



Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Letzte Aktualisierung:
June 26, 2026
5 Minuten
2026 hat der Dokumentenbetrug ein neues Gesicht: den Dokumenten-Deepfake, eine vollständig von KI erzeugte Fälschung. Laut dem Identity Fraud Index 2026 von Shufti ist dies die am schnellsten wachsende Betrugskategorie, mit einem auf das Jahr hochgerechneten Anstieg von schätzungsweise fast 3.900 %. Das Besondere: Sie sind an der Oberfläche sauber. So erkennen Sie diejenigen, die Ihre Prüfungen noch passieren.
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
.webp)
2026 nehmen Dokumenten-Deepfakes (KI-generierte Fälschungen) stark zu und bestehen klassische Prüfungen: Eine neu gescannte oder vollständig neu generierte Fälschung trägt saubere Metadaten. Der Schlüssel, um sie zu erkennen, ist nicht mehr die Datei, sondern die interne Kohärenz des Inhalts: Beträge, Daten und Identitäten, die nicht zusammenpassen. Diese Ebene deckt 20 bis 30 % mehr Betrug auf. Zuverlässige Erkennung kombiniert drei Ebenen (visuelle Analyse, Metadaten, semantische Kohärenz), die Koncile in einer einzigen Plattform vereint, mit 99,8 % Extraktionszuverlässigkeit und Hosting in Frankreich.
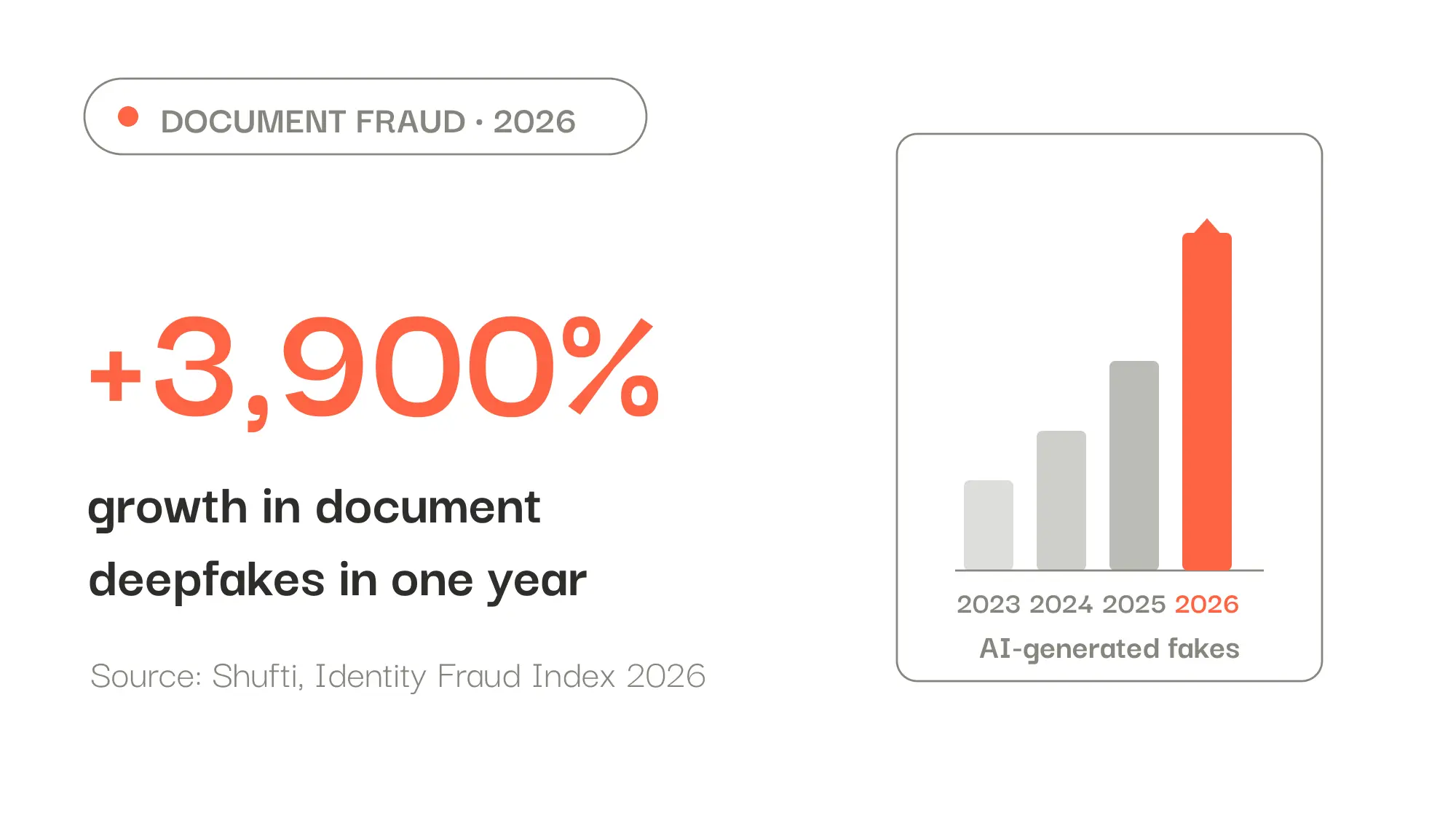
Jahrelang war das Erkennen einer Fälschung eine forensische Aufgabe: geklonte Pixel aufspüren, Montage-Artefakte, veränderte Metadaten. 2026 bröckelt dieses Modell mit dem Aufkommen der Dokumenten-Deepfakes, also vollständig von KI erzeugter Fälschungen. Laut dem Identity Fraud Index 2026 von Shufti ist dies die am schnellsten wachsende Betrugskategorie, mit einem auf das Jahr hochgerechneten Anstieg von schätzungsweise fast 3.900 %. Die ISACA berichtet ihrerseits vom Fall eines Prüfers, der ein von KI erstelltes Dokument entdeckt, mit synthetischer Signatur und einwandfrei stimmigen Metadaten. Sein Fazit: Die Qualität eines Beweises lässt sich nicht mehr aus der Datei selbst ableiten.
Das Problem ist für Ihre Teams konkret. Die Kontrollen, die lange ausreichten, prüfen, wie die Datei erstellt wurde: ihre Metadaten, ihre pixelgenauen Retuschen. Ein Dokumenten-Deepfake aber, oder eine gedruckte und neu eingescannte Fälschung, lässt auf dieser Seite nichts mehr zu analysieren. Hier erfahren Sie, was wirklich funktioniert, um sie zu erkennen, und wie Sie eine Software zur Dokumentenbetrug-Erkennung wählen, die sie erwischt.
Die klassische Erkennung betrachtet, wie die Datei erstellt wurde: den PDF-Editor, den Bearbeitungsverlauf, die Konsistenz der Schriftarten, die Spuren von Photoshop, Canva, iLovePDF oder einem Textverarbeitungsprogramm. Diese Erkennungsmethoden sind weiterhin nützlich, wenn ein Betrüger ein bestehendes Dokument manipuliert. Das Problem: Es ist leicht geworden, gar keine Spur mehr zu hinterlassen.
In allen drei Fällen ist die Hülle sauber. Bleibt zu lesen, was darin steht. Für die Hinweise auf Dateiebene siehe unseren Artikel über die schwachen Signale in den Metadaten.
Ein gefälschtes Dokument hinterlässt fast immer logische Widersprüche, die sein Urheber nicht alle beheben konnte. Eine Gehaltsabrechnung glaubwürdig zu fälschen, bedeutet, jeden Betrag auf den Cent genau neu zu berechnen, die Summen neu zu bilden und die Beiträge anzupassen. Das wird selten zu Ende geführt. Die semantische Kohärenzanalyse setzt genau hier an: Sie prüft, ob die Informationen des Dokuments in sich stimmig sind und ob sie mit den übrigen Unterlagen des Vorgangs zusammenpassen.
Nach unserer Praxiserfahrung deckt diese Kohärenzebene 20 bis 30 % des Betrugs auf, den die visuelle Analyse, also Metadaten und Pixel, durchgehen lässt. Die Tragweite ist nicht gering: Ein Versicherungsverein auf Gegenseitigkeit berichtete uns, dass Betrug 1 bis 2 % seines Umsatzes ausmacht, also mehrere Millionen Euro pro Jahr.
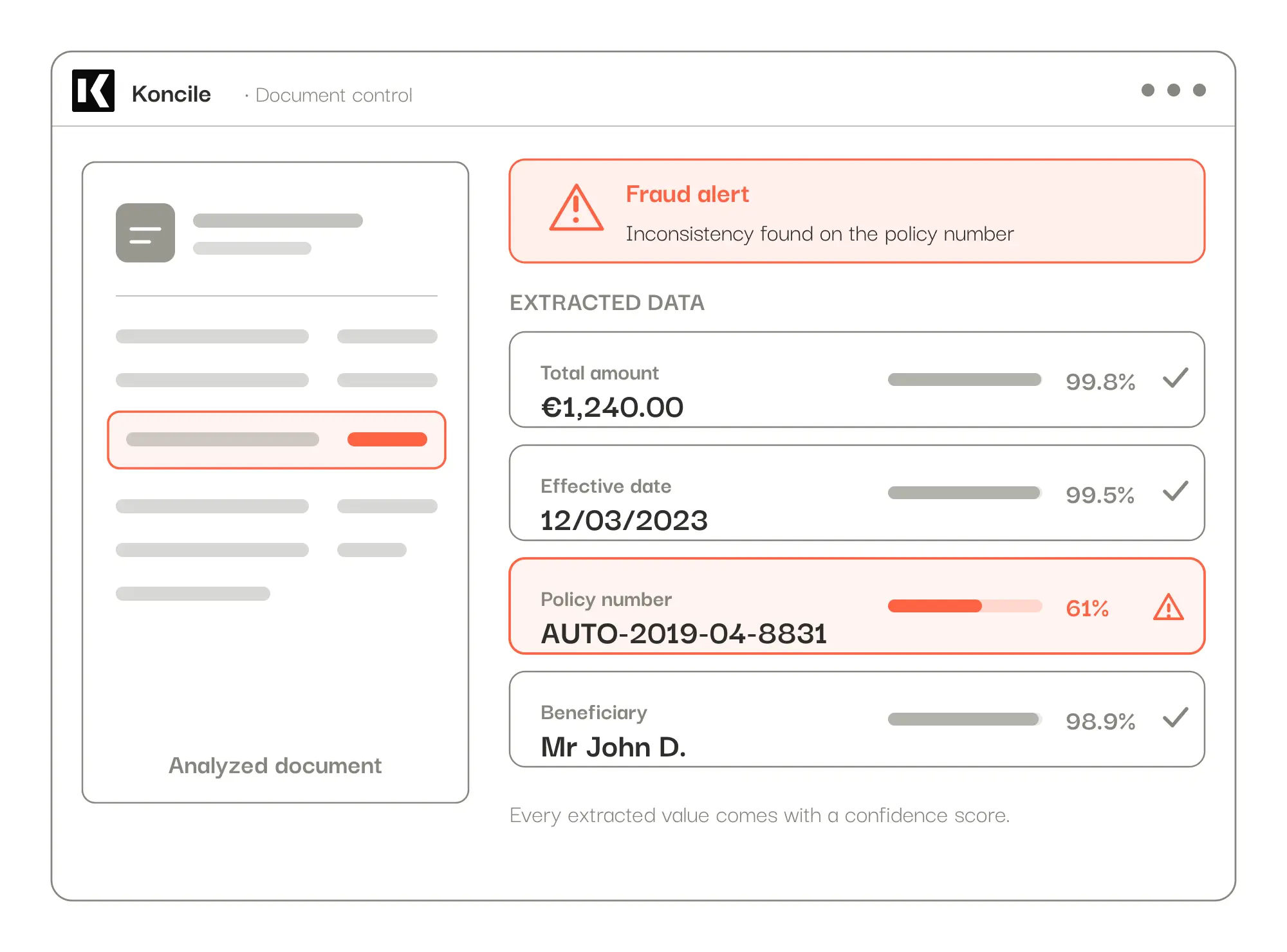
Schadenfreiheitsnachweis (Versicherung). Bei einem Versicherer, den wir begleiten, verraten sich gefälschte Nachweise durch präzise Widersprüche: ein Schadenfreiheitsrabatt, der nicht zur Historie passt, eine Vertragsnummer, die ein anderes Datum codiert als das angegebene Wirksamkeitsdatum, eine E-Mail-Adresse, die nicht zu Name und Postleitzahl des Versicherungsnehmers passt, oder ein Fahrer, der nicht der Versicherungsnehmer ist. Manche Fälschungen werden sogar vollständig vom Betrüger neu generiert: keine Retusche zu finden, nur Querbezüge, die nicht stimmen.

Gehaltsabrechnung. Man rechnet die Summen nach. Wurde das Dokument manipuliert, gehen die Beträge nie ganz auf.
Kontoauszug. Man vergleicht den Auszug mit einer bekannten Vorlage derselben Bank und prüft die interne Stimmigkeit der Vorgänge; die Extraktion des Kontoauszugs speist diese Prüfungen.
Rechnung. Man gleicht Positionen, Summen und Lieferant ab: Genau dort zeigt sich oft eine Rechnungsfälschung vor der Zahlung.
Über mehrere Dokumente hinweg. Betrug steckt nicht immer in einem einzelnen Dokument. Ein Krankenversicherer schilderte uns zu Unrecht abgerechnete Leistungen: ein hospitalisierter Versicherter, der im selben Zeitraum Physiotherapie-Sitzungen einreicht. Der Widerspruch zeigt sich zwischen den Dokumenten, nicht in einem einzelnen.
Kohärenz ersetzt die Metadaten nicht, sie ergänzt sie. Sich auf eine einzige Ebene zu verlassen, erzeugt teure Fehlalarme. Ein erlebtes Beispiel: Ein vollkommen echtes Dokument war mit einer Softwarebibliothek erstellt worden, die auch zum Fälschen genutzt wird. Sie allein deshalb zu sperren, hätte bedeutet, legitime Vorgänge zu blockieren. Es ist die Inhaltsanalyse, die solche mehrdeutigen Fälle entscheidet.
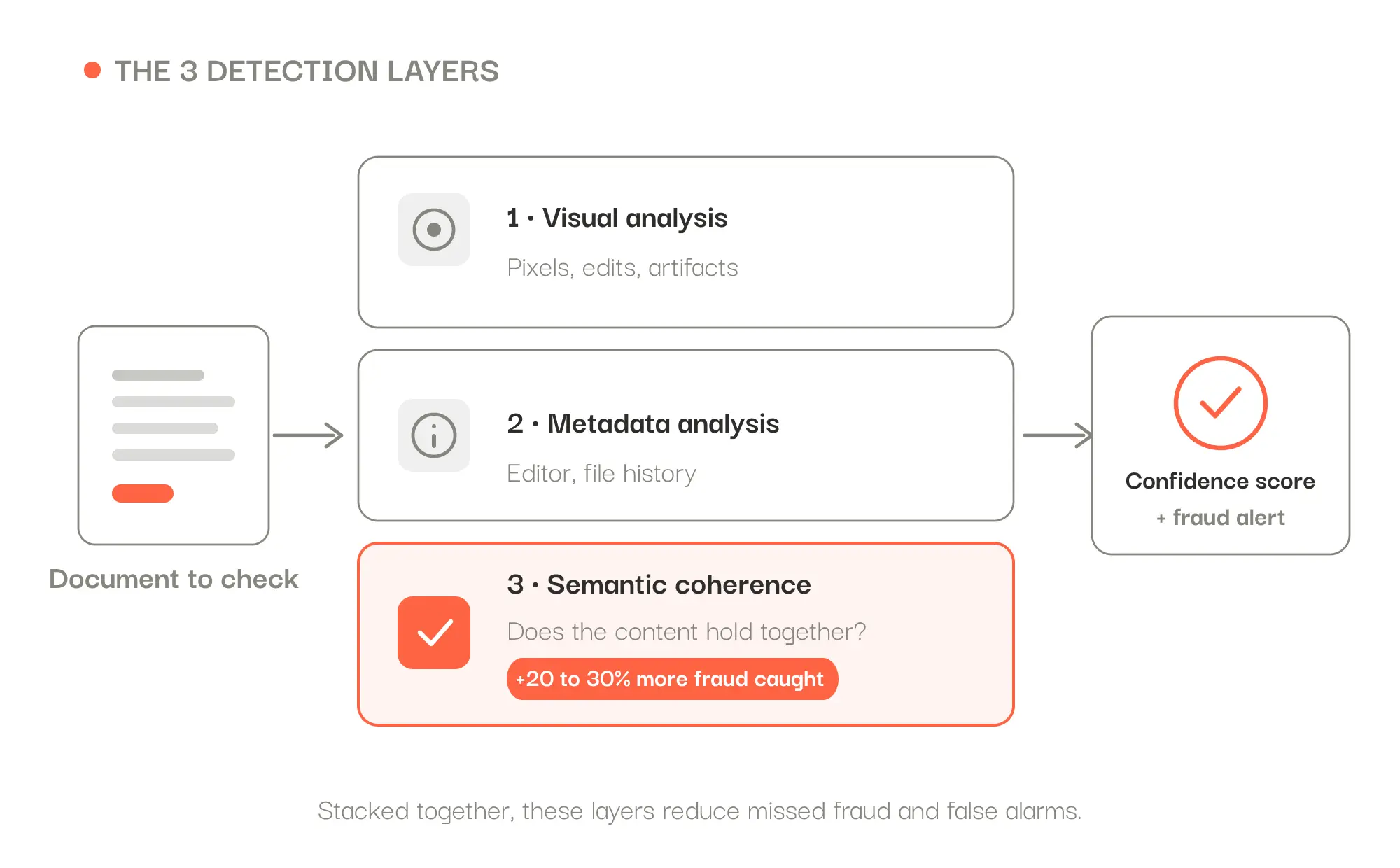
Der richtige Ansatz schichtet daher drei Ebenen übereinander: die visuelle Analyse (Pixel, Retuschen), die Metadaten-Analyse (Editor, Verlauf) und die semantische Kohärenzanalyse des Inhalts. Zusammen verringern sie sowohl übersehenen Betrug als auch Fehlalarme.
Für ein Team in Compliance, Betrugsbekämpfung oder KYC-Onboarding zählen zwei Dinge.
Erstens: Zeit gewinnen. Indem jedem extrahierten Wert ein Konfidenzwert zugewiesen wird, prüfen Sie nur noch, was geprüft werden muss. Bei unseren Kunden bedeutet das rund 90 % weniger Prüfzeit, während sich die Mitarbeitenden auf die riskanten Fälle konzentrieren.
Zweitens: das richtige Werkzeug wählen. 2026 reicht ein einfacher Metadaten-Score nicht mehr. Drei Fragen, die Sie vor der Unterschrift stellen sollten:
Die Regulierung weist in dieselbe Richtung. Artikel 50 des EU-KI-Gesetzes, ab August 2026 in Kraft, schreibt die Kennzeichnung KI-generierter Inhalte vor. Die Nachvollziehbarkeit der Entscheidung wird zur Compliance-Frage, nicht nur zur Effizienzfrage.
Koncile vereint die drei Ebenen in einer einzigen Plattform: Computer Vision für die visuelle Analyse, die Metadaten-Analyse und die semantische Kohärenzanalyse des Inhalts. Wo viele Ansätze bei den Metadaten aufhören, lesen wir auch, was das Dokument aussagt, und prüfen, dass alles zusammenpasst. Das ist der Kern unseres Ansatzes zur Dokumentenbetrug-Erkennung.
In der Praxis strukturiert unsere KI-OCR die Daten, und Sie richten Ihre Prüfungen in natürlicher Sprache ein, ohne Code, sodass sie zu Ihren Dokumenten und Ihren Geschäftsregeln passen. Jeder extrahierte Wert kommt mit einem Konfidenzwert. Auf den extrahierten Daten misst unser interner Benchmark, der bei jedem Update neu läuft, 99,8 % Zuverlässigkeit. Diese Kennzahl betrifft die Datenextraktion und ist von der Betrugserkennung zu unterscheiden, die wir laufend weiterentwickeln. Die Verarbeitung dauert von wenigen Sekunden bis zu rund dreißig Sekunden pro Dokument und ist vollständig parallelisiert.
Vorgelagert trennt Koncile mehrseitige Stapel durch intelligente Dokumententrennung, sodass die Bestandteile eines Vorgangs nicht vermischt werden.
In puncto Sicherheit ist Koncile nach SOC 2 Type II und ISO 27001 zertifiziert, DSGVO-konform und mit Hosting in Frankreich. Die Ergebnisse fügen sich über unsere OCR-API in Ihre Systeme ein.
Möchten Sie sehen, wie Koncile die Kohärenz Ihrer Dokumente analysiert und die Fälschungen erkennt, die Ihre Prüfungen noch passieren? Demo buchen.
Ja. Über die Analyse von Metadaten und Pixeln hinaus prüft Koncile die interne Kohärenz des Inhalts: Beträge, Daten, Identitäten und Abgleiche zwischen den Dokumenten eines Vorgangs. So werden auch per KI neu generierte oder gedruckte und neu eingescannte Fälschungen erkannt, deren Metadaten sauber sind.
Indem wir mehrere Analyseebenen statt eines einzigen Signals kombinieren und jedem Ergebnis einen Konfidenzwert zuweisen. Die Prüfungen werden je nach Anwendungsfall an Ihre Dokumente angepasst, sodass legitime Vorgänge nicht blockiert werden.
Die am häufigsten gefälschten: Gehaltsabrechnungen, Steuerbescheide, Kontoauszüge, Rechnungen und Versicherungsnachweise. Die Regeln lassen sich je nach Tätigkeit an weitere Dokumente anpassen.
Ja. Koncile wird in Frankreich gehostet, ist DSGVO-konform und nach SOC 2 Type II und ISO 27001 zertifiziert. Ihre Dokumente werden nicht zum Training der Modelle verwendet.
Ja. Sie beschreiben Ihre Prüfungen in natürlicher Sprache, ohne Code, und Koncile wendet sie auf Ihre Dokumenttypen und Geschäftsregeln an, mit einer Prüfspur für jede Entscheidung.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative

Fünf französische OCR-Lösungen im Vergleich – für die DSGVO-konforme Extraktion Ihrer Dokumentendaten, mit Servern in Frankreich.
Komparative
.png)


