


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Letzte Aktualisierung:
March 6, 2026
5 Minuten
OCR-Technologien (Optical Character Recognition) werden seit langem verwendet, um gedruckte Dokumente in nutzbaren Text umzuwandeln. Doch mit der Einführung von Sprachmodellen (LLM) verändert eine neue Generation von OCR die Standards. Diese intelligenteren Systeme extrahieren nicht nur Text: Sie verstehen den Kontext, korrigieren Fehler und interpretieren Daten mit beispielloser Präzision. Warum übertreffen diese LLM-basierten OCRs also die Klassiker? Welche Vorteile bieten sie Unternehmen und Benutzern? Lassen Sie uns diesen technologischen Fortschritt gemeinsam entschlüsseln.
LLM-basierte OCR liefert präzisere Ergebnisse und verarbeitet komplexe Dokumente schneller als klassische Systeme.

Traditionelle OCR (Optical Character Recognition) wurde ursprünglich entwickelt, um den Text eines Bildes oder einer PDF-Datei präzise zu transkribieren und ihn in nutzbare digitale Zeichen umzuwandeln.
Mit anderen Worten: Eine klassische OCR erzeugt reinen Text und erfordert anschließend zusätzliche Verarbeitung (Regeln, Skripte oder spezifische Modelle), um relevante Informationen (Beträge, Daten, Schlüsselfelder usw.) zu identifizieren.
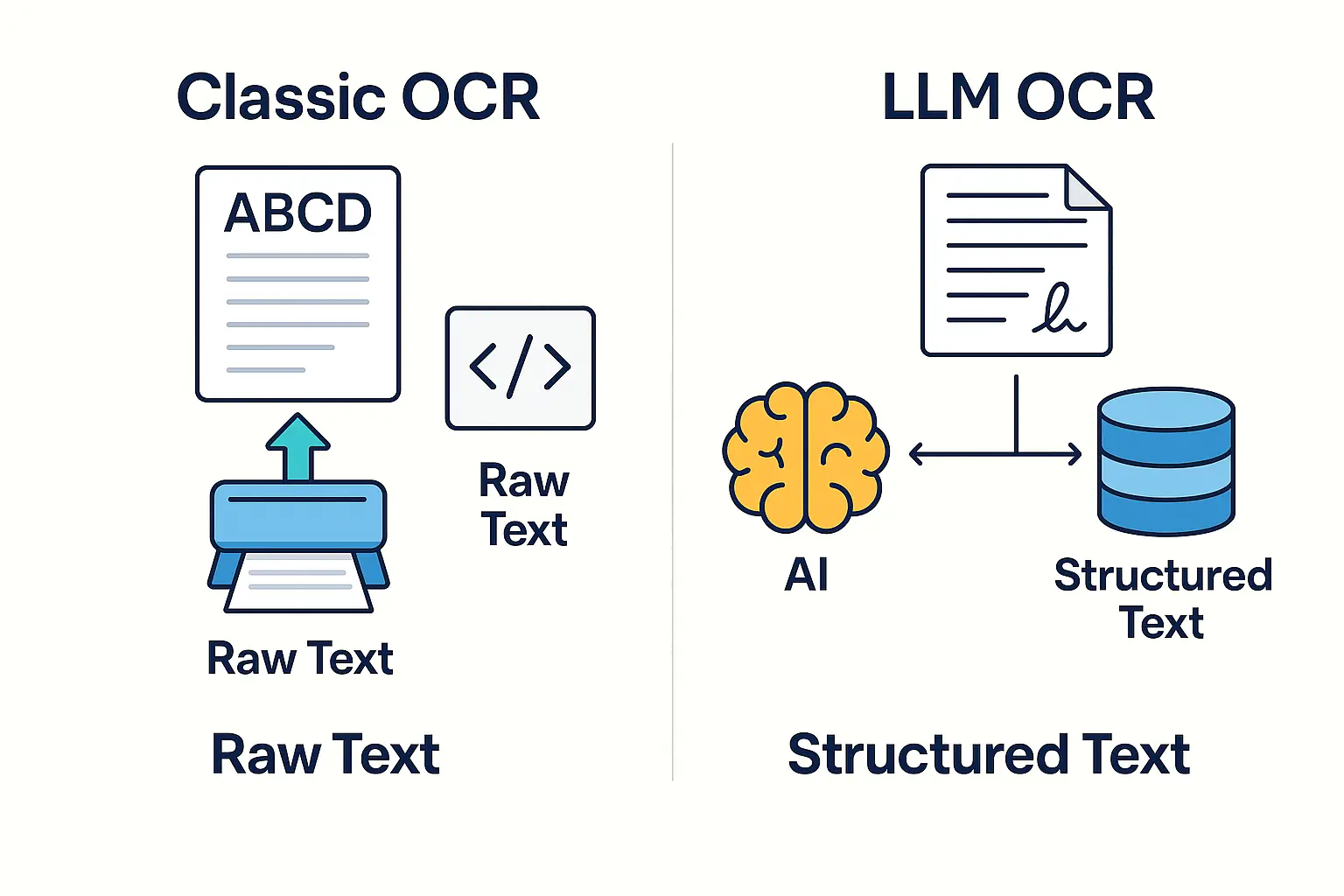
LLM-basierte OCR-Lösungen (Large Language Models) gehen dagegen weit über die einfache Transkription hinaus.
Dank KI kann die neue Generation von OCR-Systemen Inhalte verstehen und gezielte Daten direkt extrahieren. Man geht von der reinen Zeichenerkennung zur inhaltlichen Dokumentenverständnis über.
Bei einer Rechnung zum Beispiel erkennt sie sofort den zu zahlenden Gesamtbetrag, den Namen des Lieferanten, das Datum, die Bestellpositionen, die USt-ID usw., anstatt einfach nur den gesamten Text roh auszulesen.
Kurz gesagt: Die Kombination aus OCR und LLM vereint visuelles Erkennen und intelligente Sprachanalyse in einem einzigen Prozess, während klassische OCR auf die reine Texterfassung beschränkt bleibt.
Die eigentliche Stärke von Sprachmodellen (LLM), wenn sie auf OCR angewendet werden, liegt in ihrer Fähigkeit, den globalen Sinn eines Dokuments zu verstehen. Während eine klassische OCR nur Zeichen und Wörter erkennt, interpretiert ein LLM den Inhalt im Kontext.
Ein konkretes Beispiel:
In einer Lieferantenrechnung liest eine typische OCR:
„Zwischensumme: 1.250 EUR“
„MwSt (20 %): 250 EUR“
„Gesamtbetrag: 1.000 EUR“
Hier ist die Zeichenerkennung korrekt – aber der Gesamtbetrag ist inkonsistent: 1.250 + 250 = 1.000 stimmt nicht.
Eine klassische OCR reagiert nicht, da sie nur die Zeilen extrahiert.
Ein LLM hingegen versteht die logische Struktur des Dokuments: Es weiß, dass der Gesamtbetrag der Summe aus Netto und MwSt entsprechen muss. Es erkennt automatisch die Unstimmigkeit und kann sie entweder korrigieren oder als Anomalie melden.
Ein weiteres Beispiel – auf einer Gehaltsabrechnung:
Klassische OCR liest:
„Bruttogehalt: 3.210 €“
„Rentenbeitrag: 321 €“
„Steuerpflichtiger Nettobetrag: 4.120 €“
Ein LLM versteht die Beziehungen zwischen den Feldern und weiß, dass das Nettogehalt nicht höher als das Bruttogehalt sein kann. Es setzt die Werte in Beziehung, erkennt Anomalien und reagiert entsprechend.
Mit OCR-Systemen, die durch LLMs unterstützt werden, wird die Datenerfassung deutlich präziser. Diese Modelle erreichen Zuverlässigkeitsraten von bis zu 98–99 % bei Standardtexten, wo klassische OCRs bei etwa 95 % liegen. Das bedeutet: weniger Lesefehler, weniger manuelle Nacharbeit.
Die Extraktion ist außerdem gezielt und kann individuell an Ihre Bedürfnisse angepasst werden. Statt Ihnen den gesamten Dokumententext zu liefern, kann LLM-basierte OCR nur die Felder extrahieren, die Sie wirklich benötigen.
Sie „versteht“ die Anfrage. Wenn Ihr Unternehmen nur den Gesamtbetrag, das Datum und die Bestellnummer aus einer Rechnung erfassen will, fokussiert sich das System genau auf diese Elemente und gibt sie strukturiert aus.

Da Sprachmodelle (LLM) auf riesigen mehrsprachigen Datensätzen trainiert werden, sind OCR-Lösungen, die auf dieser Technologie basieren, von Natur aus mehrsprachig. Dies ist ein großer Fortschritt gegenüber klassischen OCRs, die oft nur eine Sprache gleichzeitig verarbeiten oder für jede Sprache neu konfiguriert werden müssen.
Mit LLMs kann ein einziges System einen Vertrag auf Französisch, eine Rechnung auf Englisch, einen Pass auf Arabisch und ein Verwaltungsdokument auf Chinesisch lesen – ohne Modellwechsel oder Qualitätsverlust.
Bereits 2025 unterstützen einige intelligente LLM-basierte OCR-Plattformen über 80 Sprachen, einschließlich nicht-lateinischer Alphabete und komplexer Schriftzeichen.
Für internationale Unternehmen ist der Vorteil sofort spürbar: Es muss keine separate Software pro Land mehr eingesetzt werden.
Diese sprachliche Flexibilität ermöglicht die Zentralisierung der Dokumentenverarbeitung weltweit, senkt Sprachkosten und gewährleistet eine einheitliche Extraktionsqualität über alle Märkte hinweg.

Ein Dokument besteht nicht nur aus Text – es hat auch eine visuelle Struktur: Spalten, Tabellen, Titel, Kästen, Formulare usw., die der Mensch intuitiv erkennt.
Doch klassische OCR-Systeme haben mit dieser Dimension Schwierigkeiten. Sie lesen meist linear, was zu Interpretationsfehlern führen kann, etwa beim Erkennen mehrspaltiger Inhalte oder Tabellen ohne manuelle Anpassung.
Mit dem Aufkommen multimodaler LLMs, die Computer Vision und Sprachverarbeitung kombinieren, entfällt diese Einschränkung.
Ein Beispiel: Lieferantenrechnungen mit unterschiedlichen Layouts. Während eine klassische OCR für jedes Format ein eigenes Template benötigt, erkennt ein LLM intuitiv die Schlüsselinformationen – Rechnungsnummer, Datum, Gesamtbetrag – unabhängig vom Layout.
Diese Fähigkeit erstreckt sich auch auf komplexe Dokumente wie Finanzberichte, Formulare mit Auswahlkästchen oder Kreuztabellen. Dank fortgeschrittener struktureller Segmentierung werden Daten präzise extrahiert, wobei ihr visueller und logischer Kontext erhalten bleibt.
Mit dem Einzug der LLMs wird OCR zu einem individuell anpassbaren Dienst. Oft genügt es, in natürlicher Sprache zu beschreiben, was extrahiert werden soll – und das Modell übernimmt den Rest.
Sie müssen lediglich angeben:
Die KI versteht Ihre Absicht, identifiziert die richtigen Felder und extrahiert sie ohne vorherige Konfiguration.
Dieser Ansatz – „Prompt + Extraktion“ – ermöglicht es, sofort zwischen Dokumenttypen zu wechseln, ob Bestellung, Angebot, Kontoauszug oder HR-Bericht.
Gleichzeitig ist die Integration vereinfacht: Die meisten LLM-Plattformen bieten einsatzbereite APIs.
Das Lesen von Handschrift war lange die Schwachstelle der OCR.
Zwischen Stilvariationen, schlecht gescannten oder qualitativ schwachen Dokumenten lagen die Fehlerquoten konventioneller Systeme hoch, besonders bei Kursivtexten.
Mit LLMs ändert sich das grundlegend. Durch die Verbindung von visueller Erkennung und Sprachverständnis erreichen sie heute eine Treffsicherheit von 80–85 % bei gut lesbarer Handschrift – gegenüber etwa 64 % bei klassischen OCRs (Octaria, 2025).
Diese Leistung beruht auf der Fähigkeit, den Sinn eines Wortes aus dem Kontext abzuleiten. Selbst wenn Buchstaben unklar sind, nutzt das Modell den Zusammenhang, um die wahrscheinlichste Bedeutung zu bestimmen – ähnlich wie ein Mensch beim Lesen.
Zwar bleiben Grenzen bei extrem schlechter Qualität, doch ein klarer Fortschritt ist erreicht. Handausgefüllte Formulare, interne Notizen, Briefe oder Kundenkommentare werden endlich zugänglich, analysierbar und nutzbar – ohne manuelle Eingabe.
Für Unternehmen ist der Effekt direkt messbar: Ganze Bestände bisher unbrauchbarer Dokumente können digitalisiert, indexiert und integriert werden. Was einst Science-Fiction war, wird dank LLMs zum neuen Standard.
Datenextraktion bedeutet auch effiziente Weiterverarbeitung. Hier bieten LLM-gestützte OCRs eine noch nie dagewesene Flexibilität – beim Input wie beim Output.
Ob gescanntes PDF, Smartphone-Foto, E-Mail-Anhang oder mehrseitige Datei – das Tool verarbeitet die Inhalte direkt, ohne vorherige Konvertierung.
Auf der Ausgabeseite liegt die Revolution in der freien Wahl der Ausgabeformate. Statt einfachem Text können Ergebnisse exakt im passenden Format exportiert werden: Excel-Tabelle, CSV, JSON, XML oder direkt via API in ERP, CRM oder Datenbanken.
Jeder Lieferant hat ein anderes Layout:
Ein LLM-gestütztes OCR versteht sofort, dass es sich um eine Rechnung handelt, und findet die Schlüsselangaben unabhängig vom Format. Totals und Daten werden korrekt lokalisiert, auch wenn ihre Position variiert.
Dank LLM-Vision werden Produktzeilen (Menge, Einheitspreis etc.) konsistent und tabellarisch extrahiert.
Diese langen, komplexen Dokumente profitieren stark vom Einsatz von LLMs.
Ein Vertrag über mehrere Dutzend Seiten enthält:
Eine klassische OCR liefert nur Text, ohne Kontext. Ein LLM dagegen verwandelt den Vertrag in eine durchsuchbare Datenbank.
Das System kann Fragen beantworten wie:
Solche intelligenten Assistenten entlasten Rechts- und Einkaufsteams und senken das Risiko von Interpretationsfehlern.
Hier werden gedruckter Text, handschriftliche Ergänzungen oder gescannte Elemente kombiniert.
Beispiel: ein Antragsformular mit gedrucktem Kopf und handschriftlichen Antworten oder ein PDF mit Foto und Unterschrift.
Klassische OCRs scheitern an solchen Mischformen. Multimodale LLMs verarbeiten das gesamte Formular in einem Durchgang – sowohl getippten als auch handgeschriebenen Text.
Besonders wertvoll ist dies in Branchen wie Logistik (Lieferscheine), Gesundheitswesen (Patientenbögen) oder HR (Onboarding-Formulare).
So wird die Verarbeitung beschleunigt, die Datenqualität erhöht und manuelle Ausnahmen entfallen. Selbst schwer lesbare Passagen werden durch kontextuelles Verständnis zuverlässig erkannt.
Die Verbindung von Computer Vision und Sprachmodellen verwandelt OCR in einen intelligenten Assistenten – weit über reine Texterfassung hinaus.
Das neue Paradigma ermöglicht es nicht nur, ein Dokument zu lesen, sondern auch damit zu interagieren: Texte zusammenfassen, Unterschiede erkennen, kritische Bereiche markieren.
Beispiele möglicher Interaktionen:
Dieser intelligente Dokumentenassistent spart Zeit, erhöht die Entscheidungsqualität und macht Datenverarbeitung zuverlässiger.
Der Einsatz von LLM-basierten OCRs bedeutet einen Qualitätssprung im Dokumentenmanagement.
Auf der Produktivitätsseite ist der Effekt sofort: Stundenlange Eingabe- und Prüfvorgänge werden in Sekunden automatisiert. Dokumentenmengen sind kein Hindernis mehr – Prozesse bleiben effizient, auch bei Spitzenlast.
Auf der Zuverlässigkeitsseite reduziert Automatisierung Tippfehler, Auslassungen oder Zahlenvertauschungen. Ergebnisse werden standardisiert und global konsistent.
Darüber hinaus kann eine LLM-basierte OCR automatisch warnen, wenn Ink
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


