


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
June 19, 2026
5 minutes
Le Named Entity Recognition (NER) permet d’identifier automatiquement les informations clés dans un texte, comme les noms, dates ou montants. Découvrez comment elle fonctionne et pourquoi elle est devenue indispensable dans les projets d’automatisation documentaire.
Envie de comprendre comment extraire automatiquement les informations essentielles d’un texte ? Découvrez comment la NER transforme vos documents en données, prêtes à être exploitées.
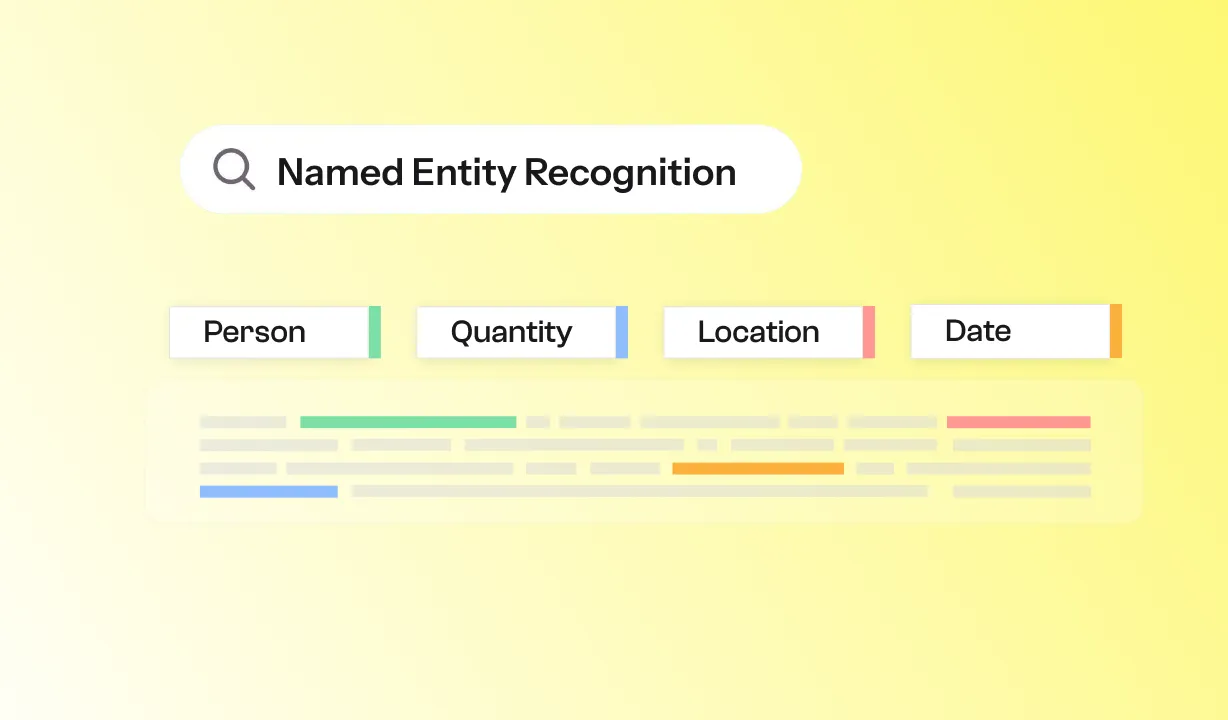
Le Named Entity Recognition (NER), ou reconnaissance d'entités nommées, est une technologie issue du traitement automatique du langage naturel (NLP).
Elle permet d’identifier automatiquement, dans un texte brut, des éléments clés comme:
Concrètement, le NER repose sur deux étapes principales :
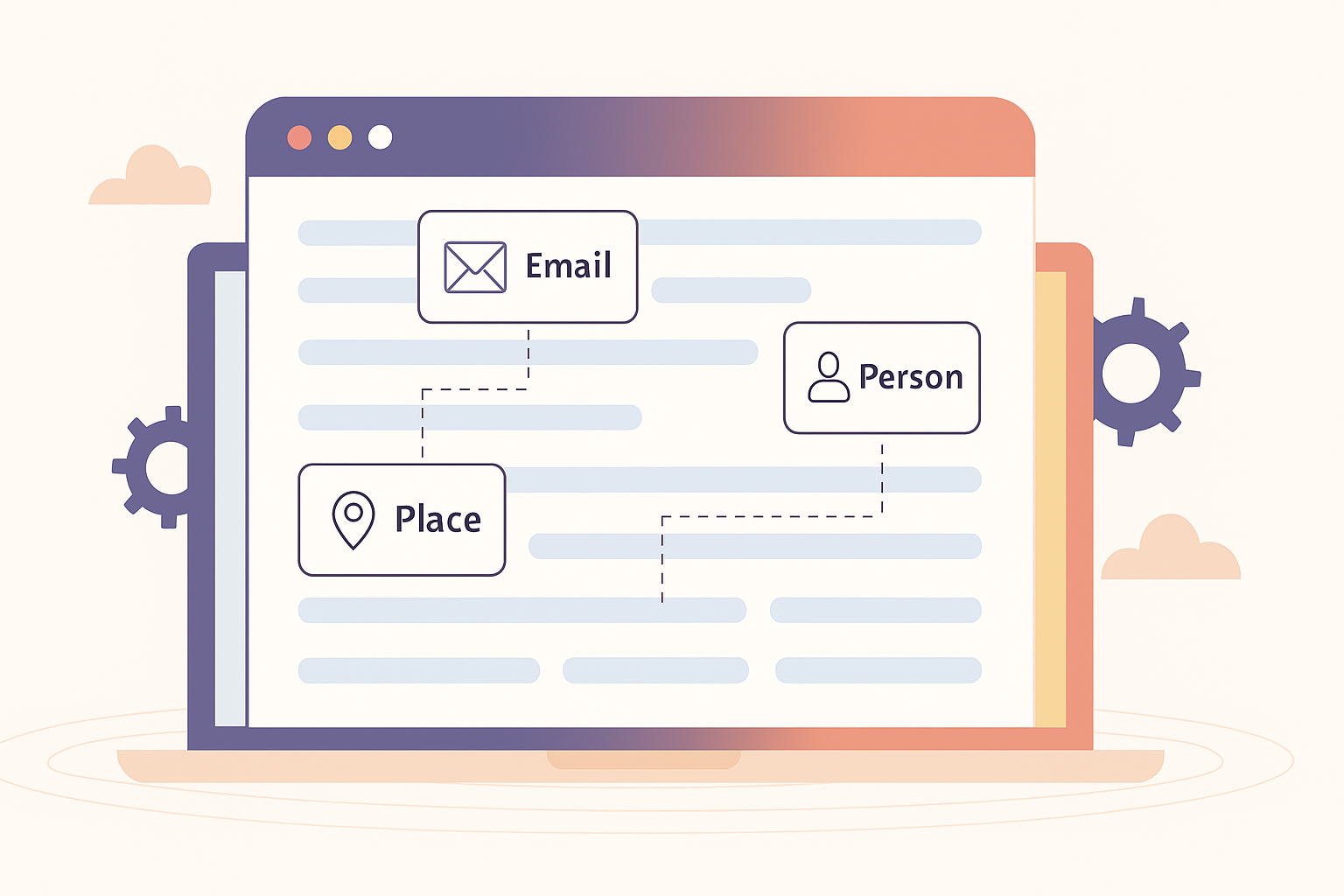
Historiquement, les premiers systèmes de NER reposaient sur des règles simples ou du fuzzy matching, consistant à comparer des chaînes de caractères avec des listes de référence en tolérant de petites différences (accents, fautes de frappe, abréviations…).
Ces approches, bien qu’efficaces dans certains cas, manquaient de robustesse et de précision dans des contextes variés ou bruités. Elles ont depuis été largement enrichies par des méthodes plus avancées, notamment par apprentissage profond et embeddings sémantiques.
Lorsqu’elle est bien déployée, la NER apporte des bénéfices concrets dans de nombreux contextes métiers :
Ce processus de Named Entity Recognition suit une suite d'étapes structurées, combinant des techniques linguistiques, statistiques et d’apprentissage automatique.
Voici les principales phases du fonctionnement du NER :
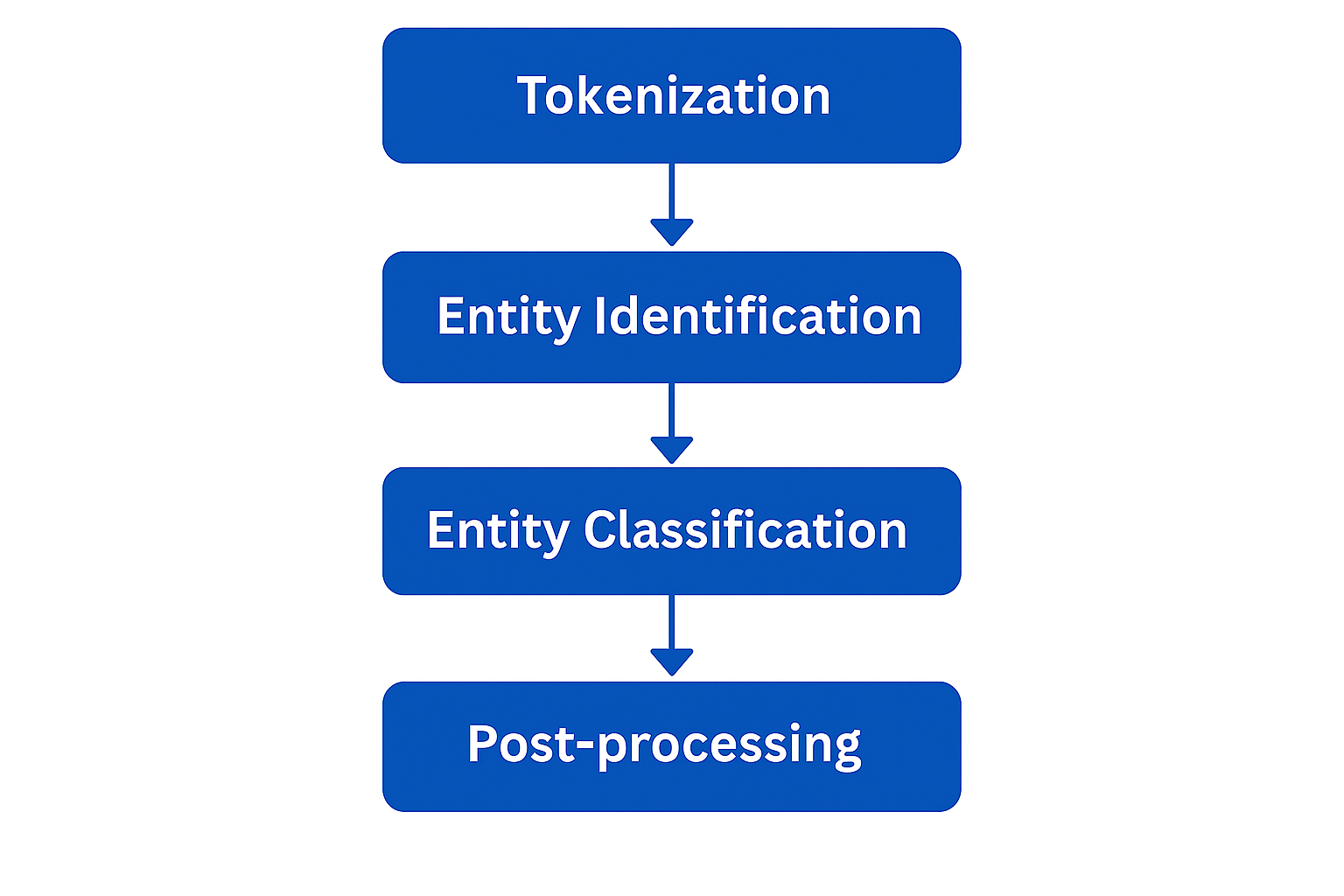
Tout commence par la tokenisation, qui consiste à découper le texte brut en unités élémentaires appelées tokens : mots, signes de ponctuation, dates, chiffres… Cette segmentation permet de préparer le terrain pour les étapes suivantes d’analyse linguistique.
Par exemple, la phrase :
.webp)
sera segmentée en :
La deuxième étape consiste à identifier les groupes de mots qui pourraient correspondre à des entités nommées. Cette détection repose sur :
L’objectif ici est de repérer dans le flux de texte les segments qui "ressemblent" à des entités.
Une fois les entités potentielles détectées, le système les classe dans des catégories prédéfinies.

Ce classement est généralement effectué par un modèle entraîné sur des jeux de données annotés. Des algorithmes comme les CRF (Conditional Random Fields) ou les réseaux neuronaux sont couramment utilisés pour cette tâche.
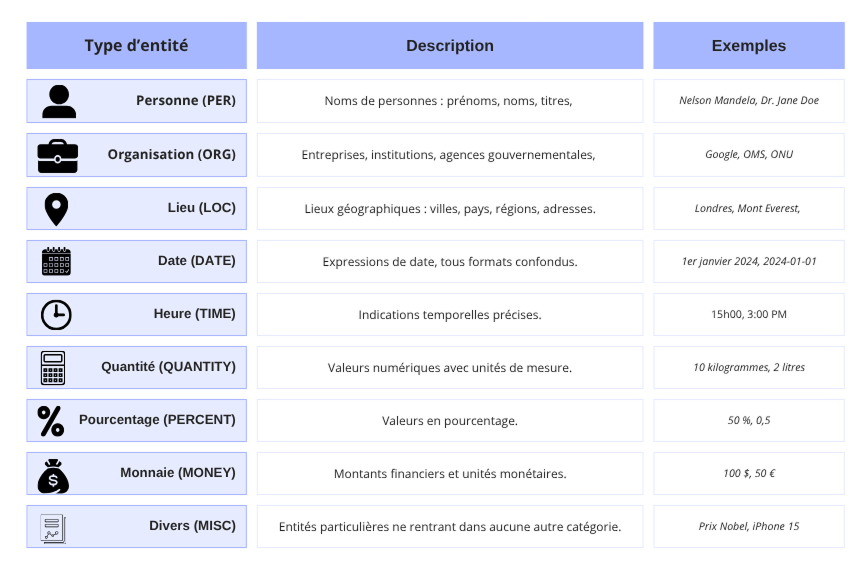
Comprendre ces catégories est essentiel pour exploiter pleinement les capacités de la NER. Voici un aperçu des types les plus fréquents :
Le contexte est essentiel pour garantir la précision du NER. Certains mots ou noms peuvent désigner différentes entités selon l’usage.
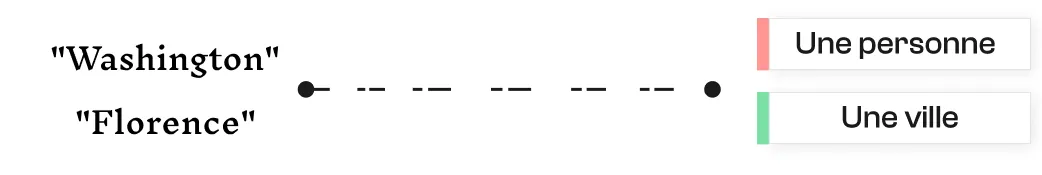
L’analyse contextuelle permet de lever ces ambiguïtés en tenant compte des mots voisins, de la syntaxe, voire de la structure du document. Elle permet aussi de gérer les entités imbriquées (par exemple : “Président Barack Obama des États-Unis” contient deux entités distinctes).
Avec les modèles modernes, l’élargissement du contexte d’analyse améliore significativement la désambiguïsation. Il est désormais possible d’utiliser un prompt pour comparer automatiquement une entité détectée à une liste de plusieurs milliers d’éléments (par ex. 100 000 noms d’entreprise), en short-listant les correspondances les plus proches.
Enfin, une phase de post-traitement vient affiner les résultats :
Plusieurs approches ont été développées pour mettre en œuvre efficacement la reconnaissance d'entités nommées (NER). Voici une explication détaillée des méthodes les plus courantes :
Les systèmes NER à base de règles fonctionnent à partir de modèles linguistiques définis manuellement. On y trouve notamment :
Les méthodes fondées sur l’apprentissage automatique consistent à entraîner un modèle statistique sur des exemples annotés pour qu’il apprenne à reconnaître les entités.
L’apprentissage profond a considérablement amélioré les performances de la NER, en s’appuyant sur des réseaux de neurones capables d’apprendre directement à partir du texte brut.
Les systèmes hybrides combinent plusieurs des méthodes précédentes pour tirer parti de leurs avantages respectifs. Par exemple :
De plus, certaines approches hybrides récentes combinent embeddings sémantiques et fuzzy matching pour calculer la similarité entre une entité détectée et des bases externes. Cela permet d’identifier intelligemment des correspondances même si les chaînes de caractères diffèrent.
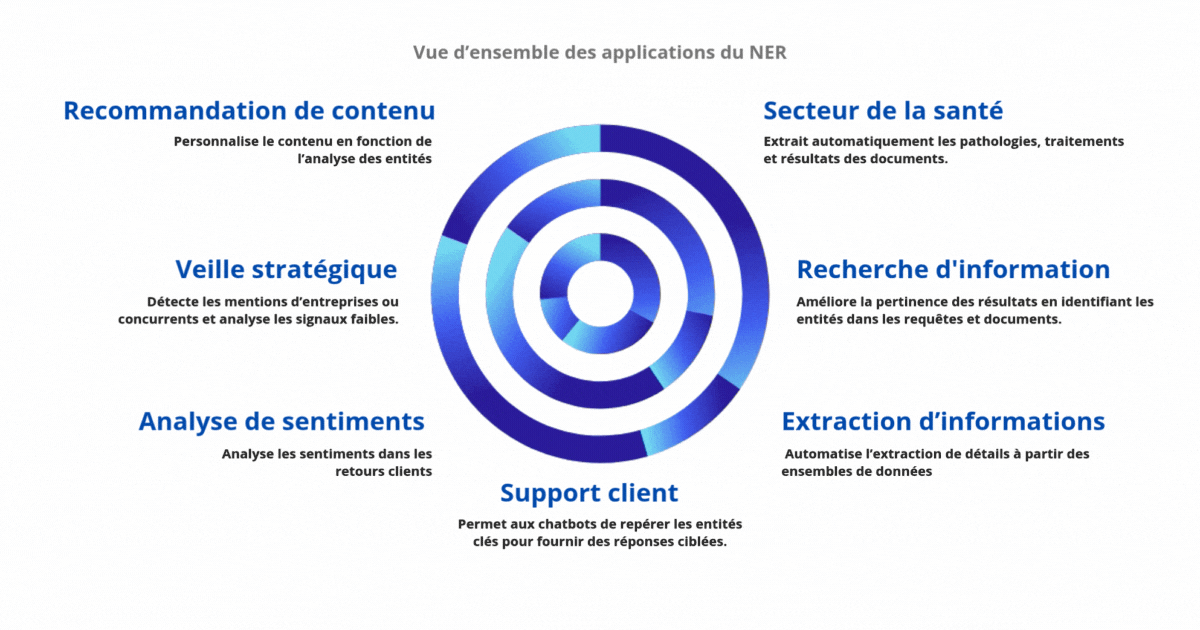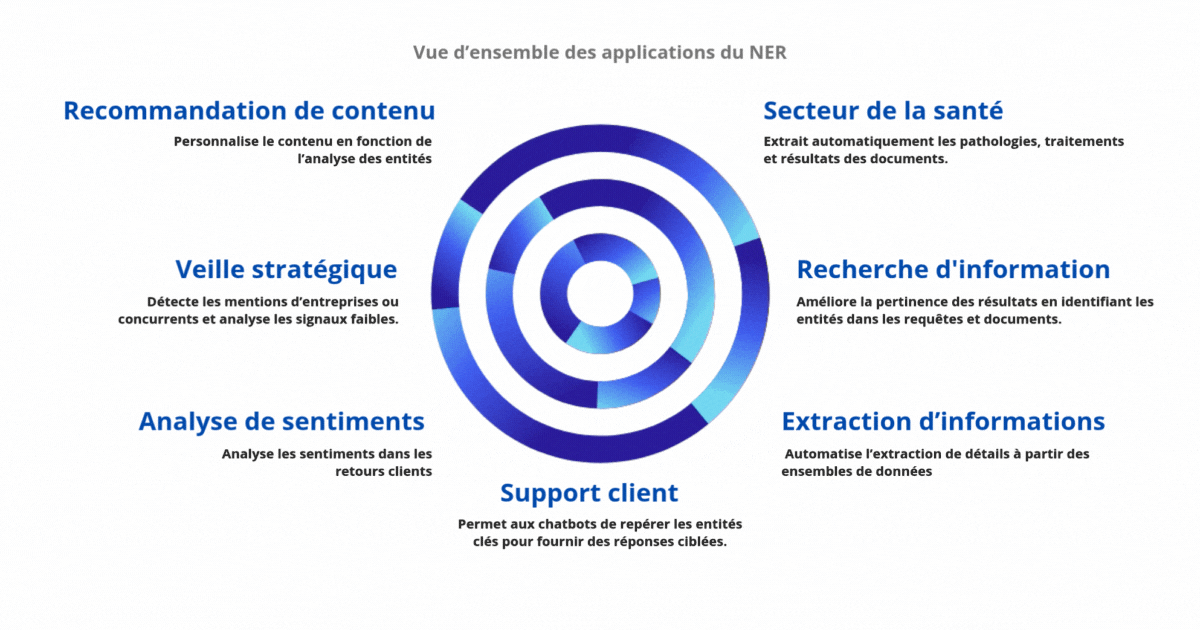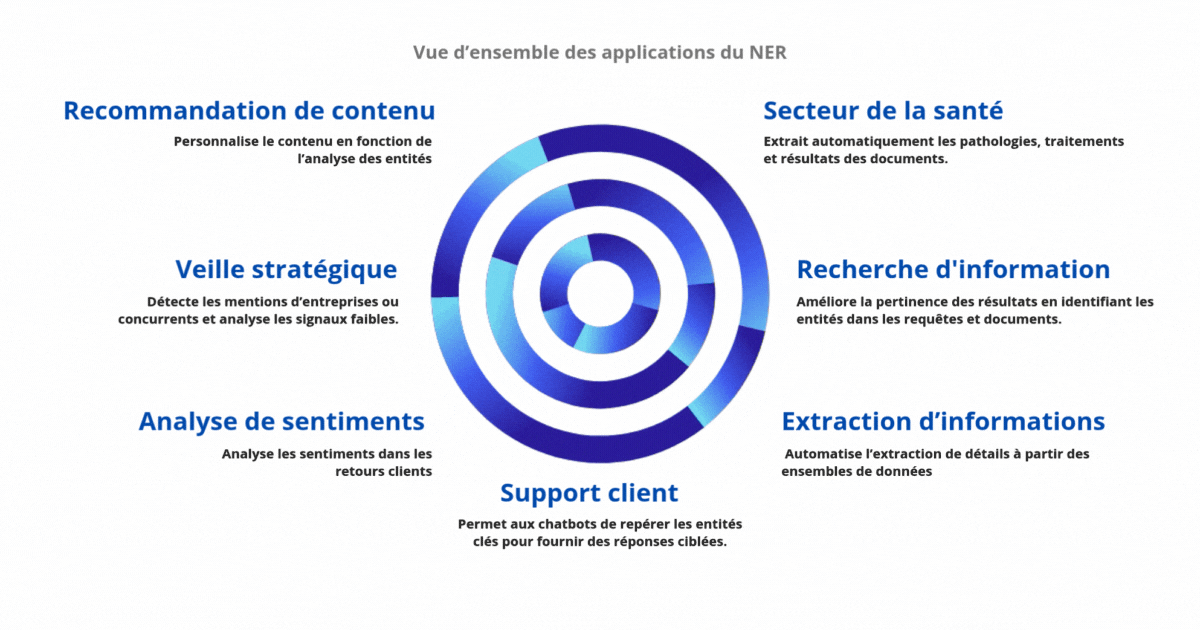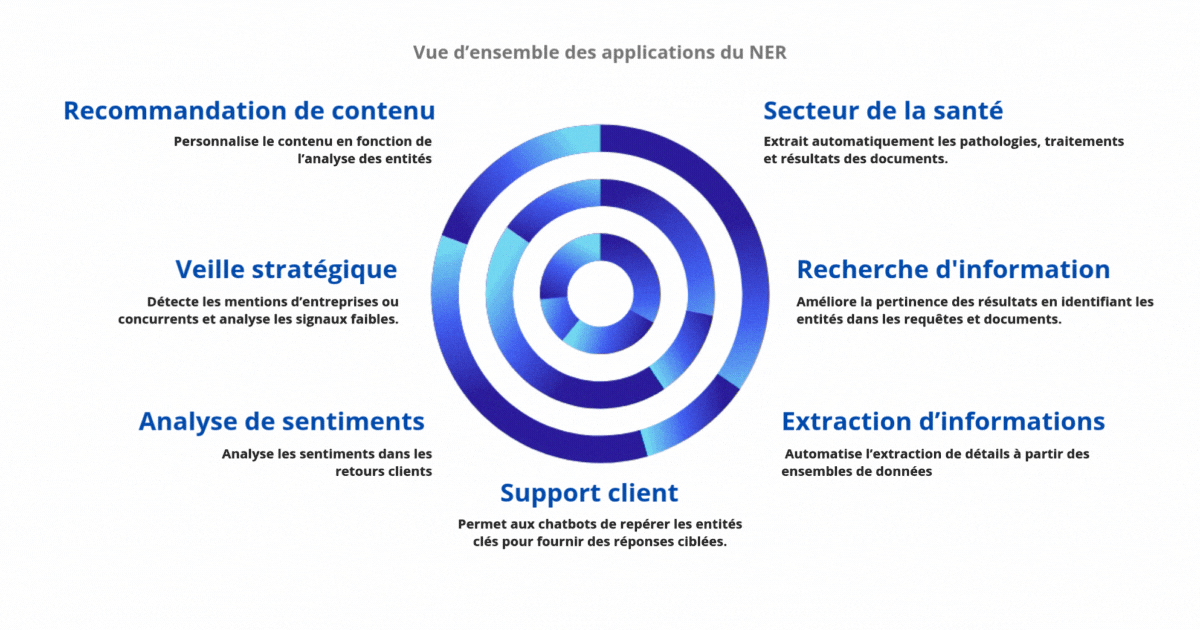
Pour garantir de bonnes performances et une précision optimale, la mise en œuvre de la NER doit suivre plusieurs étapes clés. Voici les recommandations essentielles :
Selon vos objectifs – intégration rapide, personnalisation avancée ou traitement à grande échelle – vous pouvez opter pour des bibliothèques open source ou des services cloud prêts à l’emploi.
Ces solutions sont particulièrement adaptées aux projets personnalisés et aux environnements de développement Python ou Java. Voici les trois plus populaires :
Réputée pour sa rapidité et sa simplicité d’intégration, spaCy est aujourd’hui l’une des bibliothèques NLP les plus utilisées en production. Elle propose des modèles pré-entraînés pour la NER sur plusieurs langues et permet un fine-tuning efficace. Son écosystème est bien documenté et largement maintenu par la communauté.
Développée par Zalando Research, Flair permet de combiner plusieurs modèles de deep learning (comme BERT, ELMo) pour améliorer la précision des entités extraites. Elle se distingue par son support multilingue et sa flexibilité dans les projets de recherche ou expérimentaux.
Outil robuste, particulièrement apprécié pour sa précision linguistique et son support multilingue. Développé en Java avec des wrappers Python disponibles, CoreNLP reste une référence académique et professionnelle, bien que plus exigeant en termes de ressources système.
Idéals pour les entreprises qui souhaitent intégrer rapidement la NER dans leurs systèmes, sans gérer l’entraînement ou l’hébergement des modèles.
Propose une extraction d’entités enrichie, avec catégorisation, score de pertinence et analyse syntaxique. Parfait pour les applications cloud à grande échelle.
Solution NER native dans l’écosystème AWS. Elle identifie automatiquement les entités (noms, lieux, dates…) et s’intègre facilement dans des architectures serverless ou des pipelines de traitement automatisés.
API complète orientée grands comptes, qui va au-delà de la NER. Elle permet également d’analyser les émotions, les relations sémantiques, les concepts ou les intentions, avec des niveaux de paramétrage avancés.
Malgré ses performances prometteuses, la NER reste confrontée à plusieurs limites qu’il est important d’anticiper pour garantir une mise en œuvre efficace.
Un même mot peut désigner plusieurs types d’entités selon le domaine ou l’usage courant.
Par exemple :
Sans désambiguïsation, les modèles risquent de mal étiqueter ces entités, surtout dans les contextes courts ou ambigus.
La signification d’une entité dépend aussi de sa position dans la phrase et des relations syntaxiques.
Prenons l’exemple suivant :

Ici, “Renault” est bien une organisation.
Mais dans :
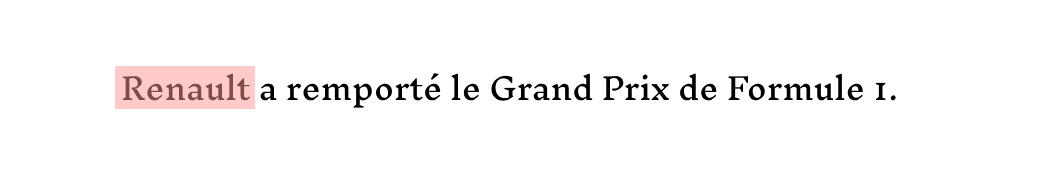
Le même mot est associé à une écurie sportive, et non à l’entreprise automobile dans son sens strict.
Les modèles modernes comme BERT ou RoBERTa, entraînés sur des contextes bidirectionnels, sont capables de capturer ces nuances pour améliorer la classification.
Les langues présentent des différences de syntaxe, d’usage des majuscules ou de formats d’entités. Certaines langues n’ont pas de conventions claires pour les noms propres. La NER doit s’adapter à ces variations, souvent en utilisant des modèles multilingues ou entraînés langue par langue.
L’apprentissage supervisé exige des corpus annotés, souvent indisponibles dans certains secteurs (juridique, médical…) ou pour des langues peu représentées. Ce manque de données limite la performance des modèles.
Les modèles NER peuvent intégrer des biais présents dans les données d’entraînement (genre, origine, secteur…). Ils sont également sensibles aux fautes de frappe, à l’oral ou à des formulations peu fréquentes, ce qui fragilise leur usage en production.
L'utilisation combinée d’embeddings sémantiques et de fuzzy matching améliore considérablement la robustesse, en permettant de détecter des correspondances entre chaînes proches

De plus, les techniques modernes de shortlisting d’entités via scoring de similarité, puis validation par prompt, apportent une fiabilité supérieure à celle des modèles de machine learning classiques, notamment dans des environnements métier riches et ambigus.
Le Named Entity Recognition s’inscrit aujourd’hui dans des solutions documentaires bien plus avancées.
C’est notamment le cas des OCR intelligents, qui s’inscrivent dans le champ plus large de l’Intelligent Document Processing (IDP).
Bien au-delà de la simple lecture de texte, ces outils exploitent des technologies avancées comme la vision par ordinateur, le traitement du langage naturel (NLP) ou encore la reconnaissance d’entités nommées (NER) pour extraire automatiquement des informations structurées à forte valeur ajoutée.
.gif)
Ils permettent d’analyser avec précision des documents variés, tels que :
Des solutions comme Koncile reposent sur une combinaison de technologies complémentaires pour offrir une extraction fiable, contextualisée et exploitable immédiatement :
En combinant vision linguistique, statistiques et compréhension du contexte, la NER s’inscrit au cœur des chaînes de traitement automatisé des documents.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


