



Fehler und Betrug in Lieferantenrechnungen automatisch erkennen, POs und Preislisten abgleichen und versteckte Kosten senken.
Fallstudien
.webp)
Letzte Aktualisierung:
November 5, 2025
5 Minuten
ETL-Lösungen spielen eine zentrale Rolle bei der Vereinfachung der Verwaltung, Bereinigung, Anreicherung und Konsolidierung von Daten aus einer Vielzahl von Quellen. In diesem Blogbeitrag werden wir anschaulich erklären, was ETL ist, welchen Prozess es hat, welche Vorteile es für Unternehmen bringt, konkrete Anwendungsbeispiele sowie einen Überblick über einige beliebte ETL-Tools mit ihren jeweiligen Vorteilen geben.
ETL ermöglicht das Extrahieren, Transformieren und Laden von Daten, um sie nutzbar zu machen. Dieser umfassende Leitfaden hilft Ihnen, die Herausforderungen, Schritte und Marktlösungen zu verstehen.

ETL, Abkürzung für Extrahieren, Transformieren, Laden (auf Französisch: Extrahieren, Transformieren, Laden) bezieht sich auf einen Datenintegrationsprozess, der mehrere Operationen kombiniert.
Konkret geht es um Daten aus mehreren Quellen sammeln, dann bereinigen und organisieren um sie in ein kohärentes Ganzes umzuwandeln, bevor in einem Zielsystem zentralisieren wie ein Data Warehouse oder ein Datensee.
Mit anderen Worten, ETL nimmt verstreute Rohdaten und wandelt sie in strukturierte und homogene Informationen um, die vom Unternehmen verwendet werden können (sei es für Analysen, Berichte oder Geschäftsanwendungen).
Der Prozess ETL (Extrahieren, Transformieren, Laden) basiert auf drei aufeinanderfolgenden Schritten, die es ermöglichen, Rohdaten aus verschiedenen Quellen in strukturierte, zuverlässige und gebrauchsfertige Informationen umzuwandeln.
.png)
Diese Schritte werden in der Regel über automatisierte Pipelines orchestriert.
Der erste Schritt ist Daten aus einer oder mehreren Quellen extrahieren, ob intern (Datenbanken, ERP, CRM, CRM, Excel-Dateien, Geschäftsanwendungen) oder extern (API, offene Daten, Dienste von Drittanbietern). Daten können strukturiert, halbstrukturiert oder unstrukturiert sein.
Sie werden dann temporär gespeichert in einem Transitzone vor der Behandlung. Es gibt mehrere Extraktionsmethoden:
Extrahierte Daten sind nicht immer einsatzbereit. Die Transformationsphase zielt darauf ab machen Sie sie zuverlässig und passen Sie sie an geschäftliche oder technische Anforderungen an des Zielsystems.
Es beinhaltet verschiedene Operationen:
Diese Phase ist unerlässlich, um eine hochwertige, konsistente und nutzbare Daten.
Nach der Transformation sind die Daten in eine Zieldatenbank geladen, in der Regel ein Data Warehouse oder ein Datensee, von wo aus sie für Analysen, Dashboards oder Algorithmen für maschinelles Lernen verwendet werden können.
Es sind mehrere Strategien möglich:
Sobald dieser Schritt abgeschlossen ist, sind die Daten zentralisiert, zugänglich und sofort einsatzbereit für Business Intelligence-Tools, Berichte oder Prognosemodelle.
Einige Experten ziehen es vor, den ETL-Prozess zu unterteilen in fünf verschiedene Schritte um den gesamten Datenvalorisierungszyklus besser widerzuspiegeln
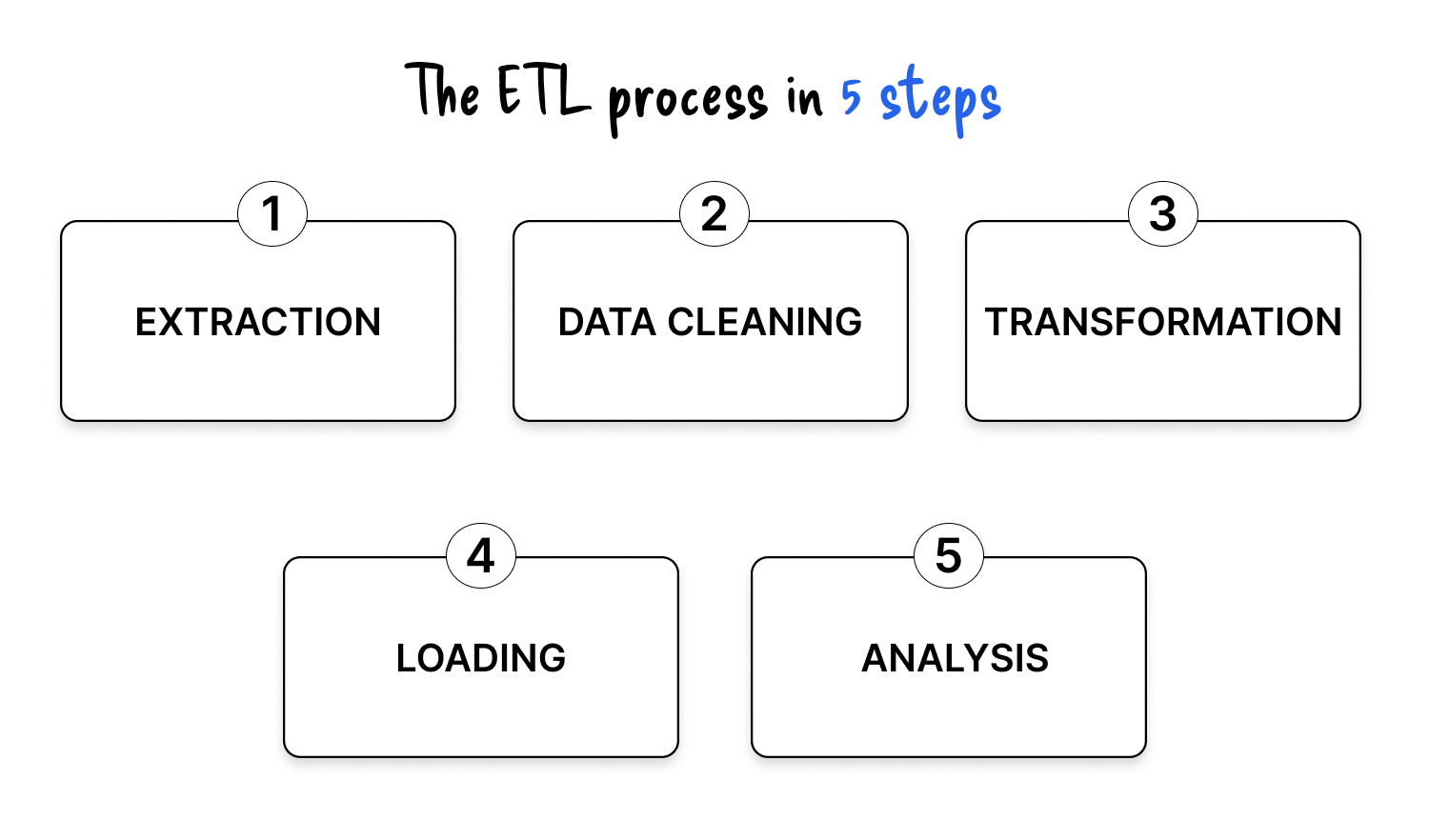
ETL ist an zahlreichen technischen und geschäftlichen Datenprojekten beteiligt.
Hier sind die wichtigsten Situationen, in denen ETL in der Praxis eingesetzt wird.
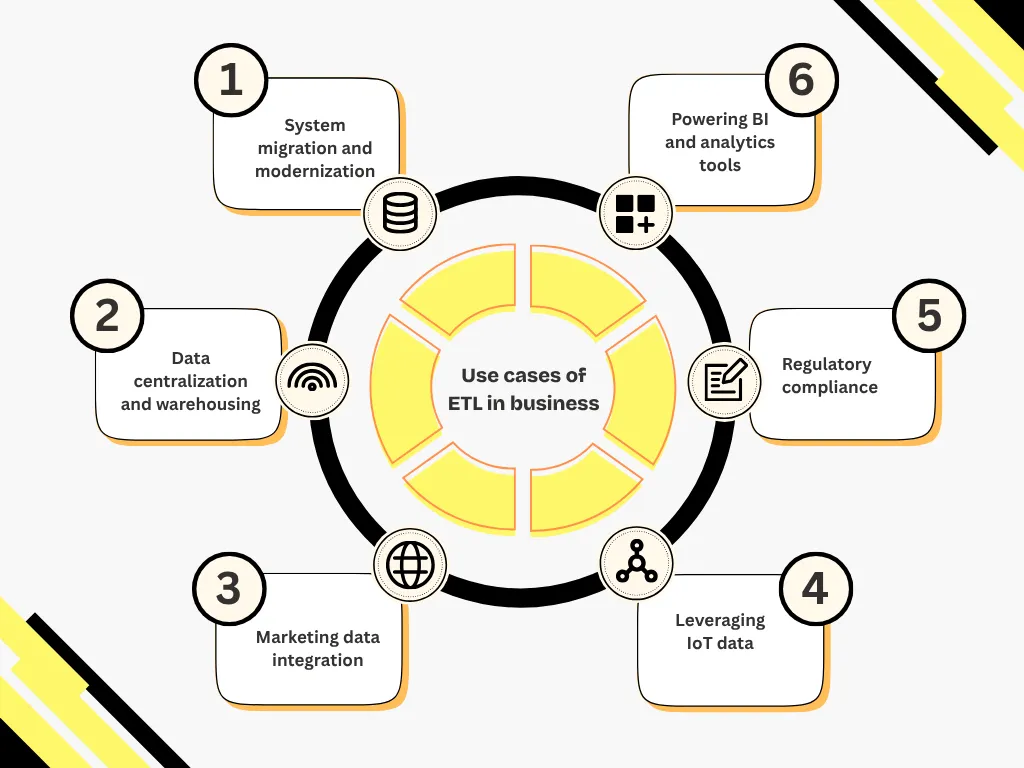
ETL ist unverzichtbar, wenn ein vorhandenes System ersetzt oder auf eine neue Infrastruktur umgestellt wird. Es ermöglicht die Migration von Daten aus alten Anwendungen (Altsystemen), das Laden von Daten in moderne Cloud-Umgebungen oder das Synchronisieren mehrerer Datenbanken ohne Betriebsunterbrechung.
Um ein Data Warehouse zu versorgen, ruft ETL Informationen aus heterogenen Quellen (ERP, CRM, Dateien, API usw.) ab, standardisiert und zentralisiert sie. Die auf diese Weise aufbereiteten Daten können dann für Queranalysen und konsolidierte Berichte verwendet werden.
ETL spielt eine Schlüsselrolle bei der Strukturierung von Kundendaten aus verschiedenen Kanälen: E-Commerce, soziale Netzwerke, E-Mail-Kampagnen, CRM usw. Es ermöglicht es, eine einheitliche Sicht auf die Kundenreise zu erstellen, die Marketingsegmentierung zu optimieren und personalisierte Aktionen auszulösen.
In industriellen oder logistischen Umgebungen erzeugen vernetzte Objekte erhebliche Mengen an technischen Daten. ETL erleichtert die Wiederherstellung, Standardisierung und Anreicherung dieser Daten, um sie für Anwendungsfälle wie vorausschauende Wartung oder Leistungsoptimierung nutzbar zu machen.
ETL trägt zur Einhaltung von Vorschriften wie GDPR, HIPAA oder CCPA bei. Es ermöglicht die Identifizierung, Filterung oder Anonymisierung bestimmter sensibler Daten und gewährleistet gleichzeitig deren Rückverfolgbarkeit und Integrität, insbesondere bei Audits oder Kontrollen.
Schließlich garantiert ETL den Geschäftsteams den nahtlosen Zugriff auf zuverlässige, aktuelle Daten, die zur Analyse bereit sind. Es unterstützt Business Intelligence-Tools, Dashboards oder Prognosemodelle, indem die Datenaufbereitung im Voraus automatisiert wird.
Neben der technischen Automatisierung spielt der ETL-Prozess eine strukturierende Rolle bei der Leistung von Geschäftsdaten. Hier sind die wichtigsten konkreten Vorteile, die er bietet.
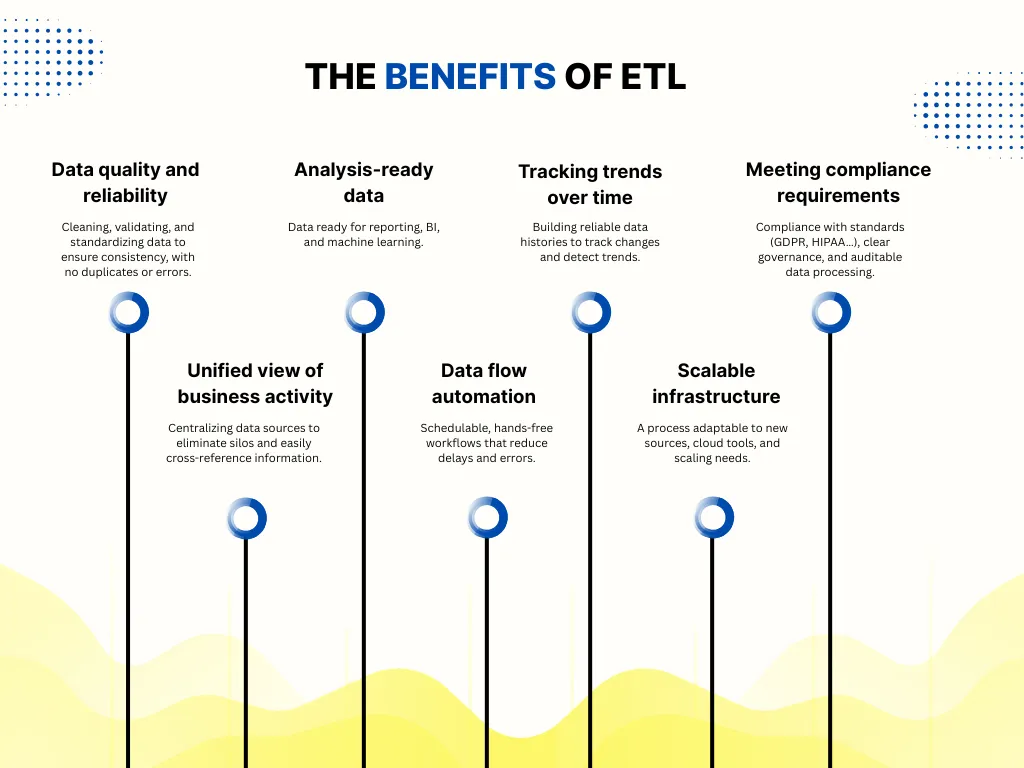
ETL ist zwar ein leistungsstarkes Tool zur Strukturierung und Bewertung von Daten, bietet aber auch eine Reihe von technische und organisatorische Herausforderungen dass es besser ist, von Anfang an zu antizipieren. Hier sind die wichtigsten Punkte, auf die Sie achten sollten.
Eine der ersten Herausforderungen besteht darin, Daten aus heterogenen Systemen verbinden und vereinheitlichen : interne Datenbanken, Cloud-Tools, CSV-Dateien, CSV-Dateien, externe APIs, verbundene Objekte... Jede Quelle hat ihre eigenen Formate, Regeln und Aktualisierungshäufigkeiten. Dies erschwert die Integration und kann Pipelines fragil machen, wenn sich Muster ändern oder wenn eine Quelle instabil wird.
Damit Daten nutzbar sind, müssen sie bereinigt, angereichert und transformiert werden. Allerdings Entwerfen Sie präzise und robuste Transformationen ist manchmal komplex:
Schlechte Einstellungen können Analysen verfälschen, sodass regelmäßige Tests und eine klare Dokumentation erforderlich sind.
Wenn das Datenvolumen zunimmt, Pipelines müssen effizient und stabil bleiben. Die Behandlungen können jedoch länger dauern, insbesondere wenn die Transformationen komplex sind oder wenn alles seriell durchgeführt wird. Es ist dann notwendig, Folgendes vorzusehen:
Ein zu Beginn gut durchdachtes ETL kann schnell schwierig zu verwalten sein, wenn:
Also musst du bieten Sie von Anfang an eine modulare, testbare und skalierbare Architektur, um nicht bei jeder Änderung alles neu aufbauen zu müssen.
Ohne Qualitätskontrolle kann eine Pipeline produzieren fehlerhafte, unvollständige oder inkonsistente Daten, mit direkten Auswirkungen auf die getroffenen Entscheidungen. Es ist daher unerlässlich, Folgendes zu integrieren:
Das klassische ETL-Modell (bei dem Daten transformiert werden, bevor sie geladen werden) kann für einige Anwendungsfälle zu langsam : Echtzeitüberwachung, dynamische Dashboards, automatische Benachrichtigungen...
In diesen Situationen müssen Sie über andere Ansätze nachdenken, wie zum Beispiel:
Nicht alle ETL-Tools haben dieselben Eigenschaften oder dieselben Verwendungszwecke. Die Wahl hängt stark von der technischen Umgebung des Unternehmens (Cloud oder vor Ort), den zu verarbeitenden Datenmengen, den Echtzeitbeschränkungen oder sogar vom verfügbaren Budget ab.
Hier sind die Vier große Familien von ETL-Tools, die heute auf dem Markt zu finden sind.
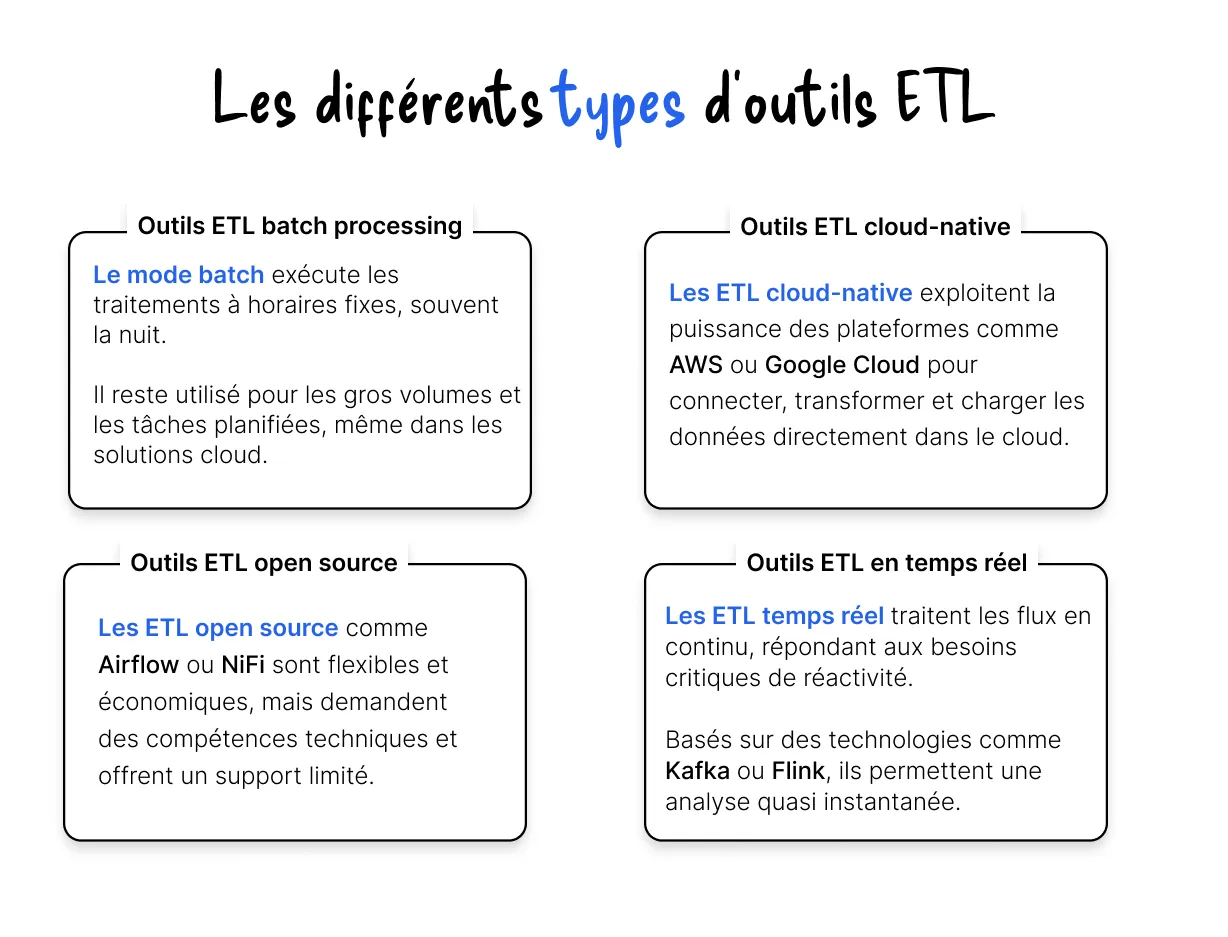
Jede Familie von ETL-Tools erfüllt unterschiedliche Anforderungen. Die Wahl eines Tools sollte sich nicht auf eine technische Frage beschränken, sondern sollte auf einer genaue Analyse des Geschäftskontextes, betriebliche Einschränkungen und die erwartete Entwicklung der Datenmengen.
Der Markt bietet inzwischen zahlreiche ETL-Tools, die von Open-Source-Lösungen bis hin zu umfassenden Geschäftsplattformen reichen.
Hier sind drei repräsentative Tools mit ergänzenden Positionen: Talend, Apache Infi und Informatica.
.webp)
Talend ist eine weit verbreitete Lösung für die Datenintegration, die in einer Open-Source-Version verfügbar ist (Talend Open Studio) und kommerziell (Talend Data Fabric).
Talend wird für seine Vielseitigkeit und seine Fähigkeit, sich an hybride Architekturen anzupassen, auch mit Data-Science-Tools, geschätzt.
.webp)
Apache NiFi ist ein Open-Source-Tool, das sich auf die Verarbeitung von Daten in einem kontinuierlichen Fluss konzentriert. Es ermöglicht die visuelle Gestaltung von Pipelines über eine intuitive Weboberfläche ohne Codierung.
NiFi eignet sich besonders für Umgebungen, in denen sofortige Reaktionsfähigkeit erforderlich ist, und bietet gleichzeitig eine hervorragende Modularität.
.webp)
Informatica PowerCenter ist eine kommerzielle Lösung, die für ihre Leistung in einer Produktionsumgebung bekannt ist. Sie basiert auf einem Motor metadatengesteuert, erleichtert die Dokumentation und Steuerung von Warenströmen
Informatica wird von großen Unternehmen für kritische Projekte bevorzugt, bei denen Robustheit und Support unerlässlich sind.
Wechseln Sie zur Dokumentenautomatisierung
Automatisieren Sie mit Koncile Ihre Extraktionen, reduzieren Sie Fehler und optimieren Sie Ihre Produktivität dank KI OCR mit wenigen Klicks.
Tristan Thommen entwirft und implementiert die technologischen Bausteine, die unstrukturierte Dokumente in nutzbare Daten umwandeln. Es kombiniert KI, OCR und Geschäftslogik, um das Leben von Teams zu vereinfachen.
Ressourcen von Koncile
Fehler und Betrug in Lieferantenrechnungen automatisch erkennen, POs und Preislisten abgleichen und versteckte Kosten senken.
Fallstudien

OmniPage vs. KI-OCR 2025: Vergleich der intelligenten und automatisierten Texterkennungslösungen
Komparative

Entdecken Sie die 10 besten KI-Agenten, die 2025 einsatzbereit sind: Stellen Sie sie in weniger als einer Woche bereit und verbessern Sie Ihre Prozesse ohne Codierung.
Komparative
.png)


