Natural Language Processing (NLP): Definition, Uses, and How It Works (2026)
Natural Language Processing (NLP) is one of the most powerful branches of artificial intelligence. It allows machines to understand, interpret, and generate human language — turning unstructured text into actionable insights. From chatbots to compliance automation, NLP bridges the gap between human communication and digital intelligence.
Summary
NLP combines linguistics, statistics, and machine learning to make language understandable to computers. It powers everyday tools like chatbots, translation systems, or text summarizers — and is often used alongside OCR to extract meaning from documents. The result: faster workflows, better decisions, and more intelligent automation.
What Is Natural Language Processing (NLP)?
Natural Language Processing (NLP) is an AI discipline that uses algorithms and linguistic models to help computers understand and produce human language naturally and meaningfully. It powers voice assistants like Siri or Alexa, enabling them to interpret requests and respond intelligently. Similarly, messaging apps leverage NLP to suggest contextual replies and automate responses.
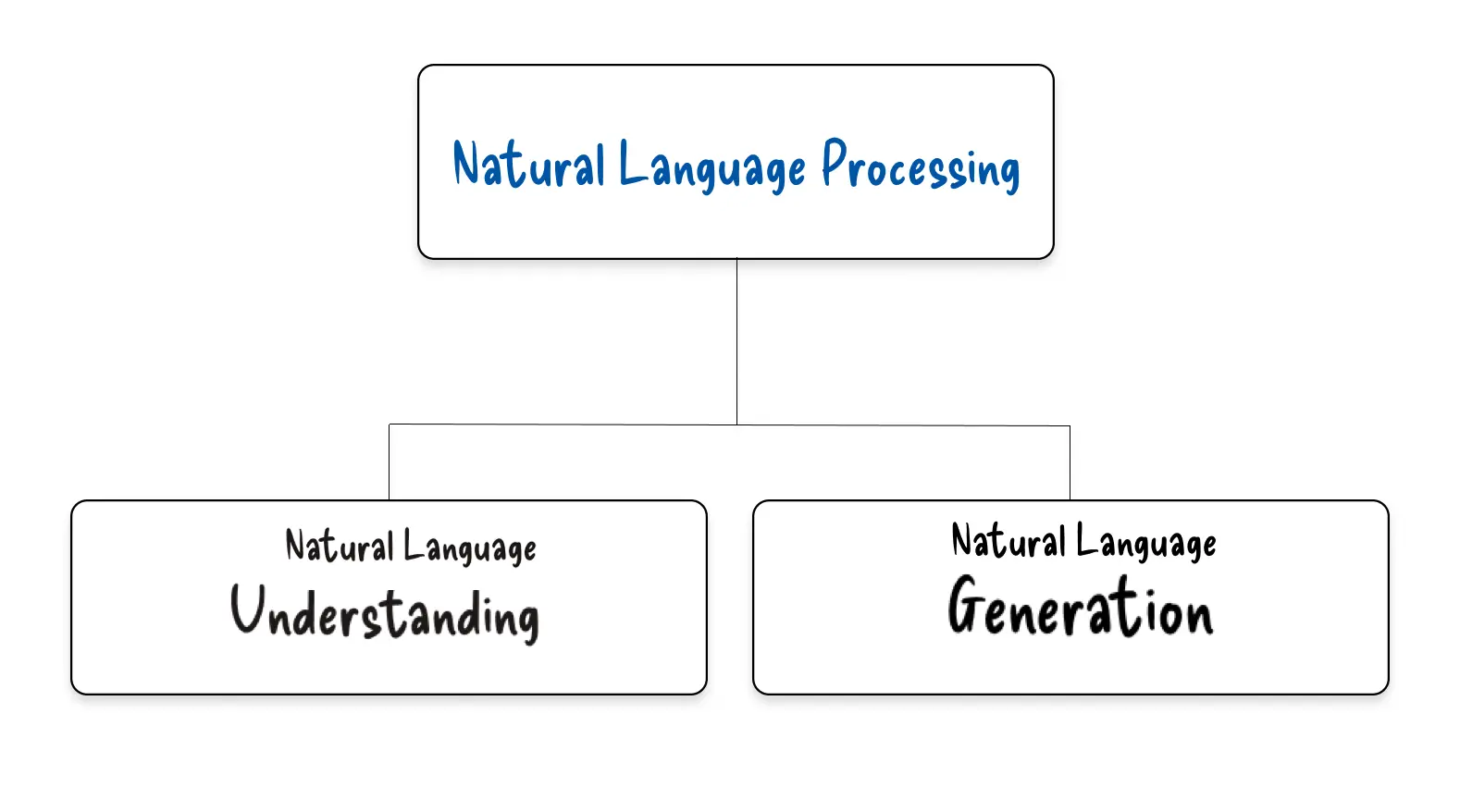
NLP vs NLU vs NLG: Key Differences
In the world of language AI, several related concepts coexist:
NLU (Natural Language Understanding) focuses on the comprehension of meaning and syntax in human language.
NLG (Natural Language Generation) focuses on producing natural text from structured data.
NLP (Natural Language Processing) covers both — the overall engineering process that makes machines capable of analyzing, understanding, and generating language.
Main Applications of NLP
Chatbots and Voice Assistants: NLP allows virtual assistants to interpret intent and respond dynamically, automating customer support and internal operations.
Translation and Localization: NLP enhances automatic translation systems and ensures contextual accuracy across languages.
Sentiment and Opinion Analysis: By analyzing text from social media or surveys, NLP extracts emotional tone and helps businesses track perception.
Text Summarization and Generation: NLP condenses long documents into key insights and can generate reports or marketing copy automatically.
Search and SEO Optimization: Search engines rely on NLP to interpret user intent, improving query relevance and visibility.
Filtering and Moderation: NLP identifies spam, inappropriate comments, or misinformation to maintain safe digital spaces.
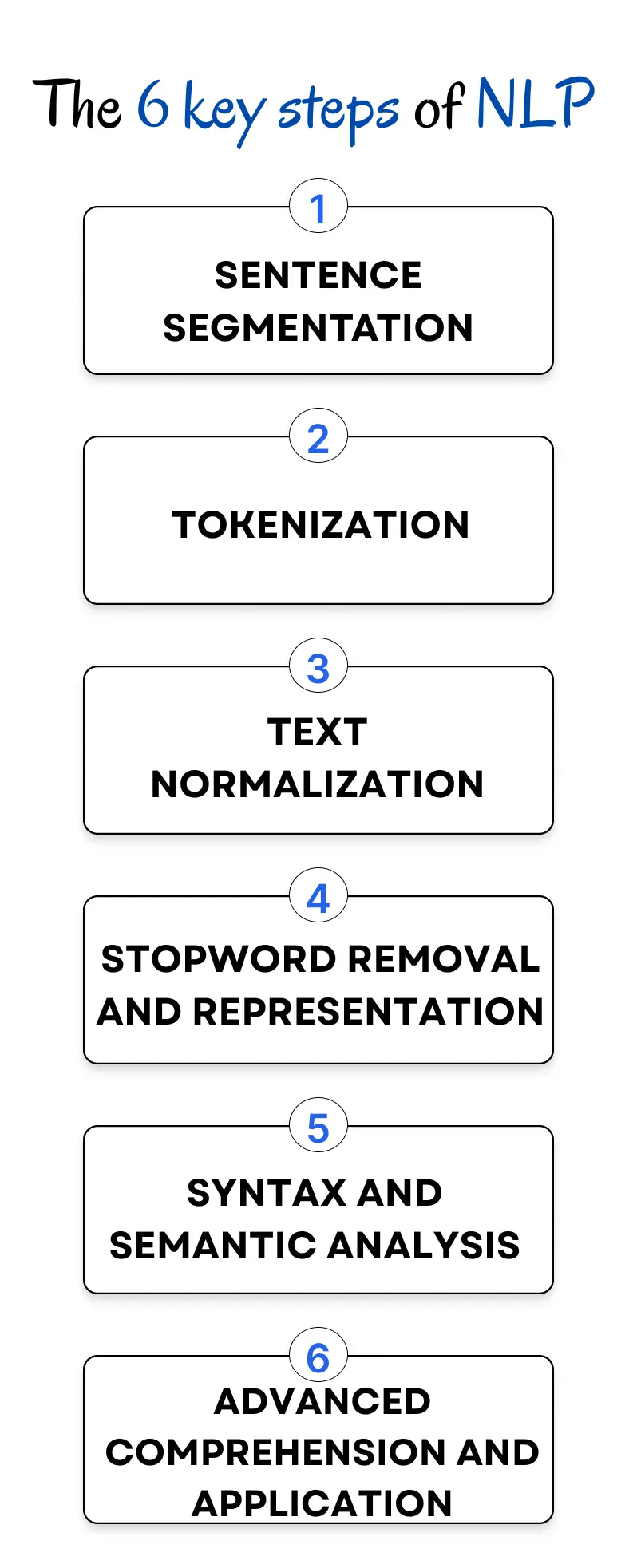
The 6 Stages of NLP Processing
Step
Description
1. Sentence Segmentation
Splitting text into sentences for processing.
2. Tokenization
Breaking sentences into words or sub-words (tokens).
3. Text Normalization
Cleaning and reducing text variability (stemming, lemmatization).
4. Stopword Removal and Representation
Removing common words (“the”, “of”) and converting text into vectors or embeddings.
Applying models for sentiment, summarization, Q&A, or translation.
💡 This is where NLP becomes business-ready — integrated into chatbots, search engines, and OCR document analysis.
Challenges of NLP
Language Ambiguity: Multiple meanings and contexts make disambiguation complex.
Style and Register Diversity: Irony, tone, or idioms are still hard for models to grasp.
Coreference Resolution: Identifying entities that refer to the same subject (“John went home. He was tired.”).
Synonymy and Lexical Variation: Expressing the same idea with different words complicates semantic matching.
When OCR Meets NLP
OCR (Optical Character Recognition) converts scanned or handwritten documents into machine-readable text. However, OCR only reads — NLP understands.
When combined, OCR + NLP enables:
Extraction of key data from invoices, contracts, or forms.
Contextual classification of documents.
Automatic summarization or routing.
In short:OCR digitizes, NLP interprets.
Benefits of Combining OCR and NLP
Enhanced data security and compliance.
Higher accuracy in text interpretation.
Reduced manual processing time.
Lower operational costs and faster insights.
Better decision-making through structured data.
Frequently Asked Questions
What are the most common NLP algorithms?
Transformers like BERT and GPT dominate today’s NLP. Hybrid approaches (RAG: Retrieval-Augmented Generation) improve precision and traceability.
What data is needed to train an NLP model?
A clean, annotated, and representative corpus. Quality and diversity matter more than raw size.
Which industries benefit the most from NLP?
Customer service, finance, law, healthcare, e-commerce, and HR — all involving large-scale text understanding.
Can NLP detect sarcasm or irony?
Partially. Context-based models can identify some cues but remain imperfect — human validation is still advised.
Is NLP compatible with handwritten documents?
Yes, via HCR/ICR (extensions of OCR). Result quality depends on preprocessing and confidence thresholds.
How do you evaluate an NLP model?
Metrics depend on the task: precision/recall/F1 (classification), BLEU (translation), ROUGE (summarization). In production, latency and drift are also tracked.
Speisekarte
Was ist Natural Language Processing? Definition & Anwendungsbeispiele
NLP (Natural Language Processing) allows es systems, text reliable to verstehen and zu produzieren. In diesem Artikel findet ihr die Grundlagen vorgestellt: Definition, Anwendung, Fehler und Verzicht mit OCR für schnellere und genauere Dokumentationsprozesse.
NLP erklärt: Wie Sprachmodelle und OCR zusammen Datenanalyse, Effizienz und Genauigkeit verbessern.
Was ist NLP?
Natural Language Processing(NLP) ist ein Bereich der künstlichen Intelligenz und des maschinellen Lernens, der es ermöglicht, mithilfe linguistischer und statistischer Algorithmen natürliche menschliche Sprache zu verstehen.
Das Hauptziel besteht darin, Maschinen zu befähigen, menschliche Sprache auf eine relevante und nützliche Weise zu verstehen, zu interpretieren und zu erzeugen.
Die meisten Nutzer sind bereits mit NLP in Kontakt gekommen, ohne es zu wissen.
Diese Technologie steht im Zentrum virtueller Assistenten wie Oracle Digital Assistant (ODA), Siri oder Alexa. Sie ermöglicht es ihnen, Benutzeranfragen zu verstehen und in natürlicher Sprache zu antworten. Ebenso nutzen einige Messaging-Anwendungen NLP, um Nachrichteninhalte zu analysieren und automatisch passende Antworten vorzuschlagen.
NLP vs NLU vs NLG: Hauptunterschiede
In der Welt der automatischen Sprachverarbeitung existieren mehrere verwandte Begriffe, die oft für Verwirrung sorgen. NLP (Natural Language Processing), NLU (Natural Language Understanding) und NLG (Natural Language Generation) beziehen sich auf komplementäre Ansätze im Umgang mit natürlicher Sprache.
NLU (Natural Language Understanding) bezeichnet die Fähigkeit von Maschinen, die Struktur und Bedeutung eines Satzes zu analysieren und zu verstehen. Es ist der „Verstehens“-Aspekt, der natürliche Interaktionen mit Computern ermöglicht.
NLG (Natural Language Generation) konzentriert sich auf die Texterzeugung auf Basis von Daten. Man spricht auch von „Language out“: Der Computer erstellt verbale Beschreibungen, Zusammenfassungen oder Erklärungen in einfacher Sprache, oft mithilfe linguistischer Modelle oder Regeln (auch Grammatikgraphen genannt).
NLP (Natural Language Processing) umfasst im weiteren Sinne sowohl das Verstehen als auch die Erzeugung von Sprache. Es ist das ingenieurwissenschaftliche Feld, das Systeme entwickelt, die menschliche Sprache verarbeiten, analysieren und generieren können.
Gleichzeitig bildet die Computerlinguistik (Computational Linguistics – CL) das wissenschaftliche Feld, das die theoretischen und rechnergestützten Aspekte der Sprache untersucht, während sich NLP auf die praktische Anwendung und Lösungserstellung konzentriert.
Die wichtigsten Anwendungen von NLP
Die Verarbeitung natürlicher Sprache deckt ein breites Spektrum an Einsatzmöglichkeiten ab und prägt zunehmend unseren Alltag.
Hier ein Überblick über die bedeutendsten Anwendungsfälle:
Use Case
What NLP Does
Examples
Benefits
Chatbots and Smart Assistants
Interprets questions, detects intent, and responds based on context.
Saves time, ensures editorial consistency, improves content reuse.
Search Enhancement and Online Visibility
Understands search intent and enriches query results.
Internal semantic search, FAQs, SEO optimization.
Better discoverability, faster access to relevant information.
Detection, Filtering, and Moderation
Identifies spam, toxicity, fraud, and misinformation.
Email anti-spam, comment moderation, UGC monitoring.
Safer spaces, regulatory compliance, and higher content quality.
Die 6 Hauptschritte der Sprachverarbeitung (NLP)
Die Verarbeitung natürlicher Sprache folgt einer strukturierten Pipeline aus linguistischen, statistischen und KI-Methoden. Hier sind die zentralen Schritte, um Text in verwertbare Informationen zu verwandeln.
1. Satzsegmentierung
Der Prozess beginnt mit der Segmentierung, die Texte in einzelne Sätze aufteilt. Ein Algorithmus erkennt Satzzeichen, um abgeschlossene Bedeutungseinheiten zu isolieren.
2. Tokenisierung
Die Tokenisierung teilt jeden Satz in Grundelemente, sogenannte Tokens, auf: Wörter, Teilwörter, Zahlen oder Satzzeichen.
3. Normalisierung des Textes
Der Text wird vereinfacht, um sprachliche Variabilität zu reduzieren.
Stemming: Kürzt Suffixe, um die Wortwurzel zu behalten („gegessen“ → „ess“).
Lemmatisierung: Bringt das Wort in seine Grundform zurück („lief“ → „laufen“).
4. Entfernen von Stoppwörtern und Repräsentation
Häufige Wörter, sogenannte Stop Words („und“, „der“, „von“), werden entfernt, da sie wenig Bedeutung tragen.
Dann wird der Text in numerische Daten umgewandelt:
Über ein Bag-of-Words-Modell oder TF-IDF,
Oder über Embeddings (Word2Vec, BERT), die Bedeutung und Kontext erfassen.
5. Syntaktische und semantische Analyse
PoS-Tagging: Weist jedem Wort seine grammatikalische Funktion zu (Substantiv, Verb, Adjektiv...).
Parsing: Ermittelt Satzstrukturen wie Subjekt–Verb–Objekt.
NER (Named Entity Recognition): Erkennt Entitäten wie Personen, Orte oder Organisationen.
6. Erweiterte Verarbeitung und Anwendungen
Stimmungsanalyse (positiv, negativ, neutral),
Automatische Zusammenfassung oder Übersetzung,
Koreferenzauflösung („Hans kam an. Er war müde“ → „Er“ = „Hans“).
Wenn OCR auf NLP trifft
Die OCR (Optical Character Recognition) ist die Technologie, die Bilder mit gedrucktem oder handgeschriebenem Text (z. B. Rechnungen, Verträge, Formulare) in digitalen Text umwandelt.
Dieser Schritt ist entscheidend, um Papierdokumente oder Bilddateien in strukturierte Daten zu konvertieren.
Während OCR sich auf die Texterfassung beschränkt, fügt NLP eine Ebene der Intelligenz und Kontextverarbeitung hinzu – es klassifiziert, kontextualisiert und extrahiert relevante Informationen, um aus Text sofort nutzbare Daten zu machen.
Kurz gesagt: OCR digitalisiert, NLP versteht.
Sécuriser les informations sensibles
Gestion des documents conforme aux normes de confidentialité pour garantir la protection des données et la conformité réglementaire.
Accroître la fiabilité des résultats
Interprétation plus précise des contenus pour limiter les erreurs et améliorer la qualité des analyses produites.
Optimiser les ressources
Automatisation des tâches chronophages pour réduire le temps passé et les coûts opérationnels.
Alléger les tâches répétitives
La machine prend en charge la saisie et les opérations répétitives ; les équipes se concentrent sur des activités à plus forte valeur.
Accélérer l’extraction d’informations
Données récupérées plus vite et de manière structurée, quel que soit le type de document ou la source.
Was die Integration von OCR + NLP ermöglicht
Die Kombination beider Technologien bietet Unternehmen folgende Vorteile:
Schutz sensibler Informationen
Erhöhte Zuverlässigkeit der Ergebnisse
Optimierte Ressourcennutzung
Reduktion repetitiver Aufgaben
Beschleunigte Informationsgewinnung
Häufig gestellte Fragen
What are the most common algorithms used in NLP?
Simple cases still use rule-based or regex approaches, but the standard today relies on machine learning — especially pretrained Transformer networks (BERT, GPT, etc.). Hybrid models that combine retrieval and generation (RAG) are becoming the norm to boost precision and traceability.
What data is needed to train an NLP model?
A clean, representative and diverse dataset, with high-quality annotations aligned to the task. Diversity matters more than raw volume. In sensitive contexts, proper data governance and anonymization are essential.
Which industries benefit the most from NLP today?
Customer service, finance & compliance, legal & insurance, healthcare, e-commerce, marketing, and HR. The common denominator: automating the reading, understanding, and prioritization of large volumes of text.
Can NLP understand irony or sarcasm?
Partially. Models can detect contextual or tonal cues, but performance remains weaker than on factual tasks. For critical decisions, human validation or fallback rules are still recommended.
Is NLP compatible with handwritten documents?
Yes — provided handwriting is first converted to text via HCR or ICR (extensions of OCR). Output quality depends on document preprocessing and confidence thresholds. Targeted human review helps secure ambiguous cases.
How do you measure the quality of an NLP model?
By task: Precision, Recall, and F1 for classification and NER; BLEU/COMET for translation; ROUGE/BERTScore for summarization; Exact Match and F1 for question answering. In production, monitor direct processing rate, human escalation, latency, and data drift — with periodic human reviews for quality assurance.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Mitbegründer von Koncile - Verwandeln Sie jedes Dokument mit LLM in strukturierte Daten - jules@koncile.ai
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.



.webp)


.webp)


.png)


