


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion
.webp)
Letzte Aktualisierung:
June 20, 2026
5 Minuten
Nicht alle Open-Source OCR Lösungen bieten eine sofort nutzbare API. Hier ein Praxistest, um die Unterschiede zu verstehen.
Praxisvergleich von 5 Open-Source OCR APIs: Integration, JSON-Output und Implementierungsaufwand.

Es gibt eine Vielzahl von OCR-Lösungen auf dem Markt. Doch sobald es um die Integration in Geschäftsprozesse geht, stehen zwei Themen im Mittelpunkt: API-Verfügbarkeit und Kosten. Eine Frage drängt sich auf: Wie sieht es bei Open-Source Lösungen aus, und wie schwierig ist deren Integration?
Ich habe daher eine Rangliste der fünf besten Open-Source OCR Lösungen erstellt, die über eine API nutzbar sind. Außerdem möchte ich betonen, dass ich kein Entwickler bin. Die meisten hier vorgestellten Lösungen sind relativ einfach zu integrieren und auch für Einsteiger verständlich.
Die große Mehrheit der heutigen SaaS-OCR Lösungen ist nicht Open Source, stellt aber OCR APIs bereit. Wenn man jedoch nach Open-Source OCR APIs sucht, stößt man schnell auf ein Problem. Nicht alle Open-Source OCR Engines bieten eine sofort einsatzbereite API. Häufig muss man diese selbst erstellen.
Bevor wir beginnen, ist es wichtig zu verstehen, dass jede Lösung unterschiedlich integriert werden kann und unterschiedliche Nutzungsmodelle sowie Open-Source Verfügbarkeiten aufweist. Deshalb existieren mehrere Kategorien. Wenn Open-Source OCR Projekte vollständig einsatzbereite APIs ohne Einnahmen aus der Nutzung anbieten würden, wäre es unmöglich, Hosting und Wartung zu finanzieren. Hier liegt der Vorteil von SaaS-Anbietern. Der Service ist kostenpflichtig, ebenso der API-Zugang, dafür sind die Lösungen stabil, schnell, sicher und häufig leistungsfähiger. Es gibt auch einen Mittelweg: Open-Source OCR Engines, deren APIs von SaaS-Anbietern gehostet werden.
Heute stelle ich drei Kategorien vor:
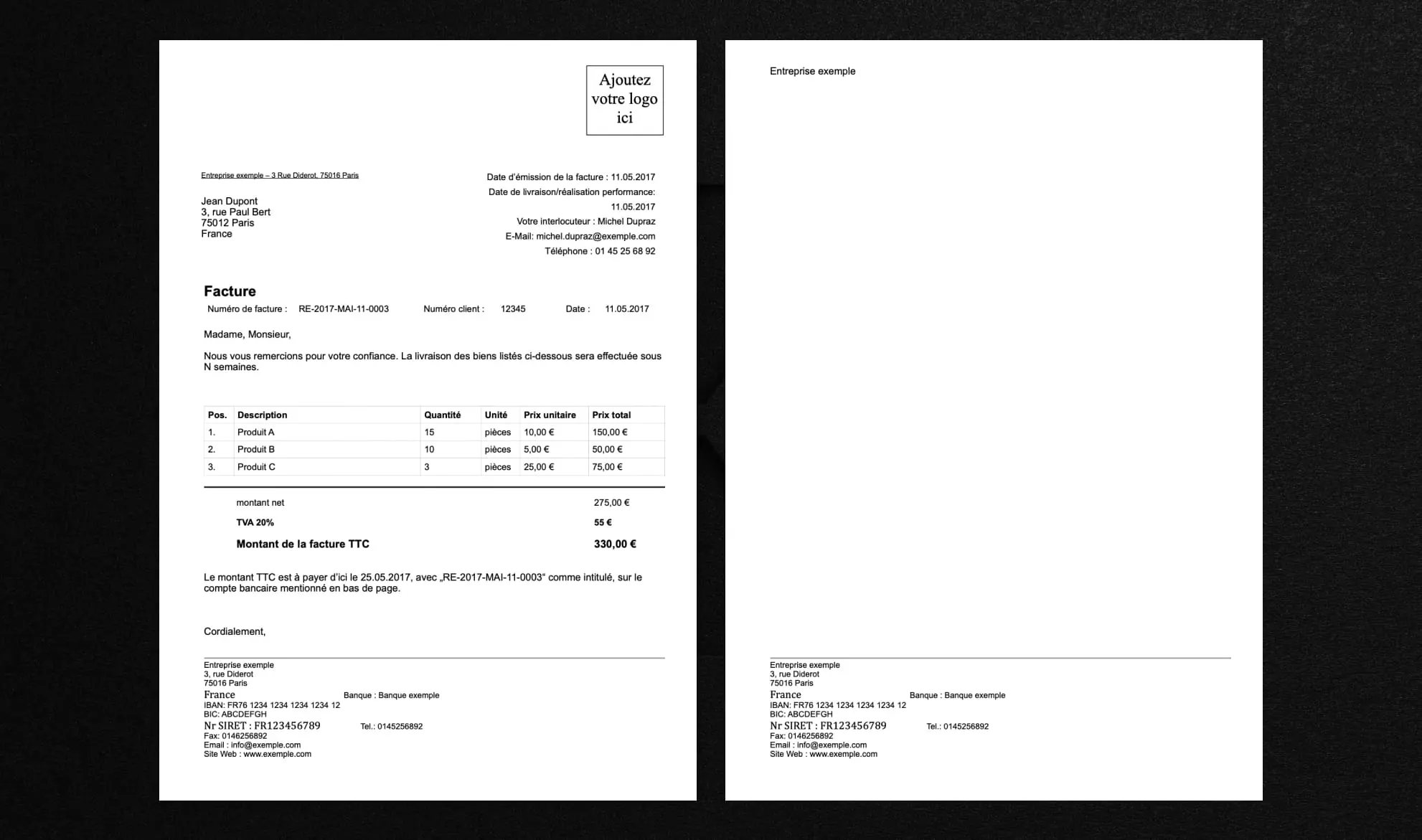
Diese einfache Rechnung dient als Testdokument für den Vergleich. In realen Automatisierungsszenarien werden üblicherweise deutlich umfangreichere und vielfältigere Dokumentensammlungen verwendet.
Diese Kategorie umfasst rein Open-Source OCR Lösungen.

Einfach. Ich konnte diese HTTP-API ohne Programmierkenntnisse erstellen, auch wenn es einige Zeit dauerte, die richtige Vorgehensweise zu finden. Falls Probleme auftreten, kann ein LLM den Integrationsprozess gut erklären.
Die extrahierte JSON-Datei kann direkt in ein ERP- oder CRM-System übertragen werden. Die Verarbeitung ist schnell und alle Daten wurden korrekt erkannt. Tabellen wurden identifiziert, Daten strukturiert und sogar Konfidenzwerte vergeben. In Bezug auf investierte Zeit und strukturierte Daten ist dies vermutlich die effizienteste Lösung dieser Kategorie.
Hier ein Bild eines JSON-Output-Ausschnitts von DocTR.

Mittel. Paddle OCR verarbeitet PDFs nicht nativ, daher musste ich eine zusätzliche Komponente integrieren. Das funktionierte, dauerte aber länger. Anschließend habe ich das PDF vorab in Bilder umgewandelt. Nach der Konvertierung hatte ich zwei Bilder und ermöglichte Mehrfach-Uploads für eine Extraktion. Paddle OCR ist primär für Texterkennung in Bildern konzipiert. In diesem Anwendungsfall ist die Integration deutlich einfacher.
Die Integration funktionierte und Paddle OCR extrahierte die Daten korrekt. Die JSON-Struktur ist jedoch deutlich weniger organisiert.
Hier ein Bild eines JSON-Output-Ausschnitts von Paddle OCR.
Einfach. Eine API mit FastAPI zu erstellen geht schnell, und Bildübertragung funktioniert sofort. Allerdings ist die Installation der System-Engine erforderlich, und PDF-Verarbeitung benötigt zusätzliche Schritte.
Tesseract extrahiert den Rechnungstext korrekt. Die wichtigsten Informationen sind vorhanden, werden jedoch als reiner Textblock zurückgegeben. Keine Tabellenstruktur oder Feldtrennung wird bereitgestellt. Zusätzliche Verarbeitung ist notwendig.
Hier ein Bild eines JSON-Output-Ausschnitts von Tesseract.

Relativ komplex. Im Gegensatz zu Tesseract funktioniert Kraken nicht sofort nach der Installation. Ein Modell muss separat geladen und konfiguriert werden. Die Integration erfordert mehrere Anpassungen. Es handelt sich nicht um eine Plug-and-Play Lösung.
Kraken nutzt Deep Learning und analysiert zunächst die visuelle Struktur der Seite. Bei modernen Rechnungen wird der Text erkannt, enthält jedoch mehr Fehler als bei Tesseract. Wie bei Tesseract erfolgt die Ausgabe als unstrukturierter Textblock. Kraken scheint eher für historische oder komplexe Dokumente geeignet zu sein.
Hier ein Bild eines JSON-Output-Ausschnitts von Kraken.
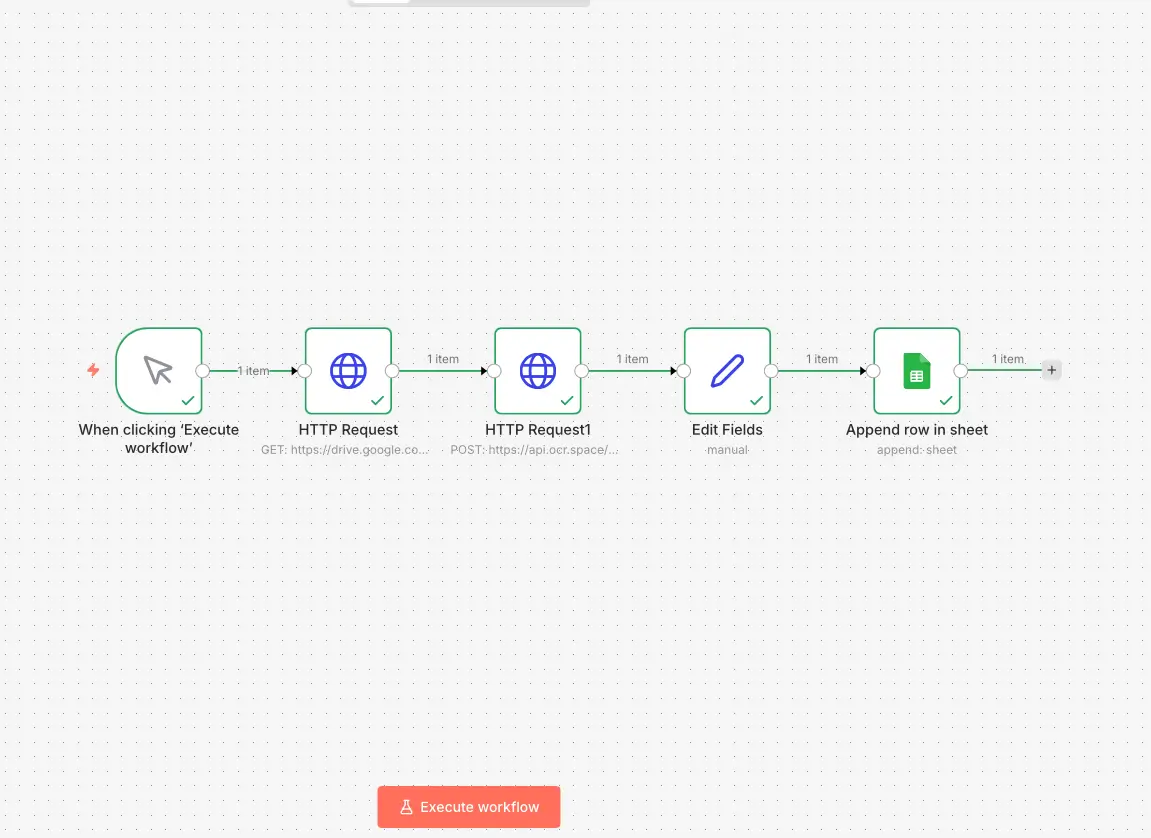
OCR.space ist keine selbst gehostete Open-Source Bibliothek, sondern ein SaaS-Service mit öffentlicher API, teilweise basierend auf Tesseract. Ich habe die Integration über n8n getestet.
Einfach. Integration erfolgt über einen grafisch konfigurierten HTTP-Request. Kein Server, keine Installation. Innerhalb weniger Minuten kann eine Datei gesendet und das JSON verarbeitet werden.
Die Verarbeitung ist schnell und der Text korrekt extrahiert. Die JSON-Antwort ist direkt nutzbar. Die Struktur bleibt jedoch relativ roh und erfordert weitere Verarbeitung.
Hier ein Bild der Output-Struktur von OCR.space.

Komplexe Integration. GOT OCR ist keine Plug-and-Play Lösung wie DocTR oder Paddle OCR. Installation erfordert erweitertes Setup.
Vision Language Models ermöglichen semantische Dokumentanalyse. Sie verknüpfen Informationen im Dokument und analysieren Bedeutungszusammenhänge. Dies ist besonders relevant bei komplexen Dokumenten. Diese Kategorie kommt vollständig integrierten Intelligent Document Processing Lösungen am nächsten.
DocTR ist die ausgewogenste Lösung. Strukturierter JSON-Output erleichtert Datenrekonstruktion.
Paddle OCR ist stark bei Texterkennung, benötigt aber Nachverarbeitung.
Tesseract ist am einfachsten zu integrieren, liefert aber Rohtext.
Kraken ist komplexer und weniger geeignet für moderne Rechnungen.
OCR.space ist am einfachsten zu integrieren.
GOT OCR ist am fortschrittlichsten, aber schwer zu implementieren.
Dieser Test zeigt vor allem eines: OCR ist nicht nur eine Frage der Genauigkeit, sondern der Integration.
Open-Source Engines funktionieren, erfordern aber Zeit und Konfiguration. Je strukturierter die Anwendungsfälle, desto wichtiger wird die Integrationsschicht. Die Entscheidung basiert auf Integrationsaufwand, Datenstruktur und Stabilität. Open-Source Lösungen eignen sich gut für kleine Projekte und Kostenkontrolle. Für stabile skalierbare Integrationen sind Intelligent Document Processing Lösungen meist einfacher einzusetzen.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Tristan Thommen entwirft und implementiert die technologischen Bausteine, die unstrukturierte Dokumente in nutzbare Daten umwandeln. Es kombiniert KI, OCR und Geschäftslogik, um das Leben von Teams zu vereinfachen.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


