


.webp)
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature
.webp)
Dernière mise à jour :
June 20, 2026
5 minutes
How do you know if two recordings are about the same customer, supplier, or product? In this article, discover how data matching works, key techniques, market tools, and many concrete use cases to get the most out of your data.
Le data matching permet de recouper, unifier et fiabiliser vos données dispersées. Dans cet article complet, explorez les techniques avancées (fuzzy matching, machine learning…), découvrez les outils adaptés à chaque besoin et plongez dans des cas d’usage concrets pour automatiser et optimiser vos traitements de données.
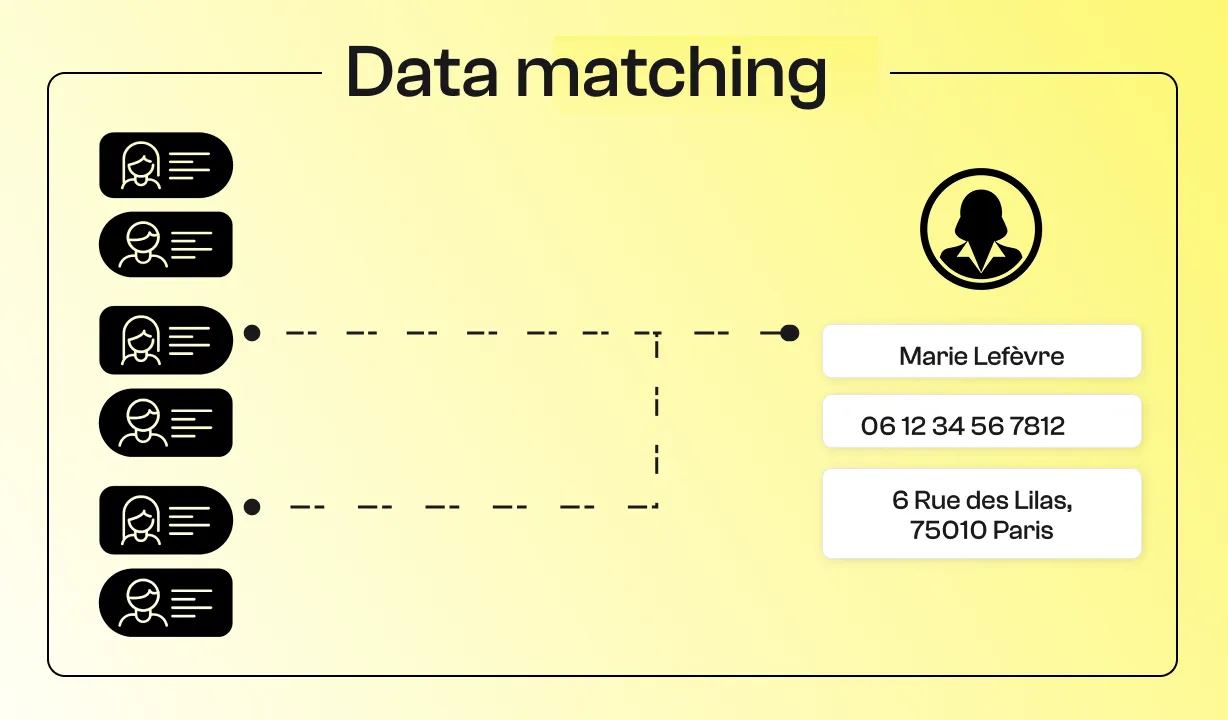
The Data Matching, or data reconciliation, consists of comparing data sets to identify those that refer to the same real entity (individual, company, product, etc.).
Concretely, it is a question of determining whether two recordings from different sources correspond to the same thing. This process makes it possible to detect duplicates in a base or of link several databases not sharing a common identifier.
Without data matching, these duplicates or fragments go unnoticed, affecting data quality.

Several matching techniques exist, adapted to different contexts. They can be combined for better results.
Here are the main ones:
Exact matching compares data Identical. Two values must be exactly the same to be recognized as a match. It is simple and reliable if the data is perfectly standardized (unique identifiers, customer codes...).
But at the slightest variation (typo, accent, abbreviation), the correspondence fails. Example: “ACME Corporation” • “ACME Corp.”
➡️ Useful on own data, but too rigid on its own.
Fuzzy matching compares values by calculating a similarity score. If this score exceeds a threshold (e.g. 80%), it is considered that there is a match.
It handles mistakes, abbreviations, accents or minor variations well: “Société Générale” ≈ “Societe Generale”.
➡️ Flexible and efficient, but requires a good adjustment to avoid false positives.
This method combines several criteria (name, email, date...) with weights to estimate a overall probability of correspondence.
Even if no data is 100% identical, an accumulated score may be enough to validate a match.
➡️ Very suitable for imperfect data, but more complex to set up.
Hybrid matching combines approaches previous ones: accurate, vague, probabilistic... We apply the strictest rules first, then the more flexible methods in case of failure.
➡️ Balance between accuracy and coverage, often used in business.
We can also Train a model to detect matches, based on labeled examples (Match / Non-match).
Common techniques: classification, clustering, neural networks.
➡️ Very efficient on complex data, but requires training data and supervision.
Data matching has become indispensable and meets a very concrete need: to link, make reliable and unify information from multiple sources in order to derive real value from it.
More than just mapping, it is a key step in ensuring the quality of the data and its proper use on a daily basis.
A successful data matching project is based on a series of rigorous steps. Each phase plays a specific role in ensuring reliable matches between recordings.

The first essential step: the scrubbing data.
Unnecessary characters are removed, obvious errors are corrected and formats are homogenized (e.g. uppercase letters, accents, punctuation). This phase aims to eliminate biases that could skew matches.
The fields are standardized using a common format to facilitate comparison.
For example, all dates can be converted to ISO format (YYYY-MM-DD), addresses to standard postal notation, or phone numbers to international format.
To avoid comparing each line with all the others, we create search keys (or “blocks”).
These keys, generated from combined fields (e.g. postal code + first letter of the name), limit comparisons to consistent groups and speed up the process.
It is the heart of matching. The algorithms compare the selected fields using various methods:
Each pair is given a trust score or level.
We define a similarity threshold to consider two cards as corresponding.
This threshold depends on the use cases:
It can be adjusted over time based on user feedback or the desired tolerance level.

The market offers a wide range of solutions to automate data matching, depending on data types, functional needs and available resources.
Specialized data quality solutions - examples: Data Ladder, WinPure, Informatica
These tools are designed for large-scale data consolidation projects. They offer no-code interfaces to configure correspondence rules (exact or fuzzy), adjust similarity thresholds, visualize duplicates and validate matches manually.
Open source tools or technical libraries - examples: OpenRefine, Dedupe.io, Python libraries
Intended for technical users, these tools make it possible to create personalized treatments, adapted to complex cases or cases with strong business constraints. They offer great flexibility, but require programming or data engineering skills.
Modules integrated into business software - examples: CRM (Salesforce, HubSpot), ERP, HR or accounting tools
Many software programs incorporate native deduplication or contact fusion functions. These options are generally easy to activate from the administration interface, but remain limited in terms of advanced settings or complex matching logic.
Workflow automation tools - examples: Make, Zapier, N8N
These platforms make it possible to automate data flows between different systems, and to add matching steps during synchronizations (e.g. between an email database and a CRM). They are particularly useful for non-technical teams or cases that are simple to moderate.
Solutions combining extraction and matching (OCR + matching) - examples: Koncile
For many use cases (accounting, HR, KYC...), the data to be matched can be found in PDF or scanned documents. Solutions like Koncile incorporate an engine OCR to automatically extract relevant fields, normalize them, and then reconcile them with existing data using exact or fuzzy matching techniques.
This makes it possible to automate time-consuming manual tasks while securing the quality of correspondence.
Despite its advantages, data matching has several challenges to anticipate to guarantee its reliability and relevance:
Implementing reliable data matching does not only depend on the tools, but also on the methods used. Here are the best practices to improve accuracy, limit errors, and maintain your results:
These best practices, combined with detailed knowledge of your data and good business support, will allow you to exploit the full potential of data matching in a reliable and sustainable way.
The Data matching plays a transversal role : it facilitates the coherence of the bases, improve the data quality and supports inter-system analysis in all jobs where information is critical.
Moreover, data matching applies in many sectors as soon as necessary. clean, cross-check or make reliable data from multiple sources. Here are some concrete examples by domain:
The choice of a data matching tool depends above all on your business context, of your data volumes And of complexity level connections to be made. Here are the main criteria to take into account in order to select a suitable solution:
A good choice is therefore based on the detailed evaluation of your real use cases, associated with a clear vision of the goals (time savings, quality improvement, automation, compliance...). Do not hesitate to test several options or to opt for a modular solution capable of adapting to your evolutions.
It is the key performance indicator of a matching algorithm.
The AI matching rate measures the percentage of matches correctly detected by a solution using artificial intelligence. It reflects the system's ability to automatically recognize duplicates or similar entities in your databases.
It is the process that makes it possible to gather in a single record all the data scattered about the same entity. By identifying and merging duplicates from different sources, this integration creates a single, coherent and usable form. This is a key step in achieving a unified, consistent, and actionable customer base.
Data matching is used to bring together data that talks about the same thing, even if it is scattered or poorly formatted. Data mining, on the other hand, seeks to understand what this data can reveal once it is well organized. The former brings information together, the latter draws lessons from it.
Not completely, but it can get close.
When a unique identifier is missing, data matching makes it possible to simulate reliable identification by crossing several fields. This offers an alternative solution for recognizing an entity, while maintaining a certain margin of uncertainty.
The thresholds vary according to the level of reliability expected. In general, a threshold around 90% makes it possible to obtain reliable matches while limiting errors. For less critical cases, a threshold of 80% may suffice. The ideal is to adjust it according to your data and your business goals.
By empowering users to correct, validate, or report errors directly in the tool. Their feedback allows confidence thresholds to be adjusted and the system to be improved over time. It is this interaction that makes matching more reliable, smarter, and better adapted to your data.
Move to document automation
With Koncile, automate your extractions, reduce errors and optimize your productivity in a few clicks thanks to AI OCR.
Tristan Thommen designs and deploys the core technologies that transform unstructured documents into actionable data. He combines AI, OCR, and business logic to make life easier for operational teams.
Resources
Document deepfakes pass classic checks: how to detect AI-generated fake documents in 2026 with semantic coherence analysis.
Feature

Ten document fraud detection platforms compared on detection approach, fraud focus, integration and target profile, from semantic specialists to identity-verification incumbents.
Comparatives

Ten accounts payable automation platforms compared across AI agents, fraud detection, ease of integration, and target profile, from enterprise incumbents to AI-native challengers.
Comparatives
.png)


