


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Dernière mise à jour :
June 20, 2026
5 minutes
Fuzzy matching allows data to be automatically reconciled even when they are not perfectly identical. It is a powerful tool for automating your document workflows despite errors, variants or typos.
Discover how fuzzy matching improves the quality of your data and automates document reconciliation despite errors or variations.
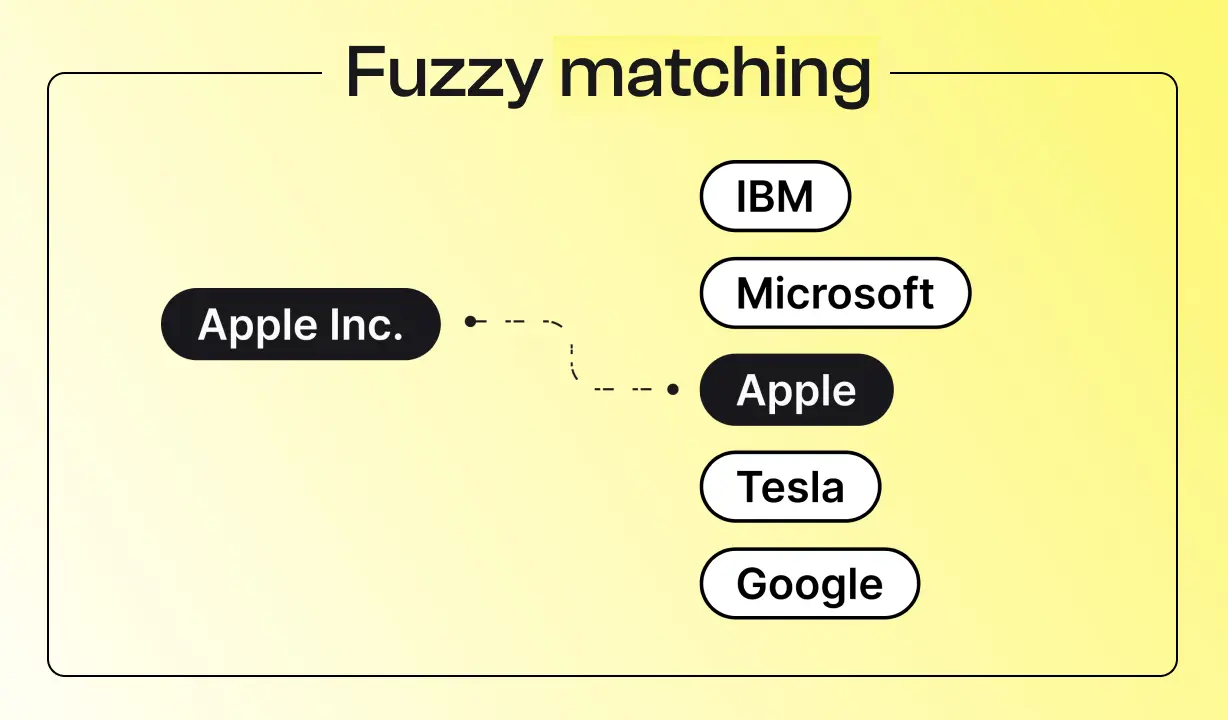
In many business processes, it is becoming crucial to reconcile information that does not do not match exactly identically. For example, a vendor invoice may contain a label or name that is slightly different from the one in your database. The Fuzzy Matching — or fuzzy correspondence in French — refers precisely to techniques that make it possible to find similarities between data that are not strictly the same. The aim is to answer a simple question: “Are these two elements close enough to be considered equivalent?” . In this article, we will clearly define fuzzy matching and review its concrete uses, in particular to make your documentary workflows reliable and automated (invoices, contracts, supplier data, customers, etc.), in tandem with OCR and your existing business systems.
The Fuzzy Matching is a method for finding approximate matches. Instead of requiring a character-for-character equality, a fuzzy matching algorithm calculates a similarity score between two character strings or two records. If this score exceeds a certain confidence threshold predefined (for example 85%), then the two elements are considered as a match, i.e. as representing the same information. In other words, fuzzy correspondence assesses how well a match is True or Wrong rather than operating on an all or nothing basis.
Concretely, this type of algorithm measures the number of modifications required to move from one channel to another — we are talking about edit distance. The fewer changes required, the more similar the two channels are. For example, to transform “INV-1000” in “INV1000” (without the dash), all you need to do is delete a character: the similarity will therefore be very high. On the other hand, to go from “2023 BILL” unto “BILL 2024”, there is a change in the number, which indicates two different references despite their similar appearance. Thanks to these calculations, fuzzy matching knows how to recognize that “ACME Corporation” and “ACME Corp.” refer to the same entity, because the similarity score will be well above the set threshold (for example ~ 92% similarity). Likewise, “Jean Dupont” vs “Jean Dupond” (a different letter) or “Societe Generale” vs “Societe Generale” (missing accent) can be reconciled via fuzzy matching, whereas an exact match would treat them as distinct values.
In classical computer theory, a comparison condition returns either true either wrong. Two values must be exactly the same to be recognized as equivalent. However, the The reality of business data is much more nuanced. Information extracted from documents often comes from a variety of sources (different suppliers, multiple systems) and includes unavoidable variations. The same supplier may be referred to as “ABC Ltd” in the Purchasing database and “A.B.C. Limited” on an invoice; a product may be abbreviated differently from document to document; not to mention input errors Or typos, nor approximations introduced by theOCR when scanning paper documents (for example, confusing the letter “O” with the number “0”). In short, real world data is rarely completely consistent.
Without the use of fuzzy matching, the slightest discrepancy in format or spelling can cause an automated reconciliation to fail. A strict system might reject an invoice simply because an accent is missing from the customer's name, or not finding a purchase order because a dash was omitted in the reference. These small differences break automation flows and require manual treatment. At the scale of a company dealing with thousands of documents, relying solely on exact matches is no longer viable: it would generate too manyexceptions to be managed manually, extending processing times and introducing a risk of errors. This is why fuzzy correspondence approaches have become essential to provide flexibility And of the resiliency in document workflows.
OCR (Optical Character Recognition) is often the gateway to document automation: it transforms scanned documents (paper invoices, scanned PDFs, contracts signed by hand, etc.) into text that can be used by digital systems. However, OCR is not foolproof — it can introduce small reading errors. For example, a “0” (zero) misinterpreted as “O” (letter O), or an “l” (lowercase L) mistaken for a “1”. Combining OCR with fuzzy matching, is ensuring that these minor discrepancies do not compromise automation. Fuzzy matching will tolerate the small differences resulting from OCR and still find the most likely match in your reference data.
Let's take a concrete example: a scanned supplier invoice contains the text “Order form: CM-4567” whereas in your ERP system, the order form is recorded as “BCM-4567”. If we were limited to an exact search, the field extracted by OCR (“CM-4567” amputated by one letter) would correspond to nothing and the invoice would be set as a manual exception. On the other hand, a fuzzy matching algorithm will detect that “CM-4567” is very close to “BCM-4567” (a difference of one character) and will be able to find the link with the appropriate order form. So The OCR + fuzzy matching alliance secures your workflows: OCR provides raw data and fuzzy correspondence Make it reliable by making up for small discrepancies. In the context of invoice control, this combination is a real Winning duo to automate the 3 Way Match reconciliation (order, receipt, invoice) reliably.
Beyond OCR, fuzzy matching plays a role in smart bridge between your documents and your business systems. Once the data has been extracted from a document, it is still necessary to link it to the correct records in your databases (supplier database, customer base, product catalog, etc.). This is where fuzzy correspondence unfolds its full potential. It allows you to match elements from a document with their reference in your system, even if the writing is slightly different.
For example, suppose a purchase order in your ERP contains an item that is described as “1TB External Hard Drive” while the supplier's invoice refers to it as “1TB USB external drive”. A fuzzy matching engine will be able to recognize that it is the same product despite the variation in wording, and thus theautomatically associate. Likewise, the name of a customer on a scanned contract (“Hotel Le Grand Bleu”) can be combined with your customer file (“The Big Blue Hotel”) even if the word order or language is slightly different. Fuzzy correspondence therefore enriches your document workflows by making the link between unstructured (the text in the documents) and the structured (your business data) transparently. This drastically reduces the need for manual research or Re-entering when a title does not “fit” exactly: the system finds the right reference for you. In short, fuzzy matching acts like a performer between your documents and databases, eliminating the friction caused by differences in formats or terminology.
Adopting fuzzy matching in your documentary processes is first and foremost make your automated controls more reliable. Indeed, thanks to fuzzy correspondence, systems detect real discrepancies and anomalies, without being disturbed by purely formal or benign differences. This means that your automation rules (for example, verifying that an invoice matches an order) will trigger fewer false alarms. Small discrepancies that do not affect the substance (alternative spellings, different date formats, upper/lower case, etc.) will be recognized as equivalent and will not result in an erroneous rejection of the document. Studies show that businesses using fuzzy matching are seeing a higher automation rate thanks to the reduction of these false non-conformities. In practice, your workflows “match” more documents the first time, without human intervention, which reinforces the trust in your system. Managers can confidently rely on automatic checks, knowing that they won't miss a correspondence just because of a minor text variation.
Who says more reliable controls also says fewer manual exceptions to be treated. Fuzzy matching contributes directly to reducing the volume of cases where the automaton cannot decide and requires human verification. By allowing the system to recognize that a document X does indeed refer to the entity Y in the database, we avoid switching this document to manual processing for “non-correspondence”. For your organization, this means a Time saver significant and a reduction in the workload for your teams. Instead of spending hours resolving discrepancies that aren't real (like “Ah, it was just a spelling error”), your employees can focus on real anomalies or tasks with higher added value. In addition, by reducing manual re-entries and tedious document comparisons, we mechanically reduce the risk of human error in the process. Fewer manual interventions mean fewer opportunities to introduce typing or judgment errors. In the end, fuzzy matching contributes to smoother, faster processes, and without avoidable errors. Document validations are carried out more quickly, supplier payment deadlines may be shortened, and your purchasing/finance teams gain in efficiency on a daily basis.
An often underestimated benefit of fuzzy matching isoverall improvement in data quality of the company. Indeed, by identifying that two differently worded entries actually refer to the same entity, fuzzy correspondence helps to deduplicate and to clean the databases. Your references (suppliers, customers, articles, etc.) remain united and coherent, without duplicates due to variations in spelling or format. For example, if the same supplier has been registered twice under slightly different names, a fuzzy matching algorithm can report this redundancy and facilitate the merging of duplicate records. Likewise, when integrating new data, the fuzzy system can attach new entries to existing records rather than creating duplicates. All this contributes to the reliability of your master data.
In addition, fuzzy matching can be used for standardization of labels. By combining similar terms, it makes it possible to reduce different variants to a standard description. For example, it can help standardize addresses (recognize that “St.” and “Street” are the same thing, or that “PARIS-75009" and “Paris 75009" represent the same location), or even harmonize how a product is named in different systems. In the end, you get better organized databases, facilitating analyses and avoiding inconsistencies. Quality data means more reliable reports, better customer/supplier knowledge, and a solid base for deploying advanced projects (data management, AI, etc.). So fuzzy matching is a investment in the quality of your information assets, with long-term positive benefits.
The most emblematic use case of fuzzy matching, in the context of accounts payable, is automatic reconciliation of invoices with purchase orders (and the receptions) even when the labels or references differ slightly. It's the famous “3-way matching” whose reliability may be undermined by differences in text. Thanks to the fuzzy correspondence, for example, your system will be able to associate an invoice line with the wording “DELUXE wireless keyboard” with a command line called “Deluxe keyboard — wireless”. Likewise, if the invoice mentions an order number “PO #100458” while your ERP stores “PO-100458" (with a dash), fuzzy matching will make the link automatically. The company thus gains in rapidity processing: the invoice is validated without manual intervention, since the system has understood that, despite the difference in presentation, the elements do correspond. It also reduces disputes and exchanges between teams (accounting, which requires purchases to check such discrepancies, etc.), because fewer invoices are blocked for trivial details. In short, fuzzy matching makes invoice-order reconciliation possible more tolerant of variations, which makes it possible to streamline the validation process while maintaining a high level of control.
In the management of master data (Master data customers or suppliers), fuzzy matching is invaluable in detecting duplicates that would otherwise go unnoticed. For example, the same supplier might appear twice in your system: once as “Transports Dupré SARL” And another time like “DUPER TRANSPORT”. A human eye will not necessarily make the connection, especially in a directory of thousands of entries. A fuzzy matching algorithm, on the other hand, will calculate that these two denominations are very similar and may flag them as a potential duplicate. Likewise for customers: “Saint John's Hospital” vs “St. John's Hospital” — despite missing accents or abbreviations, the system will probably identify that it is the same entity. By integrating this tool into your processes, you can set up controls that alert when a user creates a new supplier/customer card whose name is very similar to an existing one. It helps you keep a base United, to avoid duplicates that distort analyses (e.g. consolidation of expenses by supplier), and to prevent errors such as the unintentional creation of two accounts for the same third party. The detection of duplicates by fuzzy matching can also be used as an audit to identify, for example, two suspicious invoices with almost the same number (possible sign of double billing). Overall, this use reinforces the conformity And the transparency company data.
Fuzzy matching can also be used proactively for automatic correction data that is poorly formatted or with errors. Let's say that in an invoice, the product code “AB-1234” expected has been entered or recognized OCR as “FROM 1234" (without hyphens) or “A8-1234” (with an 8 in place of the B due to poor reading). A fuzzy matching engine will compare these entries to the list of valid product codes and find the closest product code. If he determines that “A8-1234” is 95% similar to “AB-1234”, it will automatically be able to correct the reference or suggest the correction to the user. This principle is the same as that of an intelligent spell checker: we look for all the possibilities that are close (within one or two letters) of the unknown term, then we choose the most probable match. In a business context, this means fewer items that are not recognized or misclassified. Your databases gain in accuracy because small mistakes are corrected On the fly. In addition to product codes, think about addresses (correct “Avenue of General De Gaulle” in “Avenue du Général-de-Gaulle” if the official database contains the accent), customer references (add a missing initial zero on an account number), etc. Fuzzy matching brings here a security : even if the information entered is not perfect, the system brings it back to a correct or consistent value. This is particularly useful when capturing data via OCR or web forms, where you can self-correct what was entered incorrectly to avoid downstream errors.
Finally, another common use case for fuzzy matching is standardization of labels and the mapping of different frames of reference. In large organizations, multiple databases or value lists for similar entities are often inherited, with varying naming conventions. The fuzzy correspondence makes it possible to reconcile these different variants for standardize. For example, your CRM marketing database indicates sectors of activity in full (“Pharmaceutical industry”) while your ERP database uses codes or abbreviations (“Pharma” or “Pharma industry.”). Instead of manually harmonizing thousands of entries, an algorithm can group together similar entries and suggest a master label. Likewise, for non-codified data such as service titles, articles or project titles, fuzzy matching can help identify that “Level 1 support service” and “Level 1 Support” refer to the same category and should be named consistently. This standardization has a direct impact on the quality of analyses and reports: by speaking the “same language” everywhere, you can consolidate data without hidden duplicates. For operational purposes, it is also more comfortable — information is easier to find because you do not have to try several spellings or labels for a search. Fuzzy matching therefore serves as Semantic glue between disparate databases, facilitating data migration projects or the establishment of unique repositories (Master Data Management). In the end, you get clear, consistent labels, which reflect a better organized business.
If you are considering integrating fuzzy correspondence into your tools, several quality criteria should be examined in order to choose the right solution. The first is obviously the precision of the algorithm: it must find as many matches as possible pertinent while avoiding random reconciliations. In other words, a good fuzzy matching engine minimizes the false negatives (matches missed when they should have been done) that the false positives (matches made incorrectly between different elements). To assess this, you can test the tool on a sample of your known data and assess whether it finds the expected links without creating false ones.
A second important criterion is the parametridability. Each business context has its own particularities, and it is crucial to be able to adjust the similarity threshold according to your specific needs. An engine that allows you to configure, for example, a threshold of 90% for sensitive matches (critical codes) and 80% for other fields, will offer you an appreciable degree of control. Likewise, the possibility of choosing or combining different algorithms (distance from Levenshtein, Jaro-Winkler, phonetic correspondence for names, etc.) is a plus, as no single method is suitable for all data types. For example, for personal names, an algorithm that ignores accents and considers sounds may work better, while for numbers or codes, the Levenshtein distance is often effective.
La performance And the scalability of the engine are also to be examined. On very large volumes of data (millions of records to compare), the algorithm must be optimized to remain fast. Learn about the tool's ability to index data and perform fuzzy searches without excessively extending processing times. Some engines take advantage of advanced database technologies or search indexes to speed up approximate matches.
Finally, consider aspects of Getting started And ofintelligence of the engine. For example, does the tool provide an explicit similarity score and information on why two items were reconciled (to facilitate checks)? Does it offer a fashion “apprenticeship” where does it improve based on corrections validated by users (supervised learning)? . An industrial-grade fuzzy matching solution will generally offer an interface or APIs to review, validate, or refine proposed matches, in order to maintain control over the process.
For a successful implementation of fuzzy matching, it is necessary to anticipate some points of vigilance during integration with your existing systems, such as OCR, ERP or EDM (electronic document management). First of all, make sure you input data quality. Fuzzy matching gives better results if the basic data is clean and if the texts extracted by OCR have been standardized at least beforehand. For example, eliminating unnecessary spaces, standardizing case (upper/lower case), or converting all accented characters to their unaccented version can help the algorithm focus on significant differences. Some solutions also include steps of scrubbing data before applying the fuzzy match — a point to check.
Second, as part of an integration with an ERP or a management workflow, consider the correspondence governance. It is often a good idea to set up differentiated confidence thresholds with appropriate actions: for example, if the similarity score is greater than 90%, automatically validate the match; if it is between 70% and 90%, send the case for an assisted manual review (with a suggestion from the system); and below 70%, consider that there is no reliable match. This kind of strategy makes it possible to take advantage of fuzzy matching without risking matching errors in the ERP. In other words, keep a human validation loop for ambiguous cases — at least at the beginning of the implementation — in order to adjust the parameters if necessary.
Thirdly, think of the compatibility and interoperability technique. If your OCR or GED already has fuzzy search/fuzzy match features, see if they meet your needs or if they should be supplemented with an external tool. In the case of an external brick, make sure that it integrates well via API or connectors with your home applications. Latency is a factor to consider: a call to a fuzzy matching service for each document must be efficient enough not to slow down your processing chain. Sometimes it can be useful toindex in advance some data (for example, indexing all supplier names in a fuzzy search engine) to speed up queries at the time of real-time reconciliation.
Finally, make your teams aware of the arrival of this tool. Fuzzy matching can be surprising at first (see the system bringing together two elements that They seem different may raise questions), so its role and limitations must be explained. In particular, by integrating fuzzy matching into a process, Document the rules well and the thresholds chosen, so that everyone understands when the system considers two values to be corresponding. Once these points are in place, integration should be smooth and bring rapid productivity gains.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Jules leads product development at Koncile, focusing on how to turn unstructured documents into business value.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


