


.webp)
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Letzte Aktualisierung:
March 19, 2026
5 Minuten
Erfahren Sie schnell, wie Sie Dokumente, die Tabellen, zeilenweise Daten oder andere komplexe Strukturen enthalten, in Daten umwandeln, die in Tabellenkalkulationen oder Excel verwendet werden können. Wandeln Sie unstrukturierte Informationen in organisierte, verwertbare Daten um.
Tabellen aus Scans zu extrahieren ist schwierig. Erfahren Sie, wie KI-OCR Fehler reduziert und Workflows beschleunigt.

Finanz- und Buchhaltungsdaten sind oft in verstreuten Tabellen in PDF-Dateien oder Bildern versteckt, was den Zugriff und die Analyse erschwert.
Dank künstlicher Intelligenz und optischer Zeichenerkennung (OCR) Technologien, ist es jetzt möglich, diese Informationen automatisch zu extrahieren und zu strukturieren, auch wenn sie nicht als auswählbarer Text verfügbar sind.
Diese Art der Automatisierung ist Teil eines umfassenderen Ansatzes, der als intelligente Dokumentenverarbeitung bekannt ist und OCR, KI und Geschäftsregeln kombiniert, um Dokumente in großem Umfang zu verarbeiten.
Nach der Extraktion können diese Daten so organisiert werden, dass ihr Wert maximiert wird, was Kosteneinsparungen, Fehlererkennung und ein effizienteres Kostenmanagement ermöglicht.
In diesem Artikel untersuchen wir die wichtigsten Techniken zum Erkennen und Extrahieren von Tabellen aus Dokumenten sowie praktische Tipps, die Ihren Entwicklern helfen, diese Lösungen in Ihren Projekten zu implementieren.
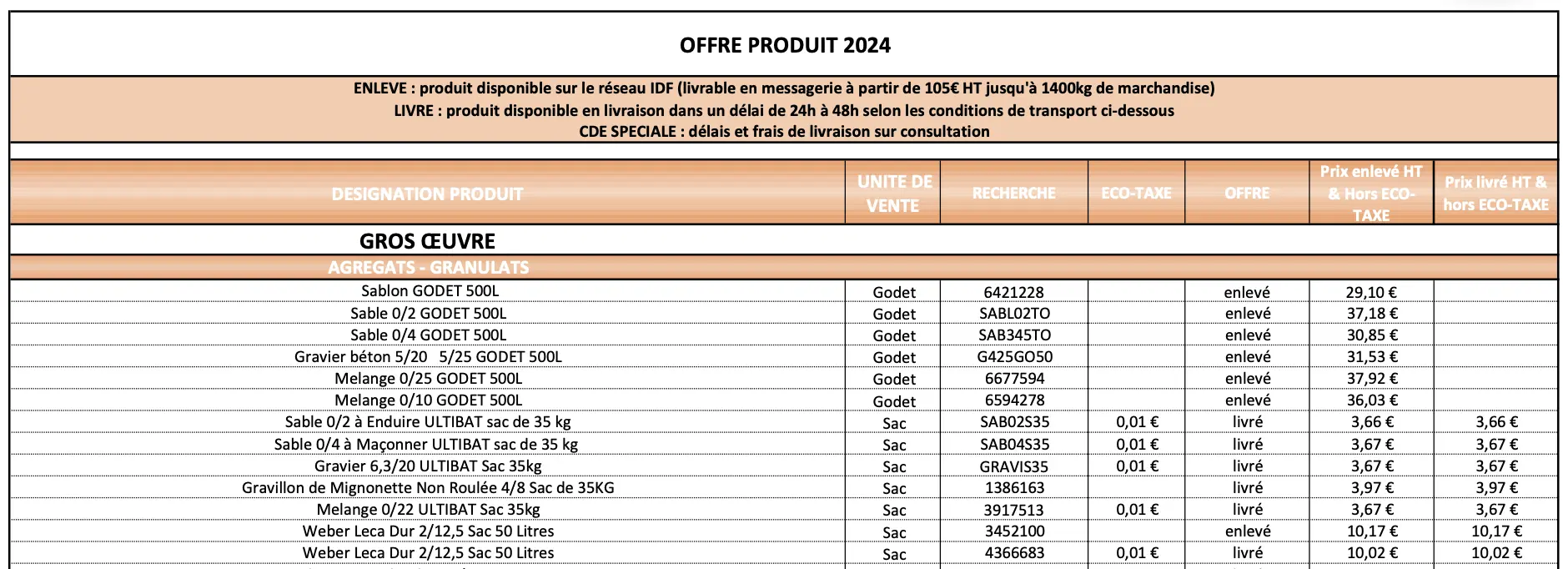
Heute ist es möglich, Daten aus diesen Tabellen zu extrahieren und zu strukturieren, um sie optimal zu nutzen: Einsparmöglichkeiten, Fehlererkennung, Kostenmanagement.
Wir stellen die wichtigsten Techniken der künstlichen Intelligenz vor, die zum Erkennen und Extrahieren von Tabellen aus Dokumenten verwendet werden, sowie praktische Tipps, die Ihren Entwicklern helfen, diese Lösungen in Ihren eigenen Projekten zu implementieren.
Computer Vision spielt eine entscheidende Rolle bei der Tabellenerkennung. Zu den gängigen Methoden gehört die Verwendung von Convolutional Neural Networks (CNN) zur Identifizierung tabellarischer Strukturen in Dokumenten. Diese Netzwerke können anhand von beschrifteten Datensätzen trainiert werden, um zu lernen, wie man Tabellenränder und Zellen erkennt.
Schlüsseltechnik: YOLO (You Only Look Once)
Sobald die Tabellen erkannt wurden, besteht der nächste Schritt darin, sie zu extrahieren und zu verstehen. NLP-Techniken werden verwendet, um die in den Tabellen enthaltenen Daten zu interpretieren und sie auf nutzbare Weise zu strukturieren.
Schlüsseltechnik: Transformatormodelle (z. B. BERT, GPT)
Die Kombination von Computer Vision und NLP führt zu robusteren Ergebnissen. Bei Koncile verwenden wir CNNs, um Tabellenbereiche zu identifizieren, gefolgt von Transformatormodellen, um den Inhalt semantisch zu strukturieren, der das Rückgrat unserer OCR-Datenextraktionssoftware.
Ein gängiger Ansatz besteht beispielsweise darin, mithilfe von Computer Vision Tabellen zu erkennen und dann NLP-Techniken anzuwenden, um die Daten zu extrahieren und zu strukturieren.
Beispiel für einen kombinierten Ansatz bei Koncile
Die Qualität der Trainingsdaten ist entscheidend für die Leistung des KI-Modells. Stellen Sie sicher, dass Sie über einen vielfältigen und gut beschrifteten Datensatz verfügen. Fügen Sie verschiedene Arten von Dokumenten und Tabellenformaten hinzu, um Ihr Modell robuster zu machen.
Teilen Sie Ihren Datensatz in Trainings- und Validierungssätze auf. Verwenden Sie Kreuzvalidierungstechniken, um die Leistung Ihrer Modelle zu bewerten und Überanpassungen zu vermeiden.
Sobald Ihre Modelle trainiert sind, optimieren Sie sie für die Verwendung in Echtzeit, indem Sie die Modellgröße reduzieren oder die GPU-Beschleunigung nutzen. In Finanzprozessen können diese Tools die OCR-gestützte Buchhaltung unterstützen und dabei helfen, Kontoabgleiche, Steuererfassungen und Spesenabrechnungen zu automatisieren. Dies kann die Komprimierung von Modellen umfassen, um sie leichter und schneller zu machen, sowie die Einrichtung robuster Infrastrukturen, die den Anforderungen in Echtzeit gerecht werden.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Jules leitet die Produktentwicklung bei Koncile und konzentriert sich darauf, wie unstrukturierte Dokumente in Geschäftswert umgewandelt werden können.
Ressourcen von Koncile
Dokumenten-Deepfakes bestehen klassische Prüfungen: So erkennen Sie KI-generierte Fälschungen 2026 mit semantischer Kohärenzanalyse.
Funktion

Zehn Lösungen zur Dokumentenbetrugserkennung im Vergleich: Erkennungsansatz, abgedeckte Betrugsarten, Integration und Zielprofil.
Komparative

Zehn Plattformen zur Automatisierung der Kreditorenbuchhaltung im Vergleich: KI-Agenten, Betrugserkennung, Integration und Zielprofil, von etablierten Enterprise-Anbietern bis zu AI-nativen Challengern.
Komparative
.png)


