


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
September 8, 2025
5 minutes
Named Entity Recognition (NER) makes it possible to automatically identify key information in a text, such as names, dates, or amounts. Learn how it works and why it has become indispensable in document automation projects.
Do you want to understand how to automatically extract essential information from a text? Discover how NER turns your documents into data, ready to be used.
The Named Entity Recognition (NER), or named entity recognition, is a technology derived from automatic natural language processing (NLP).
It makes it possible to automatically identify, in a plain text, key elements such as:
Its objective is simple: to transform unstructured content into data that can be used by a machine.
Concretely, the NER is based on two main stages:
Historically, the first NER systems were based on simple rules or Fuzzy Matching, consisting in comparing character strings with reference lists while allowing small differences (accents, typos, abbreviations...).
These approaches, while effective in some cases, lacked robustness and precision in varied or noisy contexts. They have since been greatly enriched by more advanced methods, in particular by deep learning and semantic embeddings.
When properly deployed, NER brings concrete benefits in many business contexts:
This Named Entity Recognition process follows a series of structured steps, combining linguistic, statistical, and machine learning techniques.
Here are the main phases in the functioning of the NER:
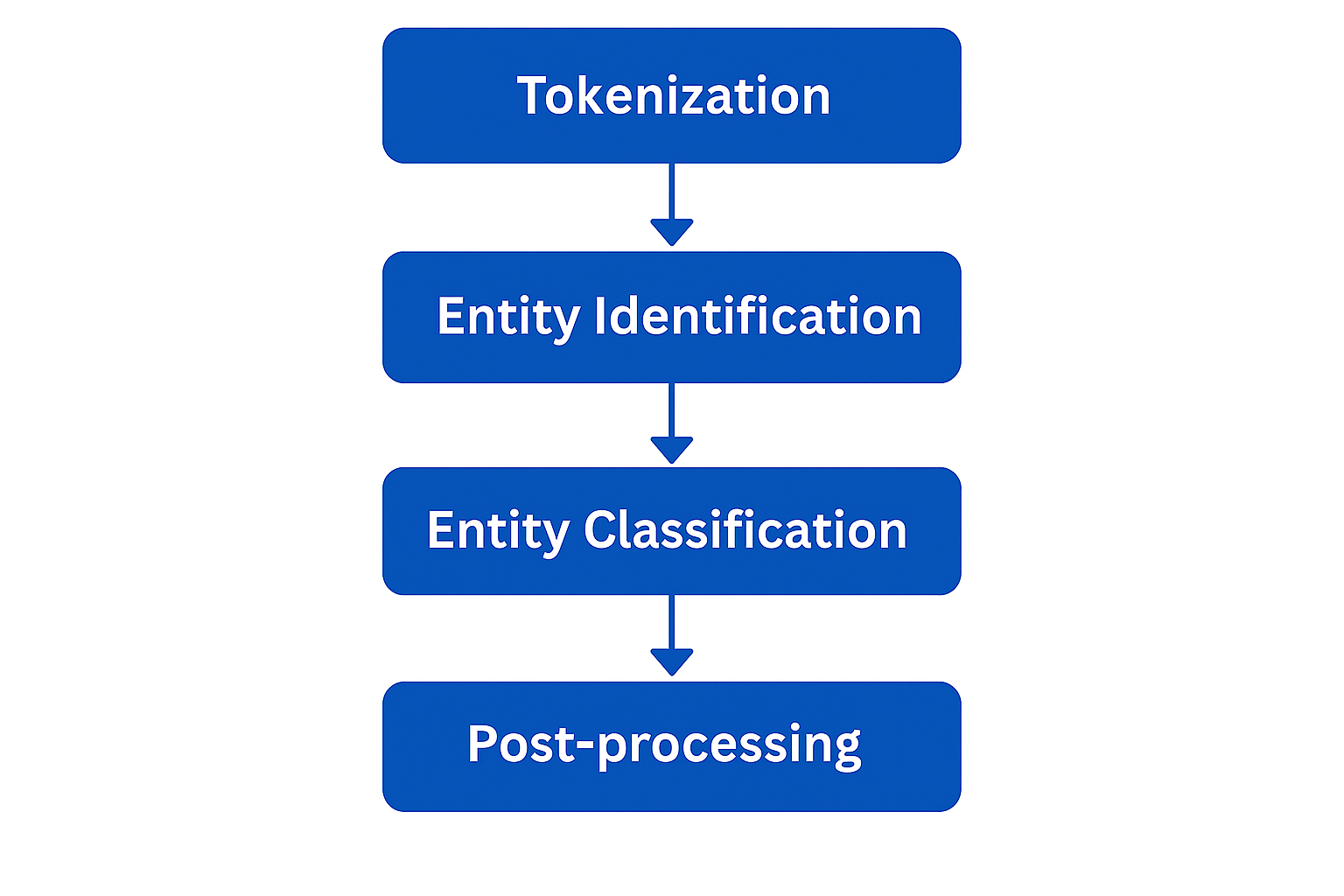
It all starts with the Tokenization, which consists of dividing plain text into elementary units called Tokens : words, punctuation marks, dates, numbers... This segmentation makes it possible to prepare the ground for the next steps of linguistic analysis.
For example, the sentence:
.webp)
will be segmented into:
["The", "48th", "World", "Hospital", "Congress", "will", "take", "place", "in", "Geneva", "from", "November", "10", "to", "13", ",", "2025", "."]The second step is to identify word groups that could correspond to named entities. This detection is based on:
The objective here is to identify segments in the text flow that “look” like entities.
Once potential entities are detected, the system classify into predefined categories.

This ranking is generally carried out by a trained model on annotated datasets. Algorithms such as CRFs (Conditional Random Fields) or neural networks are commonly used for this task.
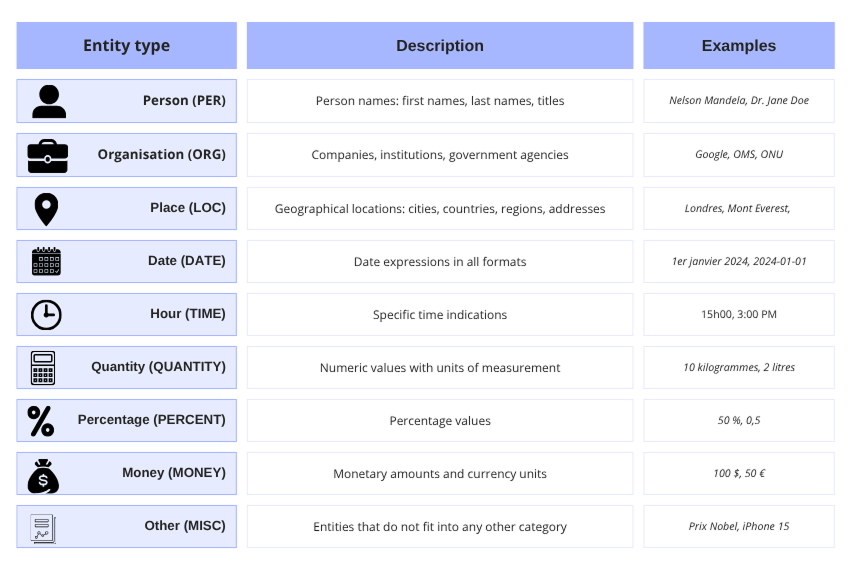
Understanding these categories is critical to fully exploiting NER's capabilities. Here is an overview of the most common types:
The context is essential to ensure the accuracy of the NER. Some words or names may refer to different entities depending on usage.
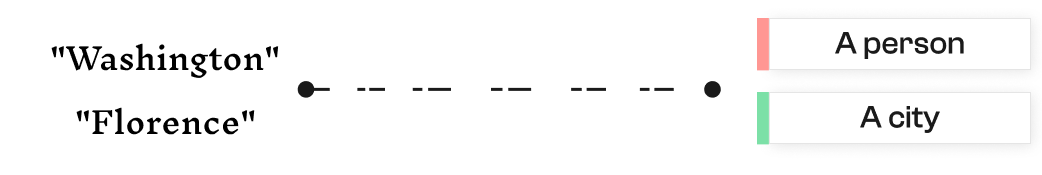
Contextual analysis makes it possible to remove these ambiguities by taking into account neighboring words, syntax, and even the structure of the document. It also allows you to manage nested entities (for example: “President Barack Obama of the United States” contains two distinct entities).
With modern models, expanding the analysis context significantly improves the disambiguation. It is now possible to use a prompt to automatically compare a detected entity to a list of several thousand items (e.g. 100,000 business names), by short-listing the closest matches.
Finally, a post-treatment phase refines the results:
This step can also generate structured output, such as a JSON or XML file, where each entity is tagged, making it easy to integrate into an information system or an automated process.
Several approaches have been developed to effectively implement named entity recognition (NER). Here is a detailed explanation of the most common methods:
Rule-based NER systems operate on the basis of manually defined linguistic models. In particular, it includes:
Machine learning-based methods involve training a statistical model on annotated examples so that it can learn to recognize entities.
Deep learning has dramatically improved NER performance, relying on neural networks that can learn directly from plain text.
Hybrid systems combine many of the above methods to take advantage of their respective advantages. For example:
Moreover, some recent hybrid approaches combine semantic embeddings and fuzzy matching to calculate the similarity between a detected entity and external databases. This makes it possible to intelligently identify matches even if the character strings differ.
To ensure good performance and optimal accuracy, the implementation of NER must follow several key steps. Here are the key recommendations:
Depending on your goals — rapid integration, advanced customization, or large-scale processing — you can opt for open source libraries Or ready-to-use cloud services.
These solutions are particularly suited to custom projects and Python or Java development environments. Here are the three most popular:
Renowned for its speed and ease of integration, SpacY is now one of the most used NLP libraries in production. It offers pre-trained models for NER in several languages and allows effective fine-tuning. Its ecosystem is well documented and largely maintained by the community.
Developed by Zalando Research, Flair makes it possible to combine several deep learning models (such as BERT, ElMo) to improve the accuracy of extracted entities. It is distinguished by its multilingual support and its flexibility in research or experimental projects.
Robust tool, particularly appreciated for its linguistic precision and its multilingual support. Developed in Java with Python wrappers available, CoreNLP remains an academic and professional reference, although more demanding in terms of system resources.
Ideal for businesses that want to quickly integrate NER into their systems, without managing model training or hosting.
Offers rich entity extraction, with categorization, relevance score, and syntactic analysis. Perfect for large-scale cloud applications.
Native NER solution in the AWS ecosystem. It automatically identifies entities (names, places, dates...) and is easily integrated into serverless architectures or automated processing pipelines.
A comprehensive API for large accounts, which goes beyond NER. It also makes it possible to analyze emotions, semantic relationships, concepts or intentions, with advanced levels of configuration.
Despite its promising performances, NER is still facing several limitations that are important to anticipate in order to ensure effective implementation.
The same word can refer to several types of entities depending on the domain or current usage.
For example:
Without disambiguation, models may mislabel these entities, especially in short or ambiguous contexts.
The meaning of an entity also depends on Its position in the sentence and syntactic relationships.
Let's take the following example:
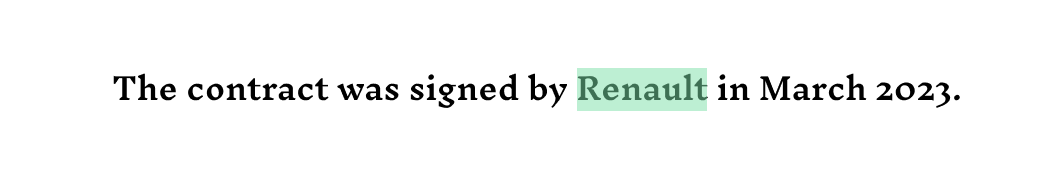
Here, “Renault” is indeed a organizing.
But in:

The same word is associated with sports stable, and not to the car company in its strict sense.
Modern models like BERT or Roberta, trained on bi-directional contexts, are able to capture these nuances to improve classification.
Languages have differences in syntax, capitalization, or entity formats. Some languages don't have clear conventions for proper nouns. The NER must adapt to these variations, often using multilingual or language-by-language trained models.
Supervised learning requires annotated corpora, which are often unavailable in certain sectors (legal, medical, etc.) or for languages that are poorly represented. This lack of data limits the performance of the models.
NER models can integrate biases present in training data (gender, origin, sector...). They are also sensitive to typos, oral errors or to infrequent formulations, which weakens their use in production.
The combined use of semantic embeddings and fuzzy matching considerably improves robustness, by making it possible to detect matches between close strings

In addition, modern techniques for shortlisting entities via similarity scoring, then validation by prompt, provide greater reliability than traditional machine learning models, especially in rich and ambiguous business environments.
The Named Entity Recognition is now part of documentary solutions much more advanced.
This is particularly the case for OCR Smart, which are part of the wider field ofIntelligent Document Processing (IDP).
Far beyond simply reading text, these tools use advanced technologies such as computer vision, natural language processing (NLP) or even named entity recognition (NER) to automatically extract structured information with high added value.
.gif)
They allow various documents to be analyzed accurately, such as:
Solutions like Koncile are based on a combination of complementary technologies to offer reliable, contextualized and immediately usable extraction:
By combining linguistic vision, statistics and understanding the context, NER is at the heart of automated document processing chains.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


