



Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dernière mise à jour :
June 26, 2026
5 minutes
En 2026, la fraude documentaire a un nouveau visage : le deepfake documentaire, un faux entièrement généré par IA. D'après l'Identity Fraud Index 2026 de Shufti, c'est la catégorie de fraude qui progresse le plus vite, avec une hausse annualisée estimée à près de 3 900 %. Leur particularité : ils sont propres en surface. Voici comment détecter ceux qui passent encore vos contrôles.
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
.webp)
En 2026, les deepfakes documentaires (faux générés par IA) explosent et passent les contrôles classiques : un faux rescanné ou régénéré a des métadonnées propres. La clé pour les détecter n'est plus le fichier mais la cohérence interne du contenu : montants, dates et identités qui ne tiennent pas ensemble. Cette couche récupère 20 à 30 % de fraude en plus. La détection fiable combine trois niveaux (analyse visuelle, métadonnées, cohérence sémantique), ce que Koncile réunit dans une seule plateforme, avec 99,8 % de fiabilité d'extraction et un hébergement en France.
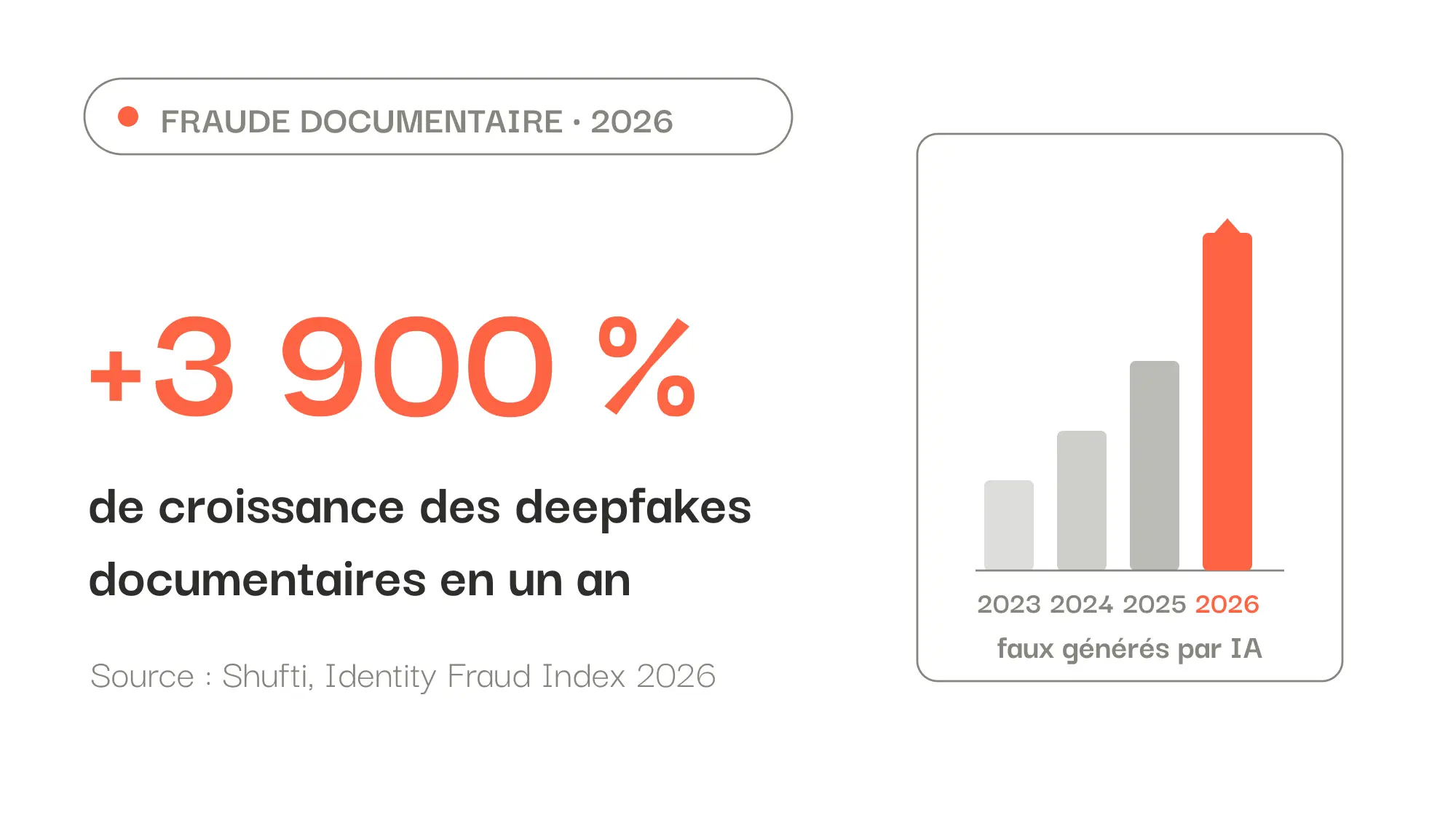
Pendant des années, détecter un faux document relevait de la forensique : repérer des pixels clonés, des artefacts de collage, des métadonnées modifiées. En 2026, ce modèle se fissure avec l'arrivée des deepfakes documentaires, ces faux entièrement générés par IA. Selon l'Identity Fraud Index 2026 de Shufti, c'est la catégorie de fraude qui croît le plus vite, avec une progression annualisée estimée à près de 3 900 %. L'ISACA rapporte de son côté le cas d'un auditeur qui découvre un document produit par IA, avec une signature synthétique et des métadonnées parfaitement cohérentes. Son constat : la qualité d'une preuve ne peut plus être présumée à partir du fichier lui-même.
Le problème, pour vos équipes, est concret. Les contrôles qui ont longtemps suffi examinent la fabrication du fichier : ses métadonnées, ses retouches au pixel. Or un deepfake documentaire, ou un faux imprimé puis rescanné, ne laisse plus rien à analyser de ce côté. Voici ce qui fonctionne vraiment pour les détecter, et comment choisir un logiciel de détection de fraude documentaire capable de les attraper.
La détection classique regarde comment le fichier a été fabriqué : l'éditeur du PDF, l'historique de modification, la cohérence des polices, les traces laissées par Photoshop, Canva, iLovePDF ou un traitement de texte. Ces méthodes de détection restent utiles quand un fraudeur bricole un document existant. Le problème, c'est qu'il est devenu facile de ne plus laisser aucune trace.
Dans ces trois cas, l'enveloppe est propre. Reste à lire ce qu'il y a dedans. Pour les indices côté fichier, voyez notre article sur les signaux faibles des métadonnées.
Un document falsifié laisse presque toujours des incohérences logiques que son auteur n'a pas pu toutes corriger. Truquer un bulletin de paie de façon crédible suppose de recalculer chaque montant à la virgule près, de refaire les cumuls et d'ajuster les cotisations. C'est rarement mené jusqu'au bout. L'analyse de cohérence sémantique part de là : elle vérifie que les informations du document tiennent ensemble, et qu'elles tiennent avec les autres pièces du dossier.
D'après notre expérience terrain, cette couche de cohérence récupère 20 à 30 % de la fraude que l'analyse visuelle, métadonnées et pixels, laisse passer. L'enjeu n'a rien de marginal : un assureur mutualiste nous confiait que la fraude pèse 1 à 2 % de son chiffre d'affaires, soit plusieurs millions d'euros par an.
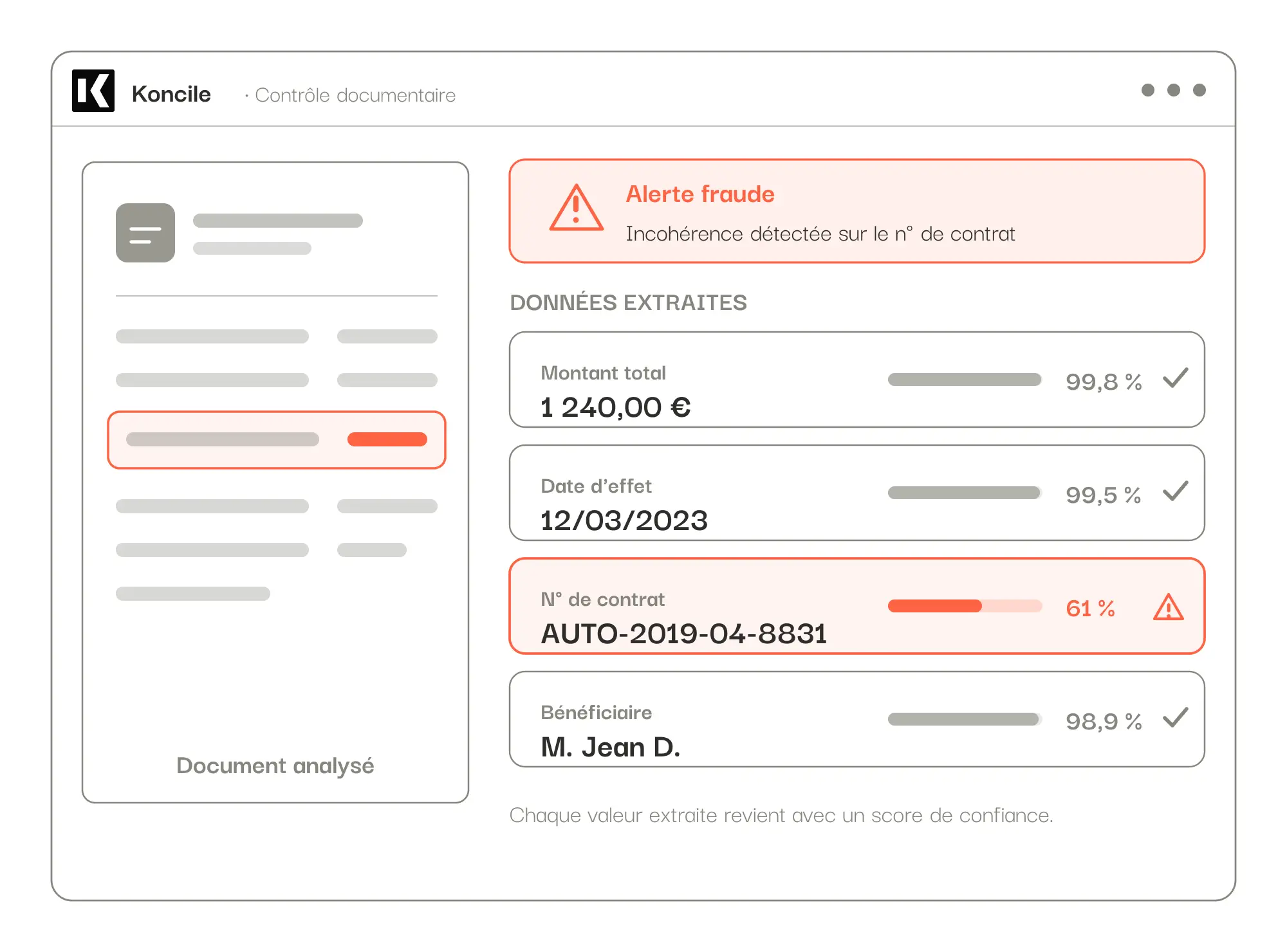
Relevé d'information (assurance). Chez un acteur de l'assurance que nous accompagnons, les faux relevés se trahissent par des incohérences précises : un coefficient de réduction-majoration (CRM) qui ne colle pas avec l'historique, un numéro de contrat qui encode une date différente de la date d'effet affichée, une adresse e-mail incohérente avec le nom et le code postal du souscripteur, ou un conducteur différent du souscripteur. Certains faux sont même entièrement régénérés par le fraudeur : aucune retouche à repérer, seulement des croisements qui ne collent pas.

Bulletin de paie. On recompose les totaux. Quand le document a été manipulé, les montants ne tombent jamais tout à fait juste.
Relevé bancaire. On compare le relevé à un gabarit connu de la même banque et on vérifie la cohérence interne des opérations ; l'extraction du relevé bancaire alimente ces contrôles.
Facture. On rapproche les lignes, les totaux et le fournisseur : c'est souvent là que se repère une falsification de facture avant paiement.
Entre plusieurs documents. La fraude n'est pas toujours dans une pièce isolée. Une mutuelle nous décrivait des prestations facturées à tort : un assuré hospitalisé qui présente, sur la même période, des séances de kinésithérapie. L'incohérence se lit entre les documents, pas dans un seul.
La cohérence ne remplace pas les métadonnées : elle les complète. Se reposer sur une seule couche produit des faux positifs coûteux. Un exemple vécu : un document parfaitement authentique avait été produit avec une bibliothèque logicielle par ailleurs utilisée pour fabriquer des faux. La bannir sur ce seul critère revenait à bloquer des dossiers légitimes. C'est l'analyse du contenu qui tranche ces cas ambigus.
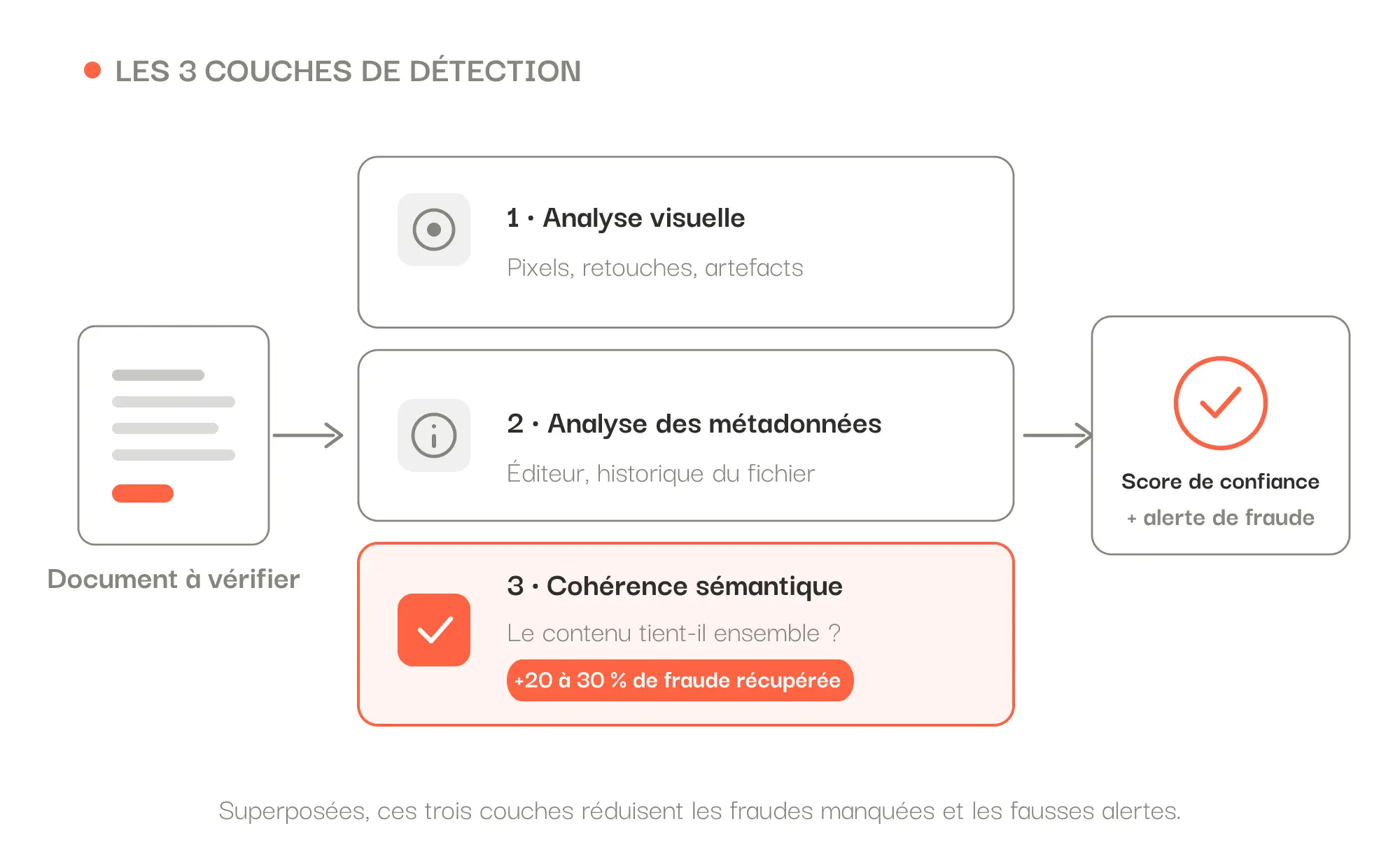
La bonne approche superpose donc trois niveaux : l'analyse visuelle (pixels, retouches), l'analyse des métadonnées (éditeur, historique) et l'analyse de cohérence sémantique du contenu. Ensemble, ils réduisent à la fois les fraudes manquées et les fausses alertes.
Pour une équipe conformité, lutte anti-fraude ou onboarding KYC, deux choses comptent.
D'abord, libérer du temps. En attribuant un score de confiance à chaque donnée extraite, on ne fait relire que ce qui doit l'être. Chez nos clients, cela représente de l'ordre de 90 % de temps de revue en moins, l'humain restant concentré sur les cas à risque.
Ensuite, choisir le bon outil. En 2026, un simple score de métadonnées ne suffit plus. Trois questions à poser avant de signer :
Le cadre réglementaire pousse dans le même sens. L'article 50 de l'AI Act européen, applicable à partir d'août 2026, impose le marquage des contenus générés par IA. La traçabilité de la décision devient un sujet de conformité, pas seulement d'efficacité. Si vous comparez des solutions, notre comparatif des outils de détection de fraude documentaire détaille les approches du marché.
Koncile réunit les trois couches dans une seule plateforme : vision par ordinateur pour l'analyse visuelle, analyse des métadonnées et analyse de cohérence sémantique du contenu. Là où beaucoup d'approches s'arrêtent aux métadonnées, nous lisons aussi ce que le document dit, et nous vérifions que tout tient ensemble. C'est le cœur de notre approche de détection de fraude documentaire.
Concrètement, notre traitement OCR structure la donnée et vous paramétrez vos contrôles en langage naturel, sans code, pour qu'ils épousent vos documents et vos règles métier. Chaque valeur extraite revient avec un score de confiance. Sur la donnée extraite, notre benchmark interne, relancé à chaque mise à jour, mesure 99,8 % de fiabilité. Cette mesure porte sur l'extraction des données, distincte de la détection de fraude que nous enrichissons en continu. Le traitement va de quelques secondes à une trentaine de secondes par document, et il est entièrement parallélisé.
En amont, Koncile sépare les liasses multi-pages par découpage intelligent, ce qui évite de mélanger les pièces d'un même dossier.
Côté sécurité, Koncile est certifié SOC 2 Type II et ISO 27001, conforme au RGPD, avec un hébergement en France. Les résultats s'intègrent à vos systèmes via notre API OCR.
Vous voulez voir comment Koncile analyse la cohérence de vos documents et repère les faux qui passent encore vos contrôles ? Réservez une démo.
Oui. Au-delà de l'analyse des métadonnées et des pixels, Koncile vérifie la cohérence interne du contenu : montants, dates, identités et recoupements entre les pièces d'un dossier. C'est ce qui permet de repérer les faux régénérés par IA ou imprimés puis rescannés, dont les métadonnées sont propres.
En croisant plusieurs couches d'analyse plutôt qu'un seul signal, et en attribuant un score de confiance à chaque résultat. Les contrôles se règlent par métier pour coller à vos documents, ce qui évite de bloquer des dossiers légitimes.
Les plus falsifiés : bulletins de paie, avis d'imposition, relevés bancaires, factures et relevés d'information d'assurance. Les règles s'adaptent à d'autres pièces selon votre activité.
Oui. Koncile est hébergé en France, conforme au RGPD et certifié SOC 2 Type II et ISO 27001. Vos documents ne servent pas à entraîner les modèles.
Oui. Vous décrivez vos contrôles en langage naturel, sans code, et Koncile les applique à vos types de documents et à vos règles métier, avec une piste d'audit sur chaque décision.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs

Cinq solutions OCR françaises comparées pour extraire vos données documentaires en toute conformité RGPD, serveurs hébergés en France.
Comparatifs
.png)


