Traitement Automatique du Langage (NLP) : définition, usages et fonctionnement (2026)
Le traitement automatique du langage (NLP) est l’un des piliers de l’intelligence artificielle. Il permet aux machines de comprendre, d’interpréter et de générer le langage humain, transformant les textes non structurés en données exploitables. Du chatbot à la conformité réglementaire, le NLP relie communication humaine et intelligence numérique.
Résumé
Le NLP combine linguistique, statistique et apprentissage automatique pour rendre le langage compréhensible par la machine. Il alimente les assistants vocaux, les outils de traduction, les résumeurs de texte et s’associe à l’OCR pour extraire du sens des documents. Résultat : des processus plus rapides, des décisions plus fiables et une automatisation intelligente.
Qu’est-ce que le Natural Language Processing (NLP) ?
Le Natural Language Processing (NLP) désigne l’ensemble des méthodes permettant à une machine de comprendre et produire du langage humain. Il se cache derrière les assistants vocaux comme Siri ou Alexa, capables d’interpréter les requêtes et d’y répondre intelligemment. Les messageries et outils d’analyse textuelle reposent sur ces mêmes mécanismes.
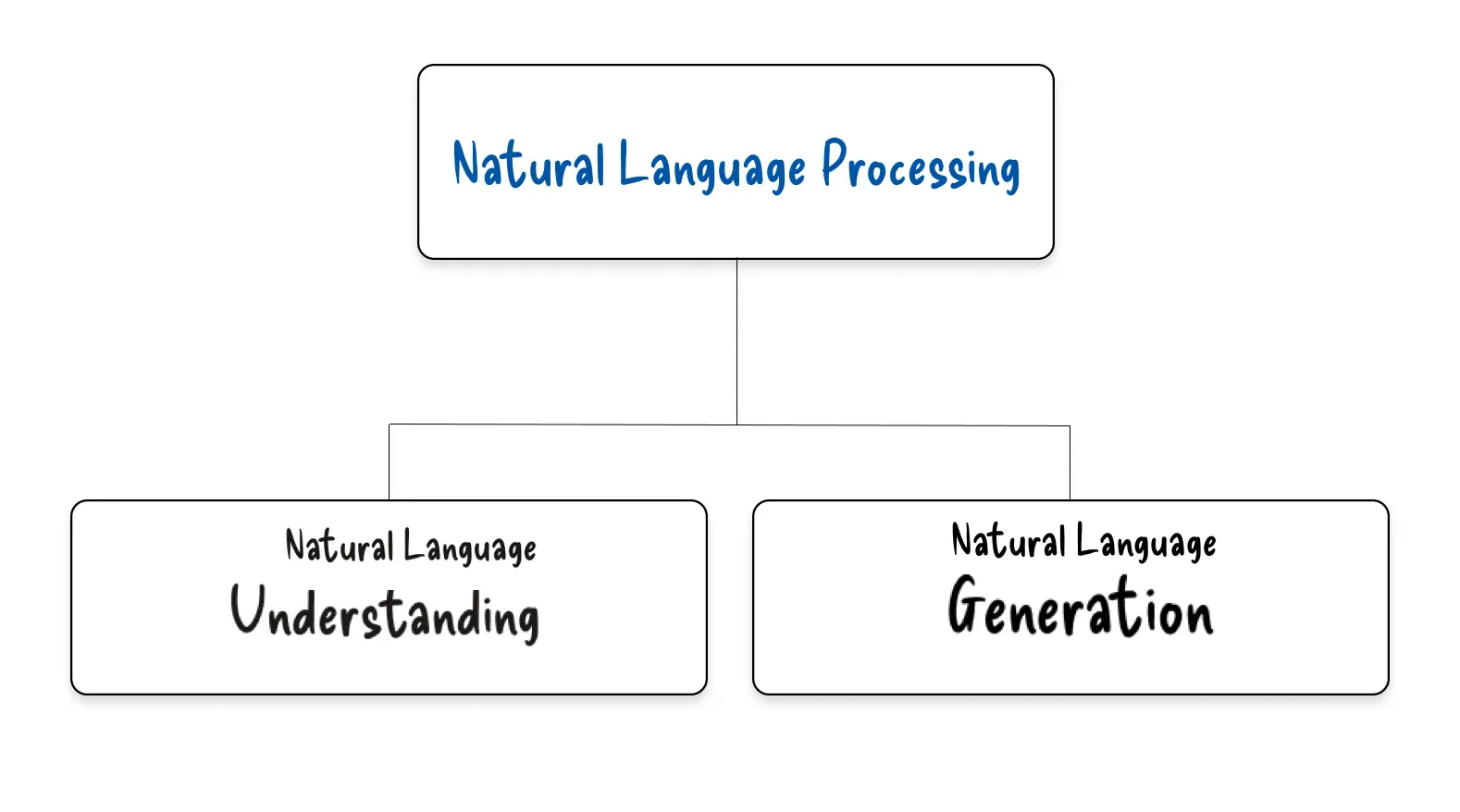
NLP vs NLU vs NLG : différences clés
NLU (Natural Language Understanding) : la compréhension du sens et de la structure d’une phrase humaine.
NLG (Natural Language Generation) : la génération automatique de texte à partir de données structurées.
NLP : englobe ces deux aspects – c’est la discipline qui fait le pont entre langage et informatique.
Principales applications du NLP
Chatbots et assistants vocaux : compréhension d’intentions, réponses contextuelles et automatisation du support.
Traduction et localisation : amélioration continue des traductions automatiques et adaptation multiculturelle.
Analyse de sentiment : compréhension du ressenti client dans les avis, réseaux sociaux ou enquêtes.
Résumé et génération de texte : synthèse de rapports, rédaction automatique, gain de temps pour les équipes.
Recherche et SEO : meilleure interprétation des requêtes et optimisation du référencement contextuel.
Filtrage et modération : détection de contenus indésirables ou inappropriés.
Les 6 étapes du traitement NLP
Étape
Description
1. Segmentation
Découper un texte en phrases distinctes.
2. Tokénisation
Découper les phrases en mots ou sous-unités appelés tokens.
3. Normalisation
Nettoyer le texte et réduire la variabilité linguistique (lemmatisation, racinisation).
4. Suppression des stop words
Éliminer les mots fréquents (“et”, “de”, “le”) et représenter les textes sous forme numérique.
5. Analyse syntaxique et sémantique
Repérer la structure (POS tagging, parsing, entités nommées).
6. Compréhension avancée
Appliquer des modèles pour le sentiment, le résumé, la traduction ou la Q&A.
Quand l’OCR rencontre le NLP
L’OCR (reconnaissance optique de caractères) transforme les documents scannés en texte lisible par la machine. Le NLP, lui, ajoute la compréhension et le contexte.
Combinés, ils permettent :
d’extraire automatiquement des données clés (montants, noms, dates),
de classifier les documents par type,
et d’enrichir les systèmes métiers en temps réel.
En résumé :l’OCR lit, le NLP comprend.
Questions fréquentes
Quels algorithmes sont les plus utilisés ?
Les modèles Transformers (BERT, GPT, T5) dominent le domaine. Les approches hybrides (RAG) améliorent la précision et la traçabilité.
Quels secteurs utilisent le plus le NLP ?
Service client, finance, juridique, assurance, santé, e-commerce et RH : partout où il faut comprendre du texte à grande échelle.
Le NLP comprend-il l’ironie ?
Partiellement. Les modèles détectent certains indices contextuels, mais une validation humaine reste recommandée.
Le NLP fonctionne-t-il avec les manuscrits ?
Oui, via HCR/ICR (extensions de l’OCR). La qualité dépend du scan et du prétraitement.
Menu
Qu’est-ce que le Natural Language Processing (NLP) ?
Le NLP (traitement du langage naturel) permet aux systèmes de comprendre et de produire du texte de façon fiable. Cet article présente l’essentiel : définition, cas d’usage, étapes clés et articulation avec l’OCR pour des processus documentaires plus rapides et précis.
Découvrez comment le NLP comprend et génère le langage, tandis que l’OCR convertit images et PDF en texte exploitable. Combinés, ils accélèrent l’extraction d’informations, réduisent les erreurs et renforcent la qualité des processus.
Qu’est-ce que le NLP ?
Le Natural Langage ProcessingNLP (ou traitement du langage naturel en français) est un domaine de l’intelligence artificielle et du machine learning qui permet, via des algorithmes linguistiques et statistiques, de comprendre le langage naturel humain.
Son objectif principal est donc de permettre aux machines de comprendre, d’interpréter et de produire la langue humaine de manière à la fois pertinente et utile.
La majorité des utilisateurs ont déjà interagi avec le NLP sans en avoir vraiment conscience.
Cette technologie est en effet au cœur des assistants virtuels tels qu’Oracle Digital Assistant (ODA), Siri ou Alexa. Elle leur permet de comprendre les requêtes des utilisateurs et d’y répondre dans un langage naturel. De la même manière, certaines applications de messagerie s’appuient sur le NLP pour analyser le contenu d’un message et proposer automatiquement une réponse adaptée.
NLP vs NLU vs NLG : différences clés
Dans l’univers du traitement automatique du langage, plusieurs termes voisins coexistent et prêtent parfois à confusion. Le NLP (Natural Language Processing), le NLU (Natural Language Understanding) et le NLG (Natural Language Generation) désignent en réalité des approches complémentaires autour du langage naturel.
NLU (Natural Language Understanding) correspond à la capacité des machines à analyser et comprendre la structure et le sens d’une phrase exprimée par un humain. Il s’agit de l’aspect « compréhension », permettant d’interagir avec les ordinateurs en utilisant des phrases naturelles.
NLG (Natural Language Generation) se concentre sur la production de texte à partir de données. On parle aussi de « language out » : l’ordinateur génère une description verbale, un résumé ou une explication en langage clair, souvent à l’aide de modèles linguistiques ou de règles (parfois appelées grammaire des graphiques).
NLP (Natural Language Processing), plus large, englobe à la fois la compréhension et la génération du langage. C’est le domaine d’ingénierie qui vise à construire des systèmes capables de traiter, analyser, produire et manipuler le langage humain.
En parallèle, la linguistique informatique (Computational Linguistics – CL) constitue le champ scientifique qui étudie les aspects théoriques et informatiques du langage humain, tandis que le NLP met l’accent sur l’application concrète et l’ingénierie de solutions exploitables.
Les principales applications du NLP
Le traitement automatique du langage naturel couvre un large éventail d’usages et façonne de plus en plus nos pratiques quotidiennes.
Voici un aperçu de ses usages les plus marquants :
Cas d’usage
Ce que fait le NLP
Exemples
Bénéfices
Chatbots et assistants intelligents
Interprète les questions, détecte l’intention et répond selon le contexte.
Support IT/RH, assistants vocaux, self-care client.
Moins de tickets simples, temps de réponse réduit, équipes libérées.
Traduction et gestion multilingue
Améliore la traduction et la localisation de contenus.
Sites, apps, documents produits & marketing.
Cohérence des messages, expansion internationale facilitée.
Analyse des émotions et perception client
Détecte le sentiment et les thèmes dans de grands volumes de texte.
Avis, réseaux sociaux, verbatims d’enquêtes.
Mesure de la satisfaction, détection précoce des signaux faibles.
Synthèse et production de contenus
Résume des textes longs et génère des contenus structurés.
Résumés de rapports, scripts de chatbot, brouillons marketing.
Gain de temps, homogénéité éditoriale, meilleure réutilisation.
Amélioration de la recherche et visibilité en ligne
Comprend l’intention de requête et enrichit les résultats.
Recherche sémantique interne, FAQ, optimisation SEO.
Meilleure découvrabilité, accès plus rapide à l’information.
Détection, filtrage et modération
Identifie spam, toxicité, fraude et désinformation.
Anti-spam e-mail, modération de commentaires, surveillance UGC.
Espaces plus sûrs, conformité et qualité des échanges.
Les 6 étapes clés du traitement du langage naturel (NLP)
Le traitement automatique du langage naturel (NLP) suit un pipeline structuré, combinant des techniques linguistiques, statistiques et d’apprentissage automatique.Voici les grandes étapes qui permettent de transformer un texte brut en informations exploitables.
1. Segmentation des phrases
Le processus commence par la segmentation, qui découpe un texte en phrases distinctes. Un algorithme identifie les signes de ponctuation (points, exclamations, interrogations) afin d’isoler des unités de sens complètes.Tout commence par la segmentation, qui consiste à découper un texte en phrases distinctes.
2. Tokénisation
La tokénisation divise chaque phrase en unités élémentaires appelées tokens : mots, sous-mots, chiffres ou ponctuation.
Cette étape prépare le terrain pour l’analyse grammaticale et sémantique.
3. Normalisation du texte
Le texte est ensuite simplifié pour réduire la variabilité linguistique.
Deux techniques principales sont utilisées :
La racinisation (stemming) : coupe les suffixes pour garder uniquement la racine du mot (“mangé” → “mang”).
La lemmatisation : ramène le mot à sa forme canonique correcte (“mangé” → “manger”).
Cette étape garantit une meilleure cohérence dans l’analyse des données textuelles.
4. Suppression des mots d’arrêt et représentation
Certains mots fréquents, dits stop words (“et”, “de”, “le”), sont supprimés car ils apportent peu d’information.
Ensuite, le texte est converti en données numériques exploitables :
via un modèle sac de mots (bag-of-words) ou un TF-IDF,
ou via des embeddings (Word2Vec, BERT) qui capturent le sens et le contexte des mots.
5. Analyse syntaxique et sémantique
À cette étape, le système cherche à comprendre la structure des phrases :
PoS tagging : attribuer à chaque mot sa fonction grammaticale (nom, verbe, adjectif…).
Parsing syntaxique : identifier les relations sujet–verbe–complément.
NER (Named Entity Recognition) : extraire des entités comme des personnes, des lieux ou des organisations.
6. Compréhension avancée et applications
Enfin, le texte peut être exploité dans des applications concrètes :
analyse de sentiment (positif, négatif, neutre),
résumé automatique ou traduction,
résolution de coréférence (“Jean est arrivé. Il était fatigué” → “Il” = “Jean”).
C’est à ce stade que le NLP devient directement utile dans des cas métiers : chatbots, moteurs de recherche, extraction documentaire (OCR + NLP), assistants virtuels, etc.
Les défis du NLP
Malgré ses avancées spectaculaires, cette discipline se heurte encore à plusieurs obstacles techniques et linguistiques qui limitent son déploiement à grande échelle.
L’ambiguïté du langage
Un même mot peut changer de sens selon le contexte (lexical, syntaxique, sémantique). Même avec le contexte, la désambiguïsation reste difficile.
Diversité des styles et registres
Ironie, sarcasme, ton, jargon… Les modèles interprètent souvent littéralement, ce qui peut fausser l’analyse.
Coréférence
Relier pronoms et mentions à la bonne entité est essentiel pour résumer, répondre aux questions et extraire des infos fiables.
Synonymie & variation lexicale
Plusieurs mots pour une même idée, mais pas toujours interchangeables. La richesse lexicale complique la détection et le rappel.
Quand l’OCR rencontre le NLP
La reconnaissance optique de caractères (OCR) est la technologie qui permet de transformer une image contenant du texte imprimé ou manuscrit (facture scannée, contrat signé, note de frais, formulaire, etc.) en texte numérique exploitable.
Cette étape est essentielle pour convertir des documents papier ou des fichiers image en données structurées, prêtes à être traitées par un ordinateur.
Là où l’OCR se limite à capturer fidèlement le texte, le NLP ajoute une couche d’intelligence et de compréhension contextuelle. Il est capable de classer, contextualiser et extraire les informations pertinentes, transformant ainsi un texte brut en données immédiatement exploitables par les systèmes métiers.
En résumé : l’OCR numérise, le NLP comprend.
Ce que permet l’intégration OCR + NLP
L’association de l’OCR et du NLP présente plusieurs atouts pour les entreprises :
Sécuriser les informations sensibles
Gestion des documents conforme aux normes de confidentialité pour garantir la protection des données et la conformité réglementaire.
Accroître la fiabilité des résultats
Interprétation plus précise des contenus pour limiter les erreurs et améliorer la qualité des analyses produites.
Optimiser les ressources
Automatisation des tâches chronophages pour réduire le temps passé et les coûts opérationnels.
Alléger les tâches répétitives
La machine prend en charge la saisie et les opérations répétitives ; les équipes se concentrent sur des activités à plus forte valeur.
Accélérer l’extraction d’informations
Données récupérées plus vite et de manière structurée, quel que soit le type de document ou la source.
FAQ
On utilise encore des règles et expressions régulières pour des motifs simples, mais la norme actuelle repose sur le machine learning et surtout les réseaux de neurones Transformers préentraînés (BERT, GPT, etc.). Les approches hybrides qui combinent recherche et génération (RAG) se généralisent pour gagner en précision et en traçabilité.
Un corpus représentatif du domaine, propre et varié, avec des annotations de qualité alignées sur la tâche. La diversité compte plus que le volume brut. En contexte sensible, il faut prévoir anonymisation et gouvernance des données.
Service client, finance et conformité, juridique et assurance, santé, e-commerce et marketing, ainsi que RH. Le point commun est l’automatisation de la lecture, la compréhension et la priorisation de grands volumes de texte.
Partiellement. Les modèles détectent certains indices de contexte ou de tonalité, mais la performance reste inférieure à des tâches factuelles. Pour des décisions sensibles, mieux vaut prévoir une validation humaine ou des règles de prudence.
Oui, si le manuscrit est d’abord converti en texte via HCR ou ICR, qui sont des extensions de l’OCR. La qualité du résultat dépend alors du prétraitement du document et des paramètres de confiance. Un contrôle humain ciblé peut sécuriser les cas ambigus.
Selon la tâche : précision, rappel et F1 pour classification et NER, BLEU/COMET pour la traduction, ROUGE/BERTScore pour le résumé, Exact Match et F1 pour la question–réponse. En production, on suit aussi le taux de traitement direct, l’escalade vers l’humain, la latence et la dérive des données. Une revue humaine régulière reste indispensable.
Passez à l’automatisation des documents
Avec Koncile, automatisez vos extractions, réduisez les erreurs et optimisez votre productivité en quelques clics grâce à un l'OCR IA.
Dix solutions de détection de fraude documentaire comparées sur l'approche de détection, les types de fraude couverts, l'intégration et le profil cible.
Dix plateformes d'automatisation de la comptabilité fournisseurs comparées sur les agents IA, la détection de fraude, la facilité d'intégration et le profil cible, des acteurs historiques aux challengers AI-native.



.webp)



.webp)


.png)


