


.webp)
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dernière mise à jour :
June 19, 2026
5 minutes
Le fuzzy matching permet de rapprocher automatiquement des données même lorsqu’elles ne sont pas parfaitement identiques. C’est un levier puissant pour automatiser vos workflows documentaires malgré les erreurs, variantes ou fautes de frappe.
Découvrez comment le fuzzy matching améliore la qualité de vos données et automatise le rapprochement documentaire malgré les erreurs ou variations.
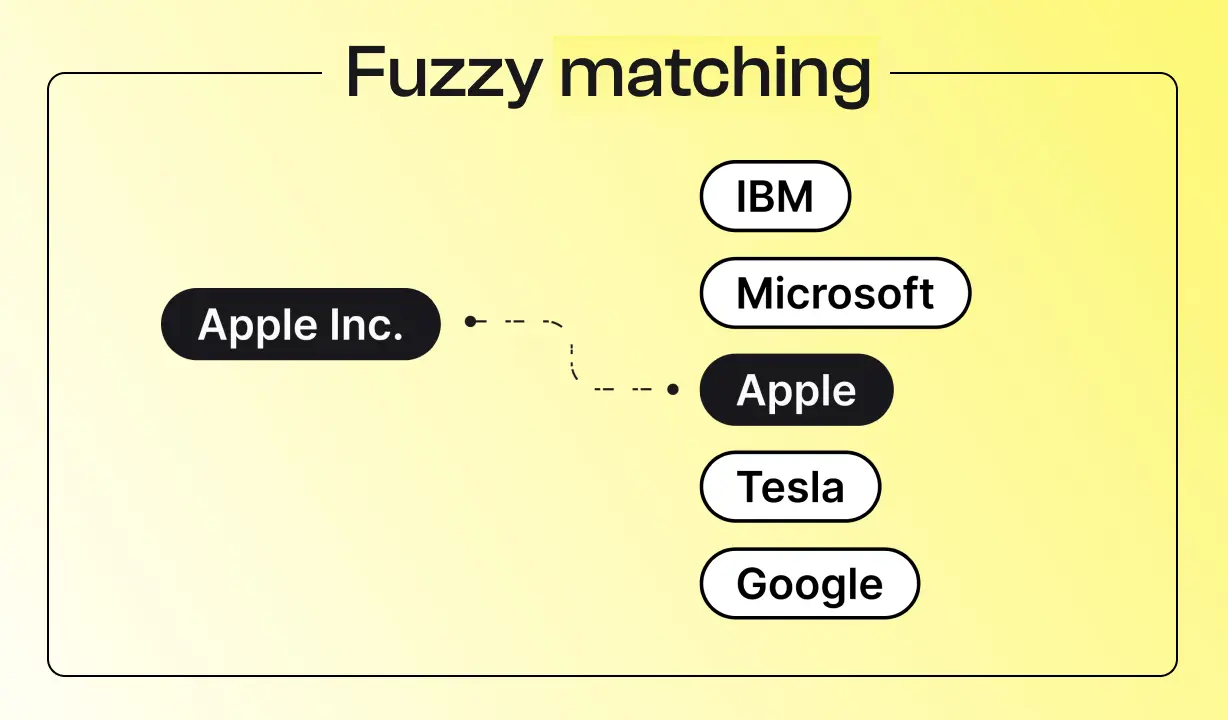
Dans de nombreux processus métiers, il est devenu essentiel de croiser et rapprocher des informations qui ne correspondent pas exactement à l’identique. Prenons l’exemple d’une facture fournisseur : le libellé ou le nom de l’entreprise qu’elle contient peut différer légèrement de celui enregistré dans votre base de données.
C’est précisément là qu’intervient le fuzzy matching, ou correspondance floue en français. Cette approche consiste à identifier des correspondances entre des données similaires mais non strictement identiques, afin de répondre à une question clé :
“Ces deux éléments sont-ils suffisamment proches pour être considérés comme équivalents ?”
Dans cet article, nous allons définir de manière claire ce qu’est le fuzzy matching et explorer ses applications concrètes. L’objectif : améliorer la fiabilité et automatiser le traitement de vos documents métiers (factures, contrats, données clients ou fournisseurs…), notamment en complément de l’OCR et de vos outils ou systèmes existants.
Le fuzzy matching est une méthode de recherche de correspondances approximatives.
Au lieu d’exiger une égalité caractère pour caractère, un algorithme de fuzzy matching calcule un score de similarité entre deux chaînes de caractères ou deux enregistrements.
Si ce score dépasse un certain seuil de confiance prédéfini (par exemple 85%), alors les deux éléments sont considérés comme un match, c’est-à-dire comme représentant la même information. Dit autrement, la correspondance floue évalue dans quelle mesure une correspondance est vraie ou fausse plutôt que de fonctionner en tout ou rien.
Concrètement, ce type d’algorithme mesure le nombre de modifications nécessaires pour passer d’une chaîne à une autre – on parle de distance d’édition. Moins il faut de changements, plus les deux chaînes se ressemblent.
Par exemple, pour transformer “INV-1000” en “INV1000” (sans le tiret), il suffit d’une suppression de caractère : la similarité sera donc très élevée. En revanche, pour passer de “FACTURE 2023” à “FACTURE 2024”, il y a un changement de chiffre, ce qui indique deux références différentes malgré leur apparence proche. Grâce à ces calculs, le fuzzy matching sait reconnaître que “ACME Corporation” et “ACME Corp.” font référence à la même entité, car le score de similarité sera largement au-dessus du seuil fixé (par exemple ~92% de similarité) . De même, “Jean Dupont” vs “Jean Dupond” (une lettre différente) ou “Société Générale” vs “Societe Generale” (accent manquant) pourront être rapprochés via la correspondance floue, alors qu’une correspondance exacte les traiterait comme des valeurs distinctes.
Dans la théorie informatique classique, une condition de comparaison renvoie soit vrai soit faux. Deux valeurs doivent être parfaitement identiques pour être reconnues comme équivalentes. Or, la réalité des données métiers est beaucoup plus nuancée. Les informations extraites de documents proviennent souvent de sources variées (fournisseurs différents, systèmes multiples) et comportent des variations inévitables. Un même fournisseur peut être appelé “ABC Ltd” dans la base Achats et “A.B.C. Limited” sur une facture ; un produit peut être abrégé différemment d’un document à l’autre ; sans parler des erreurs de saisie ou des fautes de frappe, ni des approximations introduites par l’OCR lors de la numérisation de documents papier (par exemple, confondre la lettre “O” avec le chiffre “0”). En bref, les données du monde réel sont rarement parfaitement uniformes .
Sans recours au fuzzy matching, le moindre écart de format ou d’orthographe peut faire échouer un rapprochement automatisé. Un système strict risquerait de rejeter une facture simplement parce qu’un accent manque au nom du client, ou de ne pas retrouver un bon de commande parce qu’un tiret a été omis dans la référence. Ces petits écarts brisent les flux d’automatisation et forcent du traitement manuel . À l’échelle d’une entreprise traitant des milliers de documents, s’appuyer uniquement sur des correspondances exactes n’est plus viable : cela génèrerait trop d’exceptions à gérer manuellement, rallongeant les délais de traitement et introduisant un risque d’erreurs. C’est pourquoi les approches de correspondance floue sont devenues essentielles pour apporter de la flexibilité et de la résilience dans les workflows documentaires.
L’OCR (Reconnaissance Optique de Caractères) est souvent la porte d’entrée de l’automatisation documentaire : il transforme des documents scannés (factures papier, PDF numérisés, contrats signés à la main, etc.) en texte exploitable par les systèmes numériques. Cependant, l’OCR n’est pas infaillible – il peut introduire des petites erreurs de lecture. Par exemple, un “0” (zéro) interprété à tort comme “O” (lettre O), ou un “l” (L minuscule) confondu avec un “1”. Combiner l’OCR avec du fuzzy matching, c’est assurer que ces écarts mineurs ne compromettent pas l’automatisation. Le fuzzy matching va tolérer les petites différences issues de l’OCR et tout de même retrouver la correspondance la plus probable dans vos données de référence.
Prenons un exemple concret : une facture fournisseur numérisée contient le texte “Bon de commande : CM-4567” alors que dans votre système ERP, le bon de commande est enregistré comme “BCM-4567”. Si on se limitait à une recherche exacte, le champ extrait par l’OCR (“CM-4567” amputé d’une lettre) ne correspondrait à rien et la facture serait mise en exception manuelle. En revanche, un algorithme de fuzzy matching va détecter que “CM-4567” est très proche de “BCM-4567” (une différence d’un caractère) et pourra retrouver le lien avec le bon de commande approprié. Ainsi, l’alliance OCR + fuzzy matching sécurise vos workflows : l’OCR fournit les données brutes et la correspondance floue les fiabilise en rattrapant les petites discordances. Dans le contexte du contrôle de factures, cette combinaison est un véritable duo gagnant pour automatiser le rapprochement 3 Way Match (commande, réception, facture) de manière fiable.
Au-delà de l’OCR, le fuzzy matching joue un rôle de pont intelligent entre vos documents et vos systèmes métier. Une fois les données extraites d’un document, encore faut-il les rattacher aux bons enregistrements dans vos bases (base fournisseurs, base clients, catalogue produits, etc.). C’est ici que la correspondance floue déploie tout son potentiel. Elle permet d’apparier des éléments issus d’un document avec leur référence dans votre système, même si l’écriture diffère légèrement .
Par exemple, supposons qu’un bon de commande dans votre ERP contient un article décrit comme “Disque Dur Externe 1To” tandis que la facture du fournisseur le désigne comme “Disque externe 1 To USB”. Un moteur de fuzzy matching saura reconnaître qu’il s’agit du même produit malgré la variation de libellé, et ainsi l’associer automatiquement. De même, le nom d’un client sur un contrat scanné (“Hôtel Le Grand Bleu”) pourra être rapproché de votre fiche client (“Le Grand Bleu Hotel”) même si l’ordre des mots ou la langue diffèrent légèrement. La correspondance floue vient donc enrichir vos workflows documentaires en faisant le lien entre le non-structuré (le texte présent dans les documents) et le structuré (vos données métiers) de façon transparente. Cela réduit drastiquement le besoin de recherche manuelle ou de re-saisie lorsqu’un intitulé ne “colle pas” exactement : le système retrouve pour vous la bonne référence. En somme, le fuzzy matching agit comme un interprète entre vos documents et vos bases de données, éliminant les frictions dues aux divergences de formats ou de terminologie.
Adopter le fuzzy matching dans vos processus documentaires, c’est d’abord fiabiliser vos contrôles automatisés. En effet, grâce à la correspondance floue, les systèmes détectent les véritables écarts et anomalies, sans se laisser perturber par des différences purement formelles ou bénignes. Cela signifie que vos règles d’automatisation (par exemple, la vérification qu’une facture correspond à une commande) déclencheront moins de fausses alertes. Les petites divergences qui n’affectent pas le fond (orthographes alternatives, formats de date différents, majuscules/minuscules, etc.) seront reconnues comme équivalentes et n’entraîneront pas un rejet à tort du document. Des études montrent que les entreprises utilisant le fuzzy matching constatent un taux d’automatisation plus élevé grâce à la réduction de ces faux non-conformités . En pratique, vos workflows “matchent” plus de documents du premier coup, sans intervention humaine, ce qui renforce la confiance dans votre système. Les gestionnaires peuvent s’appuyer sereinement sur les contrôles automatiques, sachant qu’ils ne passeront pas à côté d’une correspondance juste à cause d’une variation mineure de texte.
Qui dit contrôles plus fiables dit aussi moins d’exceptions manuelles à traiter. Le fuzzy matching contribue directement à diminuer le volume de cas où l’automate n’arrive pas à trancher et sollicite une vérification humaine. En permettant au système de reconnaître qu’un document X fait bel et bien référence à l’entité Y de la base, on évite de basculer ce document en traitement manuel pour “non correspondance”. Pour votre organisation, cela se traduit par un gain de temps significatif et une réduction de la charge de travail pour vos équipes. Plutôt que de passer des heures à résoudre des écarts qui n’en sont pas (du type “Ah, c’était juste une faute d’orthographe”), vos collaborateurs peuvent se concentrer sur de vraies anomalies ou des tâches à plus forte valeur ajoutée. Par ailleurs, en réduisant les ressaisies manuelles et les comparaisons fastidieuses de documents, on diminue mécaniquement le risque d’erreurs humaines dans le processus. Moins d’interventions manuelles, c’est moins d’occasions d’introduire une erreur de saisie ou de jugement. Au final, le fuzzy matching contribue à des processus plus fluides, plus rapides, et sans erreur évitable. Les validations de documents s’effectuent plus vite, les délais de paiement fournisseurs peuvent s’en trouver raccourcis, et vos équipes achats/finance gagnent en efficacité au quotidien .
Un bénéfice souvent sous-estimé du fuzzy matching est l’amélioration globale de la qualité des données de l’entreprise. En effet, en identifiant que deux écritures différemment libellées renvoient en réalité à la même entité, la correspondance floue aide à dédupliquer et à nettoyer les bases de données . Vos référentiels (fournisseurs, clients, articles, etc.) restent unis et cohérents, sans doublons dus à des variations d’orthographe ou de format. Par exemple, si un même fournisseur a été enregistré deux fois sous des noms légèrement divergents, un algorithme de fuzzy matching pourra signaler cette redondance et faciliter la fusion des fiches en double. De même, lors de l’intégration de nouvelles données, le système flou peut rattacher les nouvelles entrées à des enregistrements existants plutôt que de créer des duplicatas. Tout cela contribue à fiabiliser vos données maîtres.
Par ailleurs, le fuzzy matching peut servir à la normalisation des libellés. En rapprochant des termes proches, il permet de ramener différentes variantes à un libellé standard. Par exemple, il peut aider à uniformiser les adresses (reconnaître que “St.” et “Street” c’est la même chose, ou que “PARIS-75009” et “Paris 75009” représentent le même lieu), ou encore à harmoniser la manière dont un produit est nommé dans différents systèmes. Au final, vous obtenez des bases de données mieux organisées, facilitant les analyses et évitant les incohérences. Des données de qualité, ce sont des rapports plus fiables, une meilleure connaissance client/fournisseur, et une base solide pour déployer des projets avancés (pilotage par la donnée, IA, etc.). Le fuzzy matching est donc un investissement dans la qualité de votre patrimoine informationnel, avec des retombées positives à long terme.
Le cas d’usage le plus emblématique du fuzzy matching, dans le contexte de la comptabilité fournisseurs, est le rapprochement automatique des factures avec les bons de commande (et les réceptions) même lorsque les libellés ou références diffèrent légèrement. C’est le fameux « 3-way matching » dont la fiabilité peut être mise à mal par des divergences de texte. Grâce à la correspondance floue, votre système saura par exemple associer une ligne de facture libellée “Clavier sans fil DELUXE” avec une ligne de commande intitulée “Clavier Deluxe – sans fil”. De même, si la facture mentionne un numéro de commande “PO #100458” alors que votre ERP stocke “PO-100458” (avec un tiret), le fuzzy matching fera le lien automatiquement. L’entreprise gagne ainsi en rapidité de traitement : la facture est validée sans intervention manuelle, puisque le système a compris que, malgré la différence de présentation, les éléments correspondent bel et bien. Cela réduit aussi les litiges et échanges entre les équipes (comptabilité qui demande aux achats de vérifier tel écart, etc.), car moins de factures sont bloquées pour des détails insignifiants. En somme, le fuzzy matching rend le rapprochement factures-commandes plus tolérant aux variations, ce qui permet de fluidifier le processus de validation tout en maintenant un haut niveau de contrôle.
Dans la gestion des données de base (master data clients ou fournisseurs), le fuzzy matching s’avère précieux pour détecter des doublons qui passeraient autrement inaperçus. Par exemple, un même fournisseur peut figurer deux fois dans votre système : une fois comme “Transports Dupré SARL” et une autre fois comme “TRANSPORTS DUPRE”. Un œil humain ne fera pas forcément le rapprochement, surtout dans un annuaire de milliers d’entrées. Un algorithme de correspondance floue, en revanche, calculera que ces deux dénominations sont très similaires et pourra les signaler comme doublon potentiel. De même pour des clients : “Hôpital Saint Jean” vs “Hopital St-Jean” – malgré les accents manquants ou abréviations, le système identifiera probablement qu’il s’agit de la même entité. En intégrant cet outil dans vos processus, vous pouvez mettre en place des contrôles qui alertent lorsqu’un utilisateur crée une nouvelle fiche fournisseur/client dont le nom ressemble beaucoup à un existant. Cela vous aide à garder une base unie, à éviter les doublons qui faussent les analyses (par ex. consolidation des dépenses par fournisseur), et à prévenir des erreurs comme la création involontaire de deux comptes pour le même tiers. La détection de doublons par fuzzy matching peut aussi servir en audit pour identifier, par exemple, deux factures suspectes ayant presque le même numéro (signe possible de double facturation). Globalement, cet usage renforce la conformité et la transparence des données de l’entreprise.
Le fuzzy matching peut également être utilisé de manière proactive pour la correction automatique de données mal formatées ou avec des erreurs. Imaginons que dans une facture, le code produit “AB-1234” attendu ait été saisi ou reconnu OCR comme “AB 1234” (sans tiret) ou “A8-1234” (avec un 8 à la place du B dû à une mauvaise lecture). Un moteur de correspondance floue va comparer ces entrées à la liste des codes produits valides et trouver celui qui se rapproche le plus. S’il détermine que “A8-1234” est à 95% similaire à “AB-1234”, il pourra automatiquement corriger la référence ou suggérer la correction à l’utilisateur. Ce principe est le même que celui d’un correcteur orthographique intelligent : on cherche toutes les possibilités proches (à une ou deux lettres près) du terme inconnu, puis on choisit la correspondance la plus probable . Dans un contexte d’entreprise, cela se traduit par moins d’éléments non reconnus ou mal classés. Vos bases gagnent en exactitude car les petites fautes sont corrigées à la volée. Outre les codes produit, pensez aux adresses (corriger “Avenue du General De Gaulle” en “Avenue du Général De Gaulle” si la base de données officielle contient l’accent), aux références client (ajouter un zéro initial manquant sur un numéro de compte), etc. Le fuzzy matching apporte ici une sécurité : même si l’information entrée n’est pas parfaite, le système la ramène vers une valeur correcte ou cohérente. C’est particulièrement utile lors de la capture de données via OCR ou formulaires web, où l’on peut autocorriger ce qui a été mal saisi pour éviter les erreurs downstream.
Enfin, un autre cas d’usage courant du fuzzy matching est la normalisation des libellés et la mise en correspondance de référentiels différents. Dans les grandes organisations, on hérite souvent de multiples bases de données ou listes de valeurs pour des entités similaires, avec des conventions de nommage variables. La correspondance floue permet de rapprocher ces différentes variantes pour les uniformiser. Par exemple, votre base CRM marketing indique des secteurs d’activité en toutes lettres (“Industrie Pharmaceutique”) tandis que votre base ERP utilise des codes ou des abréviations (“Pharma” ou “Industrie Pharma.”). Plutôt que de harmoniser manuellement des milliers d’entrées, un algorithme peut regrouper celles qui se ressemblent et suggérer un libellé maître. De même, pour des données non codifiées comme les intitulés de prestations, articles ou intitulés de projets, le fuzzy matching peut aider à identifier que “Service support niveau 1” et “Support Niv.1” renvoient à la même catégorie et devraient être nommés de façon cohérente. Cette normalisation a un impact direct sur la qualité des analyses et des reportings : en parlant le “même langage” partout, on peut consolider les données sans doublons cachés. Pour l’opérationnel, c’est aussi un confort accru – on retrouve plus facilement l’information car on n’a pas à essayer plusieurs orthographes ou libellés pour une recherche. Le fuzzy matching sert donc de colle sémantique entre des bases disparates, facilitant les projets de migration de données ou de mise en place de référentiels uniques (Master Data Management). Vous obtenez au final des libellés clairs, homogènes, ce qui reflète une entreprise mieux organisée.
Si vous envisagez d’intégrer la correspondance floue dans vos outils, plusieurs critères de qualité sont à examiner pour choisir la bonne solution. Le premier est évidemment la précision de l’algorithme : il doit trouver un maximum de correspondances pertinentes tout en évitant les rapprochements hasardeux. Autrement dit, un bon moteur de fuzzy matching minimise aussi bien les faux négatifs (match manqués alors qu’ils auraient dû être faits) que les faux positifs (match réalisés à tort entre des éléments différents). Pour apprécier cela, vous pouvez tester l’outil sur un échantillon de vos données connues et évaluer s’il retrouve bien les liens attendus sans en créer de faux.
Un deuxième critère important est la paramétrabilité. Chaque contexte métier a ses particularités, et il est crucial de pouvoir ajuster le seuil de similarité selon vos besoins spécifiques . Un moteur qui permet de configurer, par exemple, un seuil à 90% pour les correspondances sensibles (codes critiques) et 80% pour d’autres champs, vous offrira une finesse de contrôle appréciable. De même, la possibilité de choisir ou de combiner différents algorithmes (distance de Levenshtein, Jaro-Winkler, correspondance phonétique pour les noms, etc.) est un plus, car aucune méthode unique ne convient à tous les types de données. Par exemple, pour des noms de personnes, un algorithme qui ignore les accents et considère les sons peut mieux fonctionner, tandis que pour des numéros ou des codes, la distance de Levenshtein est souvent efficace.
La performance et la scalabilité du moteur sont également à examiner. Sur de très larges volumes de données (des millions d’enregistrements à comparer), l’algorithme doit être optimisé pour rester rapide. Renseignez-vous sur la capacité de l’outil à indexer les données et à effectuer des recherches floues sans rallonger excessivement les temps de traitement. Certains moteurs tirent parti de technologies de bases de données avancées ou d’index de recherche pour accélérer les correspondances approximatives.
Enfin, considérez les aspects de prise en main et d’intelligence du moteur. Par exemple, l’outil fournit-il un score de similarité explicite et des informations sur pourquoi deux éléments ont été rapprochés (pour faciliter les vérifications) ? Propose-t-il un mode “apprentissage” où il s’améliore à partir des corrections validées par les utilisateurs (apprentissage supervisé) ? . Une solution de fuzzy matching de qualité industrielle offrira généralement une interface ou des API permettant d’examiner, de valider ou d’affiner les correspondances proposées, afin de garder le contrôle sur le processus.
Pour une mise en œuvre réussie du fuzzy matching, il convient d’anticiper quelques points de vigilance lors de l’intégration avec vos systèmes existants, tels que l’OCR, l’ERP ou la GED (gestion électronique de documents). Primo, assurez-vous de la qualité des données en entrée. Le fuzzy matching donne de meilleurs résultats si les données de base sont propres et si les textes extraits par l’OCR ont été normalisés un minimum en amont. Par exemple, éliminer les espaces superflus, uniformiser la casse (majuscules/minuscules) ou convertir tous les caractères accentués en leur version non accentuée peut aider l’algorithme à se concentrer sur les différences significatives. Certaines solutions incluent d’ailleurs des étapes de nettoyage des données avant d’appliquer la correspondance floue – un point à vérifier.
Secundo, dans le cadre d’une intégration à un ERP ou à un workflow de gestion, réfléchissez à la gouvernance des correspondances. Il est souvent judicieux de mettre en place des seuils de confiance différenciés avec des actions appropriées : par exemple, si le score de similarité est supérieur à 90%, valider automatiquement l’appariement ; s’il est entre 70% et 90%, envoyer le cas en revue manuelle assistée (avec une suggestion du système) ; et en-dessous de 70%, considérer qu’il n’y a pas de correspondance fiable. Ce genre de stratégie permet de tirer parti du fuzzy matching sans pour autant risquer des erreurs d’appariement dans l’ERP. Autrement dit, gardez une boucle de validation humaine pour les cas ambigus – du moins au début de l’implémentation – afin d’ajuster les paramètres si nécessaire.
Tertio, pensez à la compatibilité et l’interopérabilité technique. Si votre OCR ou votre GED possède déjà des fonctionnalités de fuzzy search/fuzzy match, voyez si elles répondent à vos besoins ou s’il faut les compléter avec un outil externe. Dans le cas d’une brique externe, assurez-vous qu’elle s’intègre bien via API ou connecteurs avec vos applications maison. La latence est un facteur à considérer : un appel à un service de fuzzy matching pour chaque document doit être suffisamment performant pour ne pas ralentir votre chaîne de traitement. Parfois, il peut être utile d’indexer à l’avance certaines données (par exemple, indexer tous les noms de fournisseurs dans un moteur de recherche floue) pour accélérer les requêtes au moment du rapprochement en temps réel.
Enfin, sensibilisez vos équipes à l’arrivée de cet outil. Le fuzzy matching peut étonner au début (voir le système rapprocher deux éléments qui semblent différents peut susciter questions), il faut donc expliquer son rôle et ses limites. En particulier, en intégrant le fuzzy matching dans un processus, documentez bien les règles et les seuils choisis, pour que chacun comprenne à quel moment le système considère deux valeurs comme correspondantes. Une fois ces points cadrés, l’intégration devrait se faire en douceur et apporter rapidement des gains de productivité.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Les ressources Koncile
Les deepfakes documentaires passent les contrôles classiques : comment les détecter en 2026 via l'analyse de cohérence sémantique.
Fonctionnalité

Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Comparatifs

Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.
Comparatifs
.png)


