


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité
.webp)
Dernière mise à jour :
June 19, 2026
5 minutes
Comment savoir si deux enregistrements parlent du même client, du même fournisseur ou du même produit ? Dans cet article, découvrez comment fonctionne le data matching, les techniques clés, les outils du marché, ainsi que de nombreux cas d’usage concrets pour tirer le meilleur parti de vos données.
Le data matching permet de recouper, unifier et fiabiliser vos données dispersées. Dans cet article complet, explorez les techniques avancées (fuzzy matching, machine learning…), découvrez les outils adaptés à chaque besoin et plongez dans des cas d’usage concrets pour automatiser et optimiser vos traitements de données.
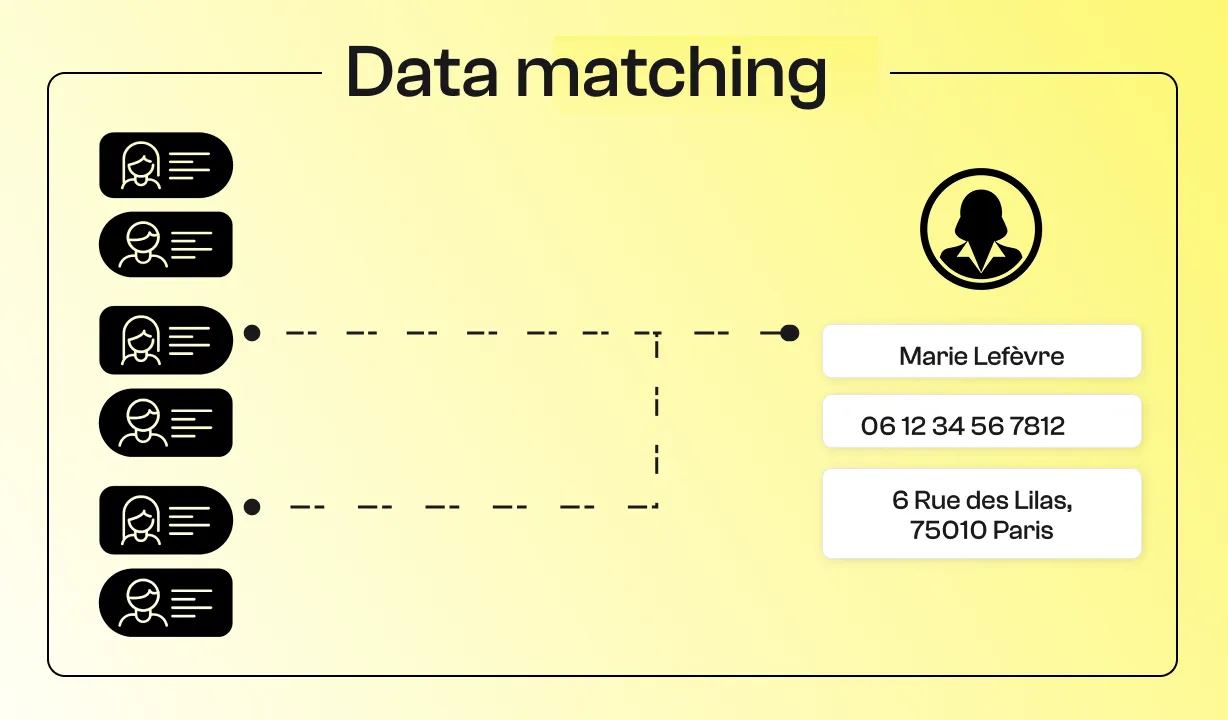
Le data matching, ou rapprochement de données, consiste à comparer des ensembles de données pour identifier celles qui se réfèrent à la même entité réelle (individu, entreprise, produit, etc.).
Il s’agit concrètement de déterminer si deux enregistrements issus de sources différentes correspondent à la même chose. Ce procédé permet de détecter des doublons dans une base ou de lier plusieurs bases ne partageant pas d’identifiant commun.
Sans data matching, ces doublons ou fragments passent inaperçus, nuisant à la qualité des données.

Plusieurs techniques de matching existent, adaptées à différents contextes. Elles peuvent être combinées pour de meilleurs résultats.
Voici les principales :
Le matching exact compare des données à l’identique. Deux valeurs doivent être rigoureusement les mêmes pour être reconnues comme un match. C’est simple et fiable si les données sont parfaitement normalisées (identifiants uniques, codes clients…).
Mais à la moindre variation (coquille, accent, abréviation), la correspondance échoue. Exemple : “ACME Corporation” ≠ “ACME Corp.”.
➡️ Utile sur données propres, mais trop rigide seul.
Le fuzzy matching compare les valeurs en calculant un score de similarité. Si ce score dépasse un seuil (ex. 80 %), on considère qu’il y a correspondance.
Il gère bien fautes, abréviations, accents ou variations mineures : “Société Générale” ≈ “Societe Generale”.
➡️ Souple et performant, mais nécessite un bon réglage pour éviter les faux positifs.
Cette méthode combine plusieurs critères (nom, email, date…) avec des poids pour estimer une probabilité globale de correspondance.
Même si aucune donnée n’est identique à 100 %, un score cumulé peut suffire à valider un match.
➡️ Très adapté aux données imparfaites, mais plus complexe à configurer.
Le matching hybride combine les approches précédentes : exact, flou, probabiliste… On applique les règles les plus strictes d’abord, puis les méthodes plus souples en cas d’échec.
➡️ Équilibre entre précision et couverture, souvent utilisé en entreprise.
On peut aussi entraîner un modèle à détecter les correspondances, à partir d’exemples étiquetés (match / non-match).
Techniques courantes : classification, clustering, réseaux de neurones.
➡️ Très performant sur des données complexes, mais nécessite des données d’entraînement et une supervision.
Le data matching est devenu indispensable et répond à un besoin très concret : relier, fiabiliser et unifier des informations issues de sources multiples pour en tirer une valeur réelle.
Plus qu’une simple mise en correspondance, c’est une étape clé pour assurer la qualité des données et leur bon usage au quotidien.
Un projet de data matching réussi repose sur une succession d’étapes rigoureuses. Chaque phase joue un rôle précis pour garantir des correspondances fiables entre les enregistrements.

Première étape incontournable : le nettoyage des données.
On supprime les caractères inutiles, on corrige les erreurs évidentes et on homogénéise les formats (ex. : majuscules, accents, ponctuation). Cette phase vise à éliminer les biais qui pourraient fausser les correspondances.
Les champs sont normalisés selon un format commun pour faciliter la comparaison.
Par exemple, toutes les dates peuvent être converties en format ISO (AAAA-MM-JJ), les adresses en notation postale standard, ou les numéros de téléphone en format international.
Pour éviter de comparer chaque ligne avec toutes les autres, on crée des clés de recherche (ou “blocs”).
Ces clés, générées à partir de champs combinés (ex. : code postal + première lettre du nom), permettent de limiter les comparaisons à des groupes cohérents et d’accélérer le processus.
C’est le cœur du matching. Les algorithmes comparent les champs sélectionnés selon différentes méthodes :
Chaque paire reçoit un score ou un niveau de confiance.
On définit un seuil de similarité pour considérer deux fiches comme correspondantes.
Ce seuil dépend des cas d’usage :
Il peut être ajusté au fil du temps selon les retours utilisateurs ou le niveau de tolérance souhaité.

Le marché propose un large éventail de solutions pour automatiser le data matching, selon les types de données, les besoins fonctionnels et les ressources disponibles.
Solutions spécialisées en qualité de données - exemples : Data Ladder, WinPure, Informatica
Ces outils sont conçus pour des projets de consolidation de données à grande échelle. Ils proposent des interfaces no-code pour configurer des règles de correspondance (exacte ou fuzzy), ajuster les seuils de similarité, visualiser les doublons et valider les appariements manuellement.
Outils open source ou bibliothèques techniques - exemples : OpenRefine, Dedupe.io, bibliothèques Python
Destinés aux utilisateurs techniques, ces outils permettent de créer des traitements personnalisés, adaptés à des cas complexes ou à forte contrainte métier. Ils offrent une grande flexibilité, mais nécessitent des compétences en programmation ou en data engineering.
Modules intégrés dans des logiciels métiers - exemples : CRM (Salesforce, HubSpot), ERP, outils RH ou comptables
De nombreux logiciels intègrent des fonctions natives de déduplication ou de fusion de contacts. Ces options sont généralement faciles à activer depuis l’interface d’administration, mais restent limitées en termes de paramétrage avancé ou de logique de matching complexe.
Outils d’automatisation de workflows - exemples : Make, Zapier, N8N
Ces plateformes permettent d’automatiser des flux de données entre différents systèmes, et d’ajouter des étapes de matching lors des synchronisations (ex. : entre une base e-mail et un CRM). Elles sont particulièrement utiles pour les équipes non techniques ou les cas simples à modérer.
Solutions combinant extraction et matching (OCR + matching) - exemples : Koncile
Pour de nombreux cas d’usage (comptabilité, RH, KYC…), les données à apparier se trouvent dans des documents PDF ou scannés. Les solutions comme Koncile intègrent un moteur OCR pour extraire automatiquement les champs pertinents, les normaliser, puis les rapprocher des données existantes à l’aide de techniques de matching exact ou flou.
Cela permet d’automatiser des tâches manuelles chronophages tout en sécurisant la qualité des correspondances.
Malgré ses avantages, le data matching présente plusieurs défis à anticiper pour garantir sa fiabilité et sa pertinence :
Mettre en œuvre un data matching fiable ne dépend pas uniquement des outils, mais aussi des méthodes utilisées. Voici les pratiques à privilégier pour améliorer la précision, limiter les erreurs et pérenniser vos résultats :
Ces bonnes pratiques, combinées à une connaissance fine de vos données et à un bon accompagnement métier, vous permettront d’exploiter tout le potentiel du data matching de manière fiable et durable.
Le data matching joue un rôle transversal : il facilite la cohérence des bases, améliore la qualité de la donnée et soutient l’analyse inter-systèmes dans tous les métiers où l'information est critique.
Le data matching s’applique d’ailleurs dans de nombreux secteurs dès qu’il faut nettoyer, recouper ou fiabiliser des données issues de sources multiples. Voici quelques exemples concrets par domaine :
Le choix d’un outil de data matching dépend avant tout de votre contexte métier, de vos volumes de données et du niveau de complexité des correspondances à effectuer. Voici les principaux critères à prendre en compte pour sélectionner une solution adaptée :
Un bon choix repose donc sur l’évaluation fine de vos cas d’usage réels, associés à une vision claire des objectifs (gain de temps, amélioration qualité, automatisation, conformité…). N’hésitez pas à tester plusieurs options ou à opter pour une solution modulaire capable de s’adapter à vos évolutions.
C’est l’indicateur clé de performance d’un algorithme de correspondance.
Le taux de matching IA mesure le pourcentage de correspondances correctement détectées par une solution utilisant l’intelligence artificielle. Il reflète la capacité du système à reconnaître automatiquement les doublons ou les entités similaires dans vos bases de données.
C’est le processus qui permet de rassembler en un seul enregistrement toutes les données dispersées sur une même entité. En identifiant et en fusionnant les doublons issus de différentes sources, cette intégration crée une fiche unique, cohérente et exploitable. C’est une étape clé pour obtenir une base client unifiée, cohérente et exploitable.
Le data matching sert à réunir les données qui parlent de la même chose, même si elles sont dispersées ou mal formatées. Le data mining, lui, cherche à comprendre ce que ces données peuvent révéler une fois qu’elles sont bien organisées. Le premier rapproche les informations, le second en tire des enseignements.
Pas totalement, mais il peut s’en approcher.
Quand un identifiant unique manque, le data matching permet de simuler un repérage fiable en croisant plusieurs champs. Cela offre une solution alternative pour reconnaître une entité, tout en gardant une certaine marge d’incertitude.
Les seuils varient selon le niveau de fiabilité attendu. En général, un seuil autour de 90 % permet d’obtenir des correspondances fiables tout en limitant les erreurs. Pour des cas moins critiques, un seuil de 80 % peut suffire. L’idéal est de l’ajuster en fonction de vos données et de vos objectifs métiers.
En donnant aux utilisateurs les moyens de corriger, valider ou signaler les erreurs directement dans l’outil. Leurs retours permettent d’ajuster les seuils de confiance et d’améliorer le système au fil du temps. C’est cette interaction qui rend le matching plus fiable, plus intelligent, et mieux adapté à vos données.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Tristan Thommen conçoit et déploie les briques technologiques qui transforment des documents non structurés en données exploitables. Il allie IA, OCR et logique métier pour simplifier la vie des équipes.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


