


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion
.webp)
Letzte Aktualisierung:
March 19, 2026
5 Minuten
Woher wissen Sie, ob es sich bei zwei Aufnahmen um denselben Kunden, Lieferanten oder dasselbe Produkt handelt? In diesem Artikel erfahren Sie, wie der Datenabgleich funktioniert, wichtige Techniken, Markttools und viele konkrete Anwendungsfälle, um das Beste aus Ihren Daten herauszuholen.
Data Matching gleicht Datensätze ab, erkennt Duplikate und sorgt für einheitliche, verlässliche Datenbestände.
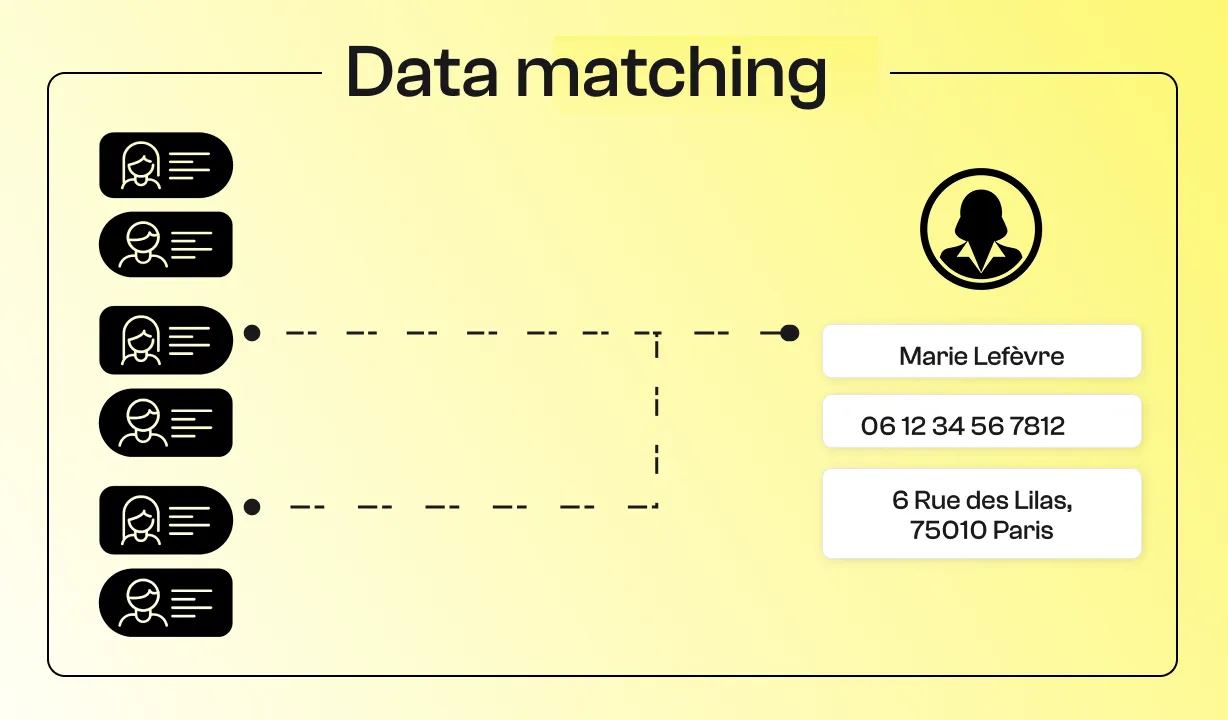
Beim Data Matching oder Datenabgleich werden Datensätze miteinander verglichen, um festzustellen, ob sie sich auf dieselbe reale Entität beziehen (z. B. Person, Unternehmen, Produkt).
Konkret bedeutet das, zu prüfen, ob zwei Datensätze aus unterschiedlichen Quellen dasselbe Objekt beschreiben. So lassen sich Duplikate erkennen oder mehrere Datenbanken verknüpfen, die keinen gemeinsamen Identifikator teilen.
Ohne Data Matching bleiben diese Doppelungen oder Fragmente unbemerkt – mit negativen Folgen für die Datenqualität.

Es gibt verschiedene Matching-Methoden, die je nach Kontext kombiniert werden können, um optimale Ergebnisse zu erzielen.
Beim exakten Matching werden nur identische Werte als Übereinstimmung betrachtet. Diese Methode ist zuverlässig, wenn die Daten standardisiert sind (z. B. eindeutige IDs, Kundencodes).
Schon kleine Unterschiede – Tippfehler, Akzente oder Abkürzungen – führen jedoch zu Fehlvergleichen. Beispiel: „ACME Corporation“ ≠ „ACME Corp.“
➡️ Einfach, aber zu starr für heterogene Daten.
Beim Fuzzy Matching wird ein Ähnlichkeitswert berechnet. Überschreitet dieser einen Schwellenwert (z. B. 80 %), gilt der Vergleich als Treffer.
So werden Tippfehler, Abkürzungen oder Sonderzeichen berücksichtigt: „Société Générale“ ≈ „Societe Generale“.
➡️ Flexibel und effizient, erfordert aber sorgfältige Kalibrierung, um Fehlzuordnungen zu vermeiden.
Diese Methode kombiniert mehrere Kriterien (Name, E-Mail, Datum …) mit Gewichtungen, um eine Gesamtwahrscheinlichkeit für eine Übereinstimmung zu berechnen.
Auch wenn kein Feld identisch ist, kann eine hohe Gesamtsumme ausreichen, um einen Match zu bestätigen.
➡️ Ideal für unvollständige Daten, aber komplexer in der Umsetzung.
Hier werden mehrere Ansätze kombiniert: exakte, unscharfe und probabilistische Methoden. Strikte Regeln werden zuerst angewendet, flexible Verfahren danach.
➡️ Optimales Gleichgewicht zwischen Genauigkeit und Abdeckung.
Ein Modell wird trainiert, um Übereinstimmungen anhand gekennzeichneter Beispiele (Match / No Match) zu erkennen.
Typische Verfahren: Klassifikation, Clustering, neuronale Netze.
➡️ Sehr leistungsfähig bei komplexen Daten, erfordert aber Trainingsdaten und Überwachung.
Data Matching ist entscheidend, um Informationen aus verschiedenen Quellen zu vereinheitlichen, abzugleichen und verlässlich zu verknüpfen. Es verbessert Datenqualität und Entscheidungsfindung.
VorteilBeschreibungDatenqualitätErkennung und Entfernung von Duplikaten, Korrektur von Inkonsistenzen, Vereinheitlichung von Formaten.Einheitliche Sicht (Golden Record)Konsolidierte Daten zu einer Entität (Kunde, Produkt …), bessere Übersicht und Analyse.Intelligentere EntscheidungenVerlässliche Daten verbessern Analysen, Berichte und Prognosen.Betriebliche EffizienzReduziert manuelle Aufgaben, spart Ressourcen, automatisiert Abgleiche.Bessere KundenerfahrungVermeidet Redundanzen, Fehler und doppelte Anfragen. Kunden werden konsistent erkannt.Rechtliche ComplianceUnterstützt DSGVO-Prozesse (Zugriff, Löschung), minimiert Risiken und erleichtert Betrugserkennung.DatenanreicherungKombination interner und externer Quellen für umfassendere Erkenntnisse.
Bereinigung der Daten: unnötige Zeichen entfernen, Fehler korrigieren, Formate vereinheitlichen.
Felder werden in ein einheitliches Format gebracht (z. B. Datum im ISO-Format, Telefonnummern international).
Erstellung von Suchschlüsseln, um Vergleiche auf relevante Gruppen zu beschränken und den Prozess zu beschleunigen.
Anwendung verschiedener Vergleichsmethoden: exakte Übereinstimmung, Textähnlichkeit (Levenshtein), phonetische Verfahren (Soundex).
Festlegung und Anpassung eines Ähnlichkeitsschwellenwerts, um Balance zwischen Präzision und Abdeckung zu gewährleisten.
Der Markt bietet viele Tools zur Automatisierung des Data Matchings:
Um verlässliche Ergebnisse zu erzielen, sollten typische Herausforderungen beachtet werden:
HerausforderungBeschreibungDatenqualitätFehlende oder fehlerhafte Daten beeinträchtigen die Genauigkeit.Komplexe KonfigurationSchwellenwerte müssen präzise eingestellt werden, um Fehlzuordnungen zu vermeiden.MehrdeutigkeitenHomonyme oder unvollständige Informationen erfordern manuelle Überprüfung.DatenvolumenGroße Datenmengen erfordern optimierte Indexierung und Parallelverarbeitung.QuellenheterogenitätUnterschiedliche Sprachen und Formate erschweren den Abgleich.ComplianceEinhalten von Datenschutzrichtlinien (DSGVO, Auditierbarkeit, Nachvollziehbarkeit).
KontextAnwendungErgebnisE-Mail-MarketingDuplikaterkennung in Kontaktlisten („Jean Dupont“ / „Dupond Jean“).Saubere Datenbank, bessere Zustellraten.E-CommerceProduktabgleich trotz unterschiedlicher Bezeichnungen.Synchronisierte Kataloge, präzisere Preisvergleiche.Kundenfusion nach AkquisitionZusammenführung mehrerer Kundendatenbanken.Einheitliche Sicht auf den Kundenstamm.Betrugserkennung im BankwesenIdentifikation verdächtiger Doppelungen.Automatische Warnungen und Betrugsprävention.BuchhaltungAutomatischer Abgleich zwischen Rechnung, Bestellung und Lieferant.Weniger Fehler, schnellerer Prozess.
Die Wahl hängt von Datenart, Volumen und Komplexität ab:
Sie misst den Prozentsatz korrekt erkannter Übereinstimmungen durch KI – ein zentraler Leistungsindikator für Matching-Systeme.
Es ist der Prozess, bei dem verstreute Informationen zu einer Entität zu einem einheitlichen Datensatz zusammengeführt werden.
Matching verknüpft ähnliche Daten; Data Mining analysiert sie, um Erkenntnisse zu gewinnen.
Nicht vollständig, aber teilweise: Durch Kombination mehrerer Felder kann eine zuverlässige Identifikation simuliert werden.
Etwa 90 % für hohe Genauigkeit, 80 % für breitere Abdeckung – je nach Anwendungsfall anpassbar.
Nutzer können Matches bestätigen oder korrigieren. Diese Rückmeldungen helfen, das System kontinuierlich zu verbessern.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Tristan Thommen entwirft und implementiert die technologischen Bausteine, die unstrukturierte Dokumente in nutzbare Daten umwandeln. Es kombiniert KI, OCR und Geschäftslogik, um das Leben von Teams zu vereinfachen.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


