


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Letzte Aktualisierung:
June 20, 2026
5 Minuten
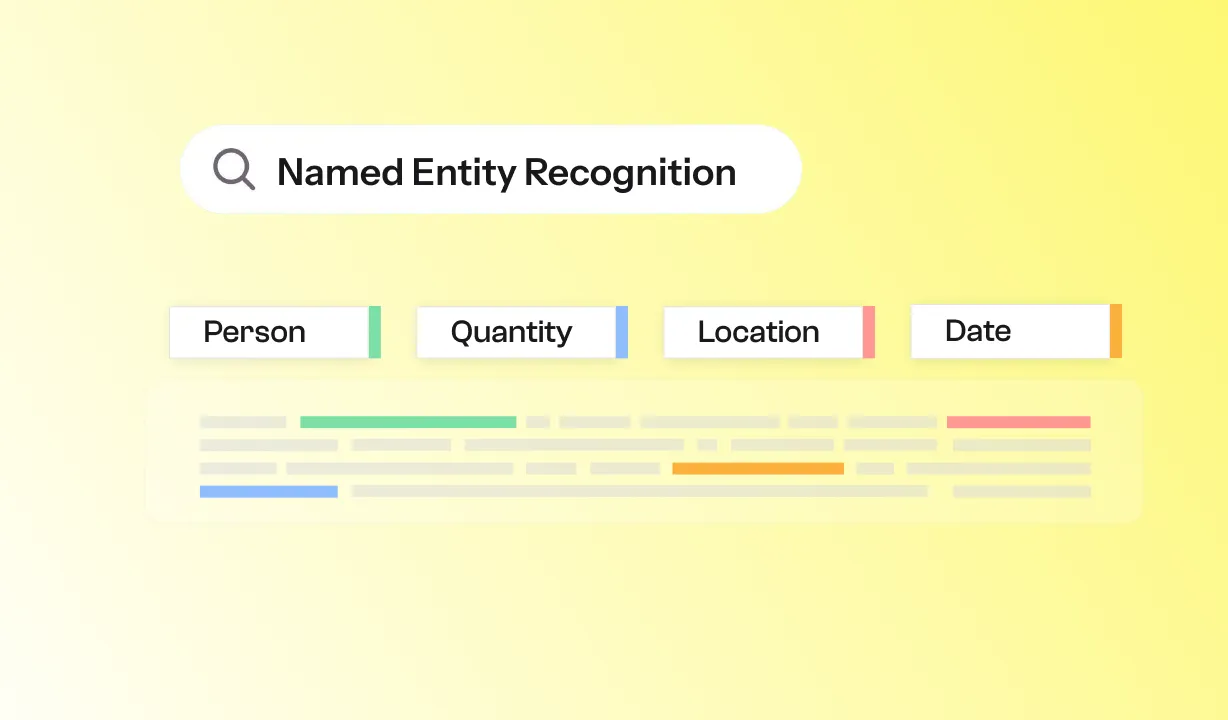
Named Entity Recognition (NER) ermöglicht es, wichtige Informationen in einem Text, wie Namen, Daten oder Beträge, automatisch zu identifizieren. Erfahren Sie, wie es funktioniert und warum es in Projekten zur Dokumentenautomatisierung unverzichtbar geworden ist.
NER erklärt: Wie Sie Informationen aus Texten extrahieren und strukturieren. Nutzen Sie KI für Ihre Daten.
Named Entity Recognition (NER), oder auf Deutsch Erkennung benannter Entitäten, ist eine Technologie aus dem Bereich der automatischen Sprachverarbeitung (NLP).
Sie dient dazu, in einem Fließtext automatisch Schlüsselbegriffe zu identifizieren, wie zum Beispiel:
Das Ziel: unstrukturierte Texte in maschinenlesbare Daten umzuwandeln.
NER funktioniert in zwei Hauptschritten:
Frühe NER-Systeme basierten auf einfachen Regeln oder Fuzzy Matching, bei dem Zeichenketten mit Referenzlisten verglichen werden, wobei kleine Unterschiede (Akzente, Tippfehler, Abkürzungen) toleriert werden.
Diese Ansätze waren in einfachen Fällen nützlich, aber nicht robust genug für komplexe oder verrauschte Kontexte. Heute nutzen moderne Systeme Deep Learning und semantische Embeddings für deutlich präzisere Ergebnisse.
Der NER-Prozess folgt mehreren strukturierten Schritten, die linguistische, statistische und Machine-Learning-Methoden kombinieren:
Zuerst wird der Text in Tokens zerlegt – also Wörter, Satzzeichen, Zahlen usw. Diese Segmentierung ist die Grundlage für die weitere Analyse.
Hier werden Wortgruppen erkannt, die potenziell Entitäten darstellen. Das System nutzt:
Die erkannten Segmente werden mithilfe eines trainierten Modells in Kategorien eingeteilt (Person, Ort, Organisation usw.).
Hier kommen Algorithmen wie CRF (Conditional Random Fields) oder neuronale Netze zum Einsatz.
Der Kontext ist entscheidend, um Mehrdeutigkeiten zu vermeiden. Ein Wort kann je nach Satzbedeutung unterschiedliche Entitäten bezeichnen.
Moderne Modelle wie BERT oder RoBERTa berücksichtigen den gesamten Satzkontext und verbessern so die Disambiguierung.
Am Ende erfolgt eine Verfeinerung der Ergebnisse:
Das Ergebnis kann strukturiert (z. B. als JSON oder XML) exportiert werden – ideal für ERP-, CRM- oder Analyse-Systeme.
Diese Systeme verwenden vordefinierte linguistische Regeln und Muster:
Hier lernt das Modell anhand annotierter Texte, Entitäten zu erkennen.
Neuronale Netze haben NER stark verbessert. Sie lernen direkt aus unstrukturiertem Text:
Viele Systeme kombinieren mehrere Methoden:
Neuere hybride Systeme kombinieren semantische Embeddings mit Fuzzy Matching, um Ähnlichkeiten auch bei leicht abweichenden Schreibweisen zu erkennen.
SchrittEmpfohlene Best PracticesDatenaufbereitungTextbereinigung, Normalisierung, repräsentative AnnotationModellauswahlEinfache Modelle (CRF, SVM) für kleine Aufgaben, BERT/LSTM für komplexeTransfer LearningVortrainierte Modelle (BERT, Flair) feinjustierenFachspezifische AnpassungEigene Wörterbücher, Kombination aus Regeln und KIMehrsprachigkeitMultilinguale oder sprachspezifische Modelle nutzenSicherheitOn-Premise-Deployment, regelmäßige AuditsEinbindung von ExpertenNo-Code-Annotationstools, kontinuierliches Monitoring
Für schnelle Integration oder maßgeschneiderte Projekte eignen sich Open-Source-Bibliotheken oder Cloud-APIs.
NER ist heute ein Kernbestandteil moderner Intelligent Document Processing (IDP)-Lösungen.
Beispiel: Intelligente OCR-Systeme wie Koncile kombinieren Computer Vision, NLP und NER, um strukturierte Geschäftsdaten automatisch zu extrahieren.
Koncile verbindet präzise OCR, kontextuelle Feldextraktion und API-Integration, um Daten in Formaten wie JSON oder Excel bereitzustellen – sofort nutzbar in ERP- oder Buchhaltungssystemen.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


