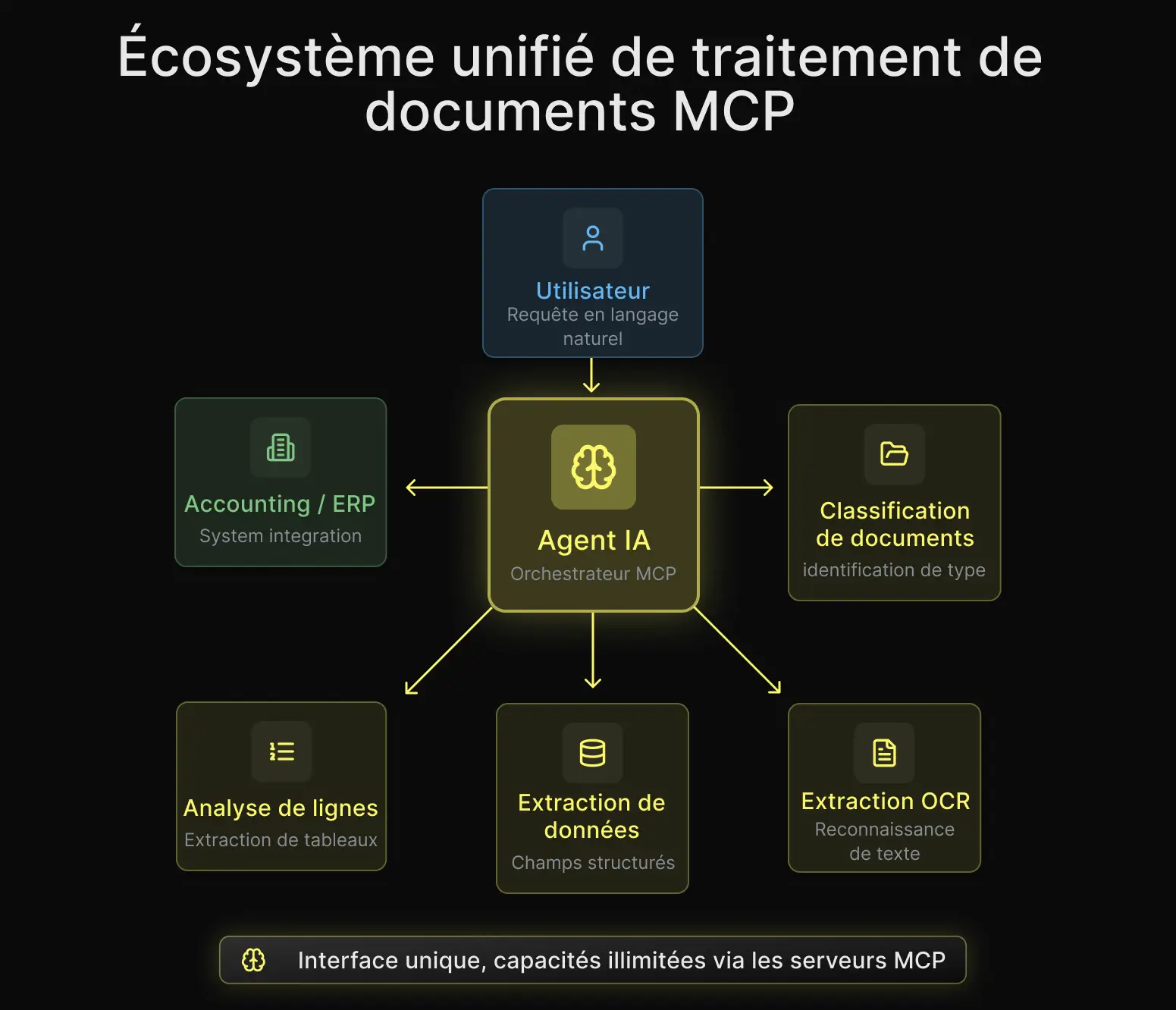
La plupart des serveurs MCP OCR que vous trouverez sur GitHub sont de simples wrappers autour d’un modèle OCR open source. Ils font une seule chose : prendre une image et retourner du texte. C’est utile pour de la reconnaissance de texte basique, mais c’est loin de ce dont vous avez besoin pour un traitement documentaire en production.
Le serveur MCP de Koncile expose 24 outils qui couvrent l’ensemble du cycle de vie du document. Vous pouvez uploader des fichiers et déclencher l’extraction. Vous pouvez vérifier le statut des tâches et récupérer des données structurées, à la fois les champs principaux et les lignes détaillées. Vous pouvez gérer des dossiers, des templates, des champs et des instructions d’extraction. Vous pouvez télécharger les documents originaux et supprimer ceux qui ont été traités.
Ce n’est pas un simple wrapper OCR. C’est une plateforme complète de document intelligence accessible en langage naturel.

L’un de nos objectifs dès le départ a été la flexibilité de déploiement. Vous pouvez vous connecter à notre serveur MCP hébergé via mcp.koncile.ai avec une seule commande et commencer à extraire des documents en moins d’une minute. Ou, si vous devez garder toutes les données sur votre infrastructure, vous pouvez auto-héberger le serveur via pip install ou Docker.
C’est quelque chose que la plupart des projets MCP OCR open source ne proposent pas. Ils nécessitent le téléchargement local des modèles, la configuration GPU et la gestion des dépendances. Avec Koncile, la complexité est gérée de notre côté (ou du vôtre si vous préférez), et la couche MCP reste légère et rapide.
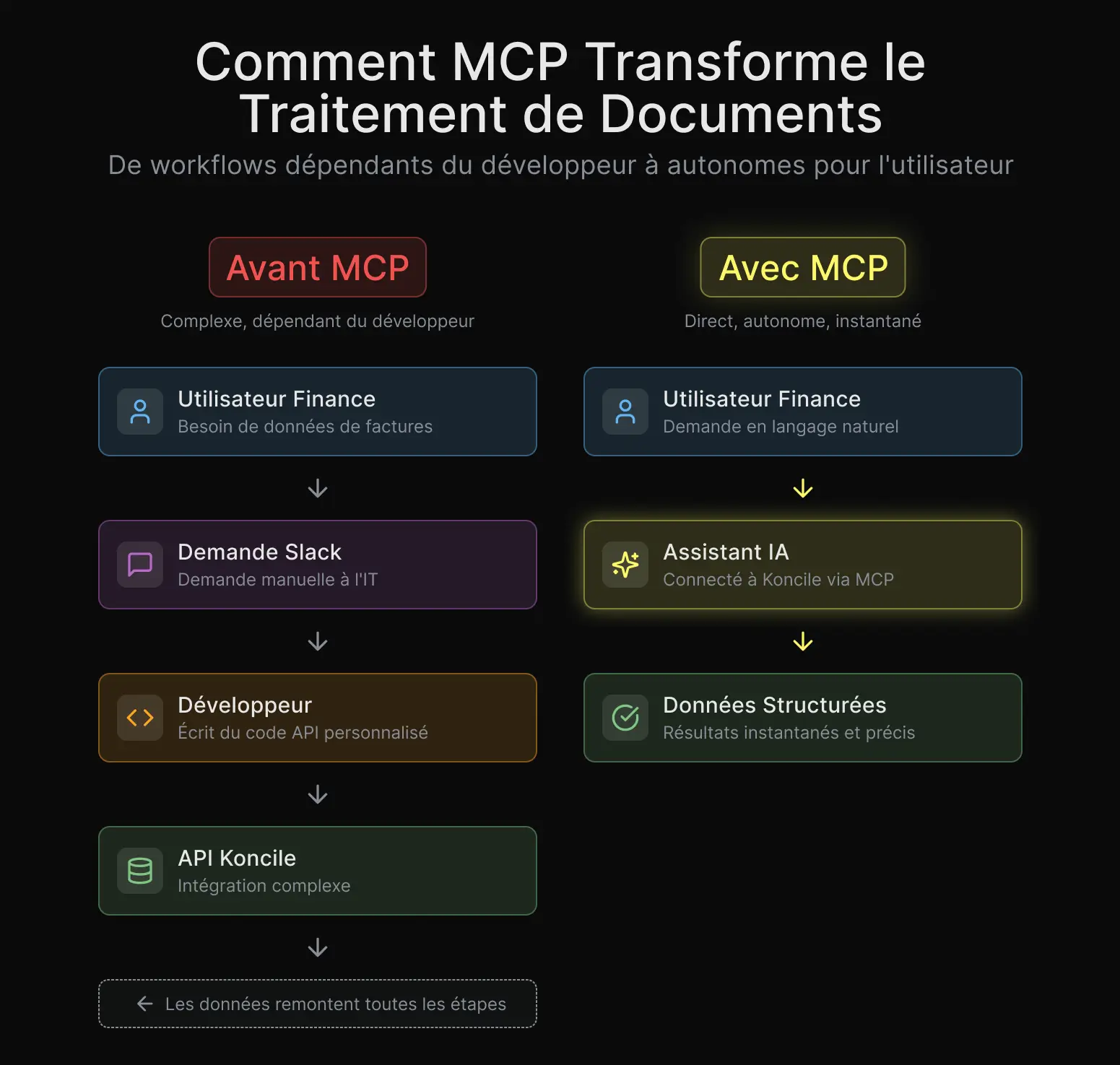
Si vous développez un agent qui doit traiter des factures, des reçus, des contrats ou tout document structuré, MCP vous permet d’ajouter cette capacité en quelques minutes au lieu de plusieurs jours. Aucun SDK à apprendre, aucun boilerplate à écrire. Vous décrivez ce que vous voulez en langage naturel, et l’assistant utilise les outils de Koncile pour le faire.
Chez Koncile, nous avons mesuré la différence en interne. Une intégration API classique pour l’extraction de documents prenait généralement entre 3 et 5 jours pour nos partenaires, entre la lecture de la documentation, la gestion de l’authentification, l’écriture du flow upload/poll/parse et les tests des cas limites.
Avec MCP, cette même intégration prend environ 15 minutes. Ce n’est pas une exagération. La configuration remplace le code.
C’est là que cela devient particulièrement intéressant. Avec MCP, les non-développeurs peuvent aussi traiter des documents. Un membre d’une équipe finance utilisant Claude Desktop peut simplement dire : "extract all the line items from this invoice" et obtenir des données structurées, sans connaître les APIs, l’authentification ou le parsing JSON.
Nous avons vu ce cas d’usage se développer très rapidement chez Koncile. Des équipes qui dépendaient auparavant des développeurs pour configurer des workflows d’extraction peuvent désormais le faire elles-mêmes, directement depuis leur assistant IA.
Comme le serveur MCP peut être auto-hébergé, les organisations ayant des contraintes strictes de résidence des données peuvent tout exécuter sur leur propre infrastructure. Les documents ne quittent jamais votre environnement, et le protocole MCP n’introduit pas d’exposition supplémentaire par rapport à une API classique.
Si vous utilisez Claude Code, l’installation se fait en une seule ligne :
claude mcp add --transport http koncile https://mcp.koncile.ai/mcp --header "Authorization: Bearer YOUR_API_KEY"
C’est tout. Claude a maintenant accès aux 24 outils de Koncile. Vous pouvez commencer à uploader et extraire des documents immédiatement.
Pour les autres clients compatibles MCP, il suffit d’ajouter un petit bloc JSON dans votre fichier de configuration. L’URL du serveur et votre clé API sont les seuls éléments nécessaires.
Nous maintenons des exemples de configuration à jour pour Claude Desktop, Cursor, Windsurf et Cline sur notre dépôt GitHub : https://github.com/Koncile/koncile-mcp
C’est un changement de paradigme qui nous a pris du temps à intégrer. Une API est conçue pour être utilisée par un développeur de manière programmatique. Le développeur lit la documentation, comprend les endpoints et écrit du code.
Un serveur MCP est conçu pour être utilisé par un agent IA de manière autonome. L’agent lit la description des outils, comprend les paramètres et orchestre le workflow lui-même.
La différence ne se limite pas à l’ergonomie. Elle change fondamentalement qui peut utiliser l’extraction de documents et à quelle vitesse.
Lorsque la barrière d’entrée passe de "écrire une intégration" à "décrire ce que vous voulez", l’audience s’élargit considérablement.
Avec une intégration API classique, chaque changement côté serveur (nouveaux champs, nouveaux endpoints, nouveaux formats de réponse) peut casser votre code. Vous devez mettre à jour votre client, tester et redéployer.
Avec MCP, les définitions d’outils sont dynamiques. Lorsqu’une nouvelle capacité est ajoutée chez Koncile, elle apparaît automatiquement dans le serveur MCP. L’assistant IA la découvre tout seul.
Il n’y a pas de code client à maintenir, car il n’y en a jamais eu.
Nous avons étudié les solutions existantes dans l’écosystème MCP OCR. Des projets comme RapidOCR MCP, Mistral OCR MCP ou PaddleOCR MCP sont très efficaces pour la reconnaissance de texte basique à partir d’images. Ils fonctionnent en local, sont gratuits et répondent à un vrai besoin.
Mais ils résolvent un problème différent. Ils prennent une image ou un scan et renvoient du texte brut.
Koncile, lui, extrait des données métier structurées : noms de fournisseurs, numéros de facture, montants, taux de TVA, lignes détaillées avec descriptions et quantités. C’'st de l'Intelligent document processing, pas seulement de la reconnaissance optique de caractères.
Si votre besoin est de lire du texte dans une image, un serveur MCP OCR open source fera parfaitement l’affaire. Si votre besoin est d’extraire toutes les données d’un ensemble de factures avec un output structuré et validé, alors le serveur MCP de Koncile est conçu pour cela.
MCP en est encore à ses débuts. L’écosystème évolue rapidement, et nous pensons que le traitement documentaire deviendra l’un des cas d’usage les plus répandus, aux côtés de la recherche de code, de l’accès aux bases de données et des outils de communication.
Chez Koncile, nous travaillons déjà sur de nouvelles capacités pour notre serveur MCP : traitement batch pour de gros volumes de documents, notifications webhook en temps réel lorsque l’extraction est terminée, et intégration plus poussée avec les logiciels comptables via des appels MCP chaînés.
La vision est simple : n’importe quel assistant IA, n’importe quel document, des données structurées en quelques secondes. Sans code.
Si vous voulez essayer, rendez-vous sur notre Home page pour obtenir votre clé API, et consultez la documentation complète et le code source sur GitHub : https://github.com/Koncile/koncile-mcp
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


