


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Letzte Aktualisierung:
March 19, 2026
5 Minuten
Was wäre, wenn Ihre Dokumente wüssten, wohin sie gehen müssen... ohne dass Sie es ihnen sagen müssten? Das Dokumentenmanagement entwickelt sich weiter: Heute sind Technologien wie intelligente OCR in der Lage, Dokumente automatisch zu erkennen, zu sortieren und zu orientieren, auch wenn es sich um komplexe oder mehrsprachige Dokumente handelt. In diesem Artikel testen wir eine Klassifizierungsmaschine an einem konkreten Fall: Ausweisdokumenten aus mehreren Ländern. Erfahren Sie, wie Sie diese Sortierung präzise automatisieren können — ohne manuelle Konfiguration.
Intelligente OCR klassifiziert Dokumente automatisch. Ein praktisches Beispiel zur sicheren ID-Erkennung.
%20(1)%201.webp)
Dokumentenklassifizierung, automatische Kategorisierung, intelligentes Sortieren – all dies bezeichnet eine zentrale Fähigkeit in einer Arbeitswelt, die von Dokumenten überflutet wird. Ob Gehaltsabrechnungen, Lieferantenrechnungen, Verträge oder Ausweisdokumente: Die effiziente Organisation und Sortierung von Informationen ist heute in vielen Branchen entscheidend.
Banken, Versicherungen, Gesundheitswesen, Logistik, Personalwesen und sogar der öffentliche Sektor stehen vor einem massiven Zustrom heterogener und oft sensibler Dokumente, die schnell und präzise verarbeitet werden müssen. Doch manuelle Bearbeitung stößt schnell an Grenzen: Sie ist langsam, fehleranfällig und arbeitsintensiv.
Hier kommen Intelligent Document Processing (IDP)-Technologien ins Spiel. Künstliche Intelligenz, maschinelles Lernen und optische Zeichenerkennung (OCR) ermöglichen es heute, große Mengen an Dokumenten automatisch zu analysieren und zu klassifizieren.
Darunter versteht man die Fähigkeit, den Typ eines Dokuments (z. B. „Vertrag“, „Reisepass“, „Rechnung“ usw.) automatisch zu erkennen – ohne menschliches Eingreifen – um es dem richtigen Workflow oder der passenden Datenbank zuzuordnen.
Dieser Schritt ist entscheidend für jede Automatisierung, da er die nachfolgenden Phasen wie Datenerfassung, Validierung und Archivierung direkt beeinflusst.
In diesem Artikel veranschaulichen wir diese Fähigkeit anhand eines realen Anwendungsfalls: der automatischen Klassifizierung mehrsprachiger Ausweisdokumente (Personalausweise, Reisepässe, Führerscheine, Aufenthaltstitel) mit der Koncile-Lösung.
Koncile ist eine intelligente OCR-Software, die sich auf die präzise Datenerfassung aus komplexen Dokumenten wie Verträgen, Gehaltsabrechnungen, Finanzberichten oder Transportpapieren spezialisiert hat.
Unser Ziel ist einfach: ein schnelles, zuverlässiges System ohne manuelle Konfiguration bereitzustellen.
Damit ist es eine ideale OCR-Software zur Datenerfassung für Teams, die manuelle Arbeit reduzieren und Konsistenz über große Dokumentenmengen hinweg verbessern möchten.
In diesem Beispiel haben wir unsere automatische Klassifizierungs-Engine mit Ausweisdokumenten (Personalausweise, Reisepässe, Führerscheine, Aufenthaltstitel) aus mehreren Ländern getestet.
Wir verwendeten ein Set von 18 Dokumenten (Führerscheine, Aufenthaltstitel, Personalausweise, Reisepässe), darunter:
Ziel: Bewertung der Systemleistung ohne Kontextinformationen.
Hier sind die Schritte dieses ersten Tests:
1 – Erstellen eines Ordners für Ausweisdokumente
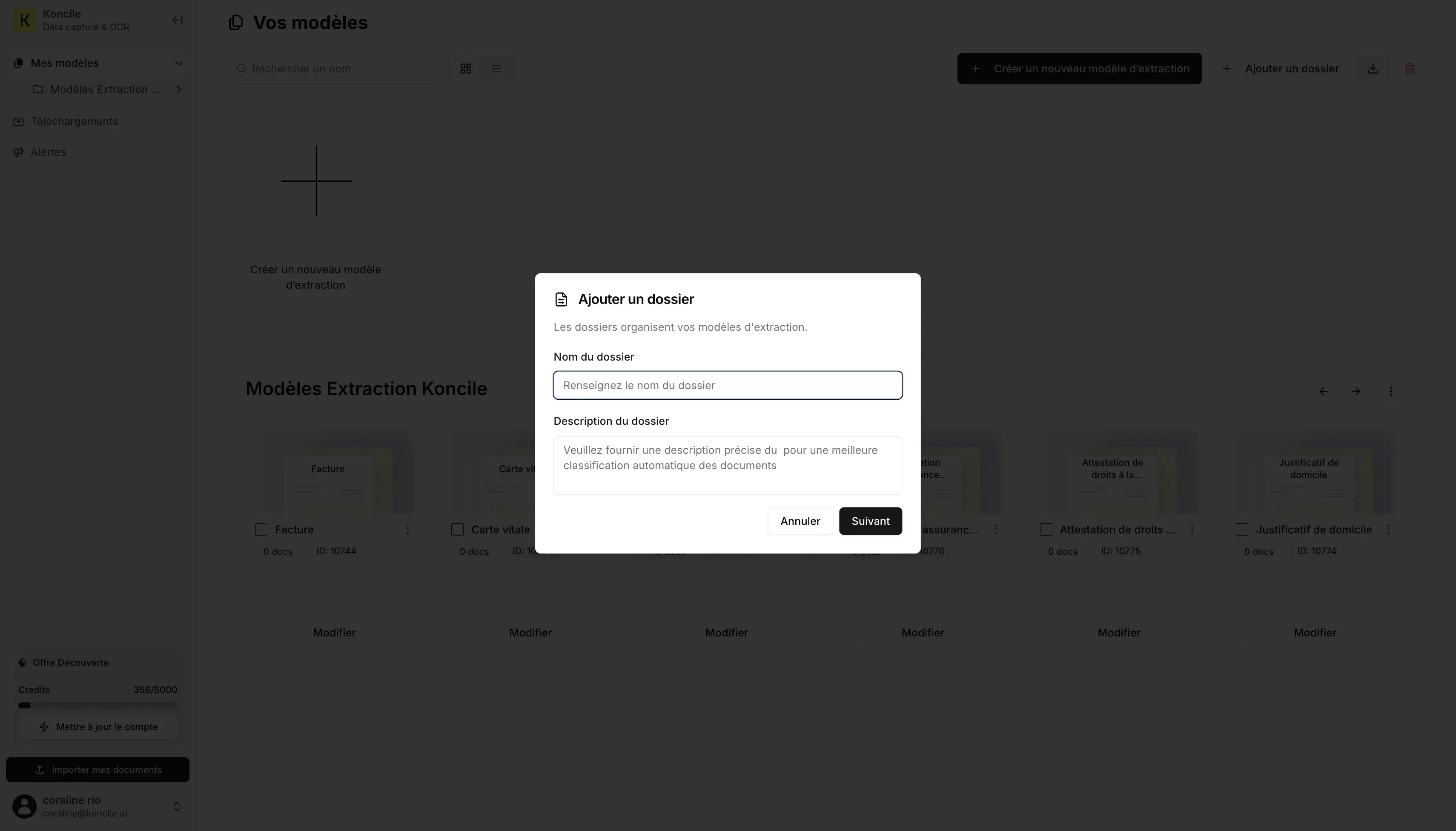
2 – Hinzufügen der verfügbaren Extraktionsvorlagen
In diesem Test geben wir keine Beschreibung der zu erfassenden Informationen an. Wir fügen einfach die bestehenden Vorlagen hinzu, die bereits in der Anwendung erstellt wurden.
3 – Import der verschiedenen Dokumenttypen ohne Klassifizierung
Wir importierten alle 18 Dokumente ohne Sortierregeln oder Anweisungen, um das Standardverhalten der Koncile-Engine zu beobachten.
Die Engine sollte in der Lage sein:
Ergebnisse von Test 1
Trotz fehlender Anweisungen konnte die Engine alle Dokumenttypen korrekt erkennen und automatisch klassifizieren – unabhängig von der Sprache. Erfolgsquote: 100 %.
Ziel: Automatische Unterscheidung französischer und britischer Ausweisdokumente ohne Kontext.
Mit zwei Ordnern (Frankreich / Vereinigtes Königreich) wurde die Komplexität erhöht. Die Engine sollte die Dokumente allein anhand des Inhalts zuordnen.
Ergebnisse von Test 2
15 von 18 Dokumenten wurden korrekt klassifiziert, was einer Erfolgsquote von 83,33 % entspricht. Fehler traten hauptsächlich bei italienischen Dokumenten auf, die mangels Kategorie fälschlich zugeordnet wurden.
Ziel: Beobachtung der Auswirkungen eines beschreibenden Prompts auf die Genauigkeit.
Ergebnisse von Test 3
Nach Hinzufügen eines präzisen Prompts erreichte das System eine Erfolgsquote von 100 %. Der Kontext half, die zuvor fehlerhaften Fälle korrekt zuzuordnen.
Automatische Dokumentenklassifizierung ist längst kein technisches Extra mehr, sondern ein strategischer Vorteil für jede Organisation mit großen Datenmengen.
Wie unsere Tests zeigen, liefert Koncile selbst ohne Konfiguration präzise Ergebnisse – dank fortschrittlicher visueller, textueller und kontextueller Analysefunktionen.
Durch gezielte Prompts oder erweiterte Sortierkategorien lässt sich die Leistung noch weiter steigern, wodurch Dokumentenmanagement schneller, sicherer und weitgehend automatisiert wird.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


